全文分为两大部分,分别是Python基础语法和面向对象。
第一部分 Python基础语法
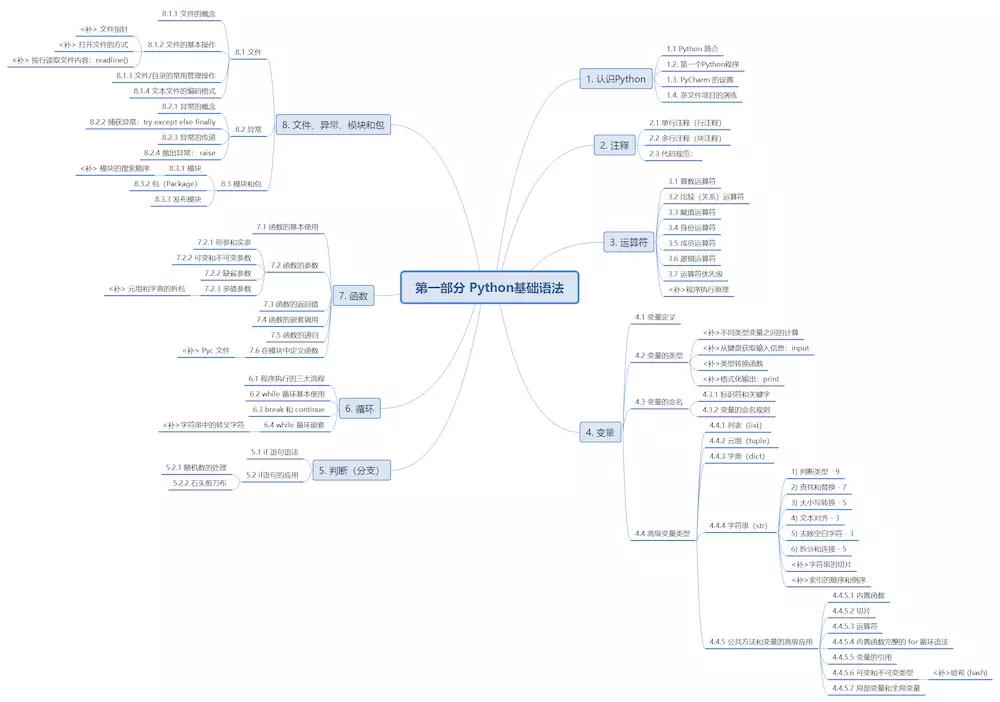
第一部分 Python基础语法
1. 认识Python
1.1 Python 简介
Python 的创始人为吉多范罗苏姆(Guido van Rossum)。
Python 的设计目标:
- 一门简单直观的语言并与主要竞争者一样强大
- 开源,以便任何人都可以为它做贡献
- 代码像纯英语那样容易理解
- 适用于短期开发的日常任务
Python 的设计哲学:
- 优雅、明确、简单
Python 开发者的哲学是: 用一种方法,最好是只有一种方法来做一件事
Python 是完全面向对象的语言,在 Python 中一切皆对象。
可扩展性:如果需要一段关键代码运行得更快或者希望某些算法不公开,可以把这部分程序用 C 或 C++ 编写,然后在 Python 程序中使用它们。
1.2. 第一个Python程序
执行 Python 程序的三种方式:
解释器、交互式运行、IDE运行
Python 是一个格式非常严格的程序设计语言。
python 2.x 默认不支持中文。
- ASCII 字符只包含 256 个字符,不支持中文
- Python 2.x 的解释器名称是 python
- Python 3.x 的解释器名称是 python3
为了照顾现有的程序,官方提供了一个过渡版本 —— Python 2.6。
提示:如果开发时,无法立即使用 Python 3.0(还有极少的第三方库不支持 3.0 的语法),建议
- 先使用 Python 3.0 版本进行开发
- 然后使用 Python 2.6、Python 2.7 来执行,并且做一些兼容性的处理
IPython 是一个 python 的 交互式 shell,比默认的 python shell 好用得多,它支持 bash shell 命令,适合于学习/验证 Python 语法或者局部代码。
集成开发环境(IDE,Integrated Development Environment)—— 集成了开发软件需要的所有工具,一般包括以下工具:
- 图形用户界面
- 代码编辑器(支持 代码补全/自动缩进)
- 编译器/解释器
- 调试器(断点/单步执行)
- ……
PyCharm 是 Python 的一款非常优秀的集成开发环境
PyCharm运行工具栏
1.3. PyCharm 的设置
PyCharm 的 配置信息 是保存在 用户家目录下 的 .PyCharmxxxx.x 目录下的,xxxx.x 表示当前使用的 PyCharm 的版本号
1.3.1 恢复 PyCharm 的初始设置:
- 关闭正在运行的 PyCharm
- 在终端中执行以下终端命令,删除 PyCharm 的配置信息目录:
$ rm -r ~/.PyCharm2016.3
- 重新启动 PyCharm
1.3.2 PyCharm 安装和启动步骤:
- 执行以下终端命令,解压缩下载后的安装包
$ tar -zxvf pycharm-professional-2017.1.3.tar.gz
- 将解压缩后的目录移动到 /opt 目录下,可以方便其他用户使用
/opt 目录用户存放给主机额外安装的软件
$ sudo mv pycharm-2017.1.3/ /opt/
- 切换工作目录
$ cd /opt/pycharm-2017.1.3/bin
- 启动 PyCharm
$ ./pycharm.sh
1.3.3 设置启动图标
- 在专业版中,选择菜单 Tools / Create Desktop Entry... 可以设置任务栏启动图标
- 注意:设置图标时,需要勾选 Create the entry for all users
- 快捷方式文件
- /usr/share/applications/jetbrains-pycharm.desktop
在 ubuntu 中,应用程序启动的快捷方式通常都保存在 /usr/share/applications 目录下
1.3.4 卸载之前版本的 PyCharm
要卸载 PyCharm 只需要做以下两步工作:
- 删除解压缩目录
$ sudo rm -r /opt/pycharm-2016.3.1/
- 删除家目录下用于保存配置信息的隐藏目录
$ rm -r ~/.PyCharm2016.3/
如果不再使用 PyCharm 还需要将 /usr/share/applications/ 下的 jetbrains-pycharm.desktop 删掉
1.4. 多文件项目的演练
- 开发 项目 就是开发一个 专门解决一个复杂业务功能的软件
- 通常每 一个项目 就具有一个 独立专属的目录,用于保存 所有和项目相关的文件
- 在 PyCharm 中,要想让哪一个 Python 程序能够执行,必须首先通过 鼠标右键的方式执行 一下
- 对于初学者而言,在一个项目中设置多个程序可以执行,是非常方便的,可以方便对不同知识点的练习和测试
- 对于商业项目而言,通常在一个项目中,只有一个 可以直接执行的 Python 源程序
让选中的程序可以执行
2. 注释
- 注释的作用
- 使用用自己熟悉的语言,在程序中对某些代码进行标注说明,增强程序的可读性
2.1 单行注释(行注释)
- 以 # 开头,# 右边的所有东西都被当做说明文字,而不是真正要执行的程序,只起到辅助说明作用
print("hello python") # 输出 `hello python`
为了保证代码的可读性,# 后面建议先添加一个空格,然后再编写相应的说明文字;为了保证代码的可读性,注释和代码之间 至少要有 两个空格。
2.2 多行注释(块注释)
- 要在 Python 程序中使用多行注释,可以用 一对 连续的 三个 引号(单引号和双引号都可以)
"""
这是一个多行注释
在多行注释之间,可以写很多很多的内容……
""" print("hello python")
提示:
- 注释不是越多越好,对于一目了然的代码,不需要添加注释
- 对于 复杂的操作,应该在操作开始前写上若干行注释
- 对于 不是一目了然的代码,应在其行尾添加注释(为了提高可读性,注释应该至少离开代码 2 个空格)
- 绝不要描述代码,假设阅读代码的人比你更懂 Python,他只是不知道你的代码要做什么
2.3 代码规范:
- Python 官方提供有一系列 PEP(Python Enhancement Proposals) 文档,其中第 8 篇文档专门针对 Python 的代码格式 原由网给出了建议,也就是俗称的 PEP 8:
- 文档地址:https://www.python.org/dev/peps/pep-0008/
- 谷歌有对应的中文文档:http://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/
3. 运算符
3.1 算数运算符
是完成基本的算术运算使用的符号,用来处理四则运算,而“+”和“*”还可以用来处理字符串。
运算符描述实例+加10 + 20 = 30-减10 - 20 = -10*乘10 * 20 = 200/除10 / 20 = 0.5//取整除返回除法的整数部分(商) 9 // 2 输出结果 4%取余数返回除法的余数 9 % 2 = 1**幂又称次方、乘方,2 ** 3 = 8
3.2 比较(关系)运算符
运算符描述==检查两个操作数的值是否 相等,如果是,则条件成立,返回 True!=检查两个操作数的值是否 不相等,如果是,则条件成立,返回 True>检查左操作数的值是否 大于 右操作数的值,如果是,则条件成立,返回 True<检查左操作数的值是否 小于 右操作数的值,如果是,则条件成立,返回 True>=检查左操作数的值是否 大于或等于 右操作数的值,如果是,则条件成立,返回 True<=检查左操作数的值是否 小于或等于 右操作数的值,如果是,则条件成立,返回 True
- Python 2.x 中判断 不等于 还可以使用 <> 运算符
- != 在 Python 2.x 中同样可以用来判断 不等于
3.3 赋值运算符
- 在 Python 中,使用 = 可以给变量赋值。在算术运算时,为了简化代码的编写,Python 还提供了一系列的 与 算术运算符 对应的 赋值运算符,注意:赋值运算符中间不能使用空格。
运算符描述实例=简单的赋值运算符c = a + b 将 a + b 的运算结果赋值为 c+=加法赋值运算符c += a 等效于 c = c + a-=减法赋值运算符c -= a 等效于 c = c - a*=乘法赋值运算符c *= a 等效于 c = c * a/=除法赋值运算符c /= a 等效于 c = c / a//=取整除赋值运算符c //= a 等效于 c = c // a%=取 模 (余数)赋值运算符c %= a 等效于 c = c % a**=幂赋值运算符c **= a 等效于 c = c ** a
3.4 身份运算符
身份运算符比较两个对象的内存位置。常用的有两个身份运算符,如下所述:
运算符描述示例is判断两个标识符是不是引用同一个对象x is y,类似 id(x) == id(y)is not判断两个标识符是不是引用不同对象x is not y,类似 id(a) != id(b)
辨析
- is 用于判断 两个变量引用的对象是否为同一个
- == 用于判断 引用变量的值 是否相等
3.5 成员运算符
Python成员运算符测试给定值是否为序列中的成员。 有两个成员运算符,如下所述:
运算符描述in如果在指定的序列中找到一个变量的值,则返回true,否则返回false。not in如果在指定序列中找不到变量的值,则返回true,否则返回false。
3.6 逻辑运算符
运算符逻辑表达式描述andx and y只有 x 和 y 的值都为 True,才会返回 True<br />否则只要 x 或者 y 有一个值为 False,就返回 Falseorx or y只要 x 或者 y 有一个值为 True,就返回 True<br />只有 x 和 y 的值都为 False,才会返回 Falsenotnot x如果 x 为 True,返回 False<br />如果 x 为 False,返回 True
3.7 运算符优先级
- 以下表格的算数优先级由高到最低顺序排列:
运算符描述**幂 (最高优先级)* / % //乘、除、取余数、取整除+ -加法、减法<= < > >=比较运算符== !=等于运算符= %= /= //= -= += *= **=赋值运算符is is not身份运算符in not in成员运算符not or and逻辑运算符
<补>程序执行原理

Python程序执行示意图
- 操作系统会首先让 CPU 把 Python 解释器 的程序复制到 内存 中
- Python 解释器 根据语法规则,从上向下 让 CPU 翻译 Python 程序中的代码
- CPU 负责执行翻译完成的代码
Python 的解释器有多大?
- 执行以下终端命令可以查看 Python 解释器的大小
# 1. 确认解释器所在位置$ which python# 2. 查看 python 文件大小(只是一个软链接)$ ls -lh /usr/bin/python# 3. 查看具体文件大小$ ls -lh /usr/bin/python2.7
4. 变量
4.1 变量定义
- 在 Python 中,每个变量 在使用前都必须赋值,变量 赋值以后 该变量 才会被创建
- 可以用 其他变量的计算结果 来定义变量
- 变量名 只有在 第一次出现 才是 定义变量
变量名 = 值
使用交互式方式,如果要查看变量内容,直接输入变量名即可,不需要使用 print 函数
使用解释器执行,如果要输出变量的内容,必须要要使用 print 函数
4.2 变量的类型
- 在 Python 中定义变量是 不需要指定类型(在其他很多高级语言中都需要),Python 可以根据 = 等号右侧的值,自动推导出变量中存储数据的类型
- 数据类型可以分为 数字型 和 非数字型
- 字符串(str):加号(+)是字符串连接运算符,星号(*)是重复运算符。
- 列表(list)
- 元组(tuple)
- 字典(dict)
- 整型 (int):Python3中的所有整数都表示为长整数。 因此,长整数没有单独的数字类型。
- 浮点型(float)
- 布尔型(bool) :真 True 非 0 数 —— 非零即真,假 False 0。
- 复数型 (complex):复数是由x + yj表示的有序对的实数浮点数组成,其中x和y是实数,j是虚数单位。
- 数字型
- 非数字型:有些运算符还支持这些数据类型,详见4.4.5.3 运算符。
提示:在 Python 2原由网.x 中, 整数 根据保存数值的长度还分为:
- int(整数)
- long(长整数)
- 使用 type 函数可以查看一个变量的类型
In [1]: type(name)
<补>不同类型变量之间的计算
- 数字型变量 之间可以直接计算
- 在 Python 中,两个数字型变量是可以直接进行 算数运算的
- 如果变量是 bool 型,在计算时
- True 对应的数字是 1
- False 对应的数字是 0
- 字符串变量 之间使用 + 拼接字符串
- 字符串变量 可以和 整数 使用 * 重复拼接相同的字符串
- 数字型变量 和 字符串 之间 不能进行其他计算
<补>从键盘获取输入信息:input
- 在 Python 中可以使用 input 函数从键盘等待用户的输入
- 用户输入的 任何内容 Python 都认为是一个 字符串
字符串变量 = input("提示信息:")
<补>类型转换函数
函数说明int(x)将 x 转换为一个整数float(x)将 x 转换到一个浮点数str(x)将对象x转换为字符串表示形式tuple(s)将s转换为元组list(s)将s转换为列表
price = float(input("请输入价格:"))
<补>格式化输出:print
- 如果希望输出文字信息的同时,一起输出 数据,就需要使用到 格式化操作符
- % 被称为 格式化操作符,专门用于处理字符串中的格式
- 包含 % 的字符串,被称为 格式化字符串
- % 和不同的 字符 连用,不同类型的数据 需要使用 不同的格式化字符
格式化字符含义%s字符串%d有符号十进制整数,%06d 表示输出的整数显示位数,不足的地方使用 0 补全%f浮点数,%.2f 表示小数点后只显示两位%%输出 %
- 语法格式如下:
print("格式化字符串" % 变量1)
print("格式化字符串" % (变量1, 变量2...))
4.3 变量的命名
4.3.1 标识符和关键字
标示符就是程序员定义的 变量名、 函数名
- 标示符可以由 字母、下划线 和 数字 组成
- 不能以数字开头
- 不能与关键字重名
关键字 就是在 Python 内部已经使用的标识符
- 关键字 具有特殊的功能和含义
- 开发者 不允许定义和关键字相同的名字的标识符
- 通过以下命令可以查看 Python 中的关键字
In [1]: import keyword
In [2]: print(keyword.kwlist)
4.3.2 变量的命名规则
命名规则 可以被视为一种 惯例,并无绝对与强制
目的是为了 增加代码的识别和可读性
注意 Python 中的 标识符 是 区分大小写的
- 在定义变量时,为了保证代码格式,= 的左右应该各保留一个空格
- 在 Python 中,如果 变量名 需要由 二个 或 多个单词 组成时,可以按照以下方式命名:每个单词都使用小写字母,单词与单词之间使用 _下划线 连接,例如:first_name、last_name、qq_number、qq_password。
当然,还有驼峰命名法:
小驼峰式命名法:第一个单词以小写字母开始,后续单词的首字母大写,例如:firstName、lastName。
大驼峰式命名法,每一个单词的首字母都采用大写字母,例如:FirstName、LastName、CamelCase 。
4.4 高级变量类型
在 Python 中,所有 非数字型变量 都支持以下特点:
1. 都是一个 序列 sequence,也可以理解为 容器
2. 取值 []
3. 遍历 for in
4. 计算长度len、最大/最小值max/min、比较、删除del
5. 链接 + 和 重复 *
6. 切片
4.4.1 列表(list)
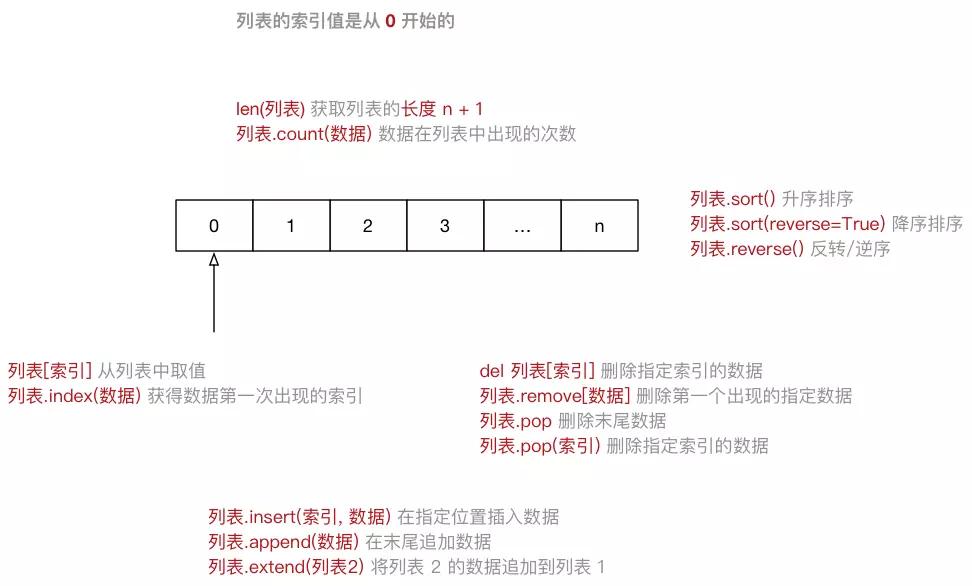
- List(列表) 是 Python 中使用 最频繁 的数据类型,在其他语言中通常叫做 数组,专门用于存储 一串 信息,列表用 [] 定义,数据 之间使用 , 分隔,列表的 索引 从 0 开始。
索引 就是数据在 列表 中的位置编号, 索引 又可以被称为 下标
注意:从列表中取值时,如果 超出索引范围,程序会报错
name_list = ["zhangsan", "lisi", "wangwu"]
列表示意图
<补>del 关键字
- 使用 del 关键字(delete) 同样可以删除列表中元素
- del 关键字本质上是用来 将一个变量从内存中删除的
- 如果使用 del 关键字将变量从内存中删除,后续的代码就不能再使用这个变量了
In [1]: l = [1,2,3,4]
In [2]: del l[1]
In [3]: l[1]
Out[3]: 3
在日常开发中,要从列表删除数据,建议 使用列表提供的方法
<补>函数与方法
- 函数 封装了独立功能,可以直接调用
函数名(参数)
函数需要死记硬背
- 方法 和函数类似,同样是封装了独立的功能
- 方法 需要通过 对象 来调用,表示针对这个 对象 要做的操作
对象.方法名(参数)
在变量后面输入 .,然后选择针对这个变量要执行的操作,记忆起来比函数要简单很多
<补>循环遍历
- 遍历 就是 从头到尾 依次 从 列表 中获取数据,在 循环体内部 针对 每一个元素,执行相同的操作。
- 在 Python 中为了提高列表的遍历效率,使用 for 就能够实现迭代遍历。
# for 循环内部使用的变量 in 列表for name in name_list:
循环内部针对列表元素进行操作
print(name)
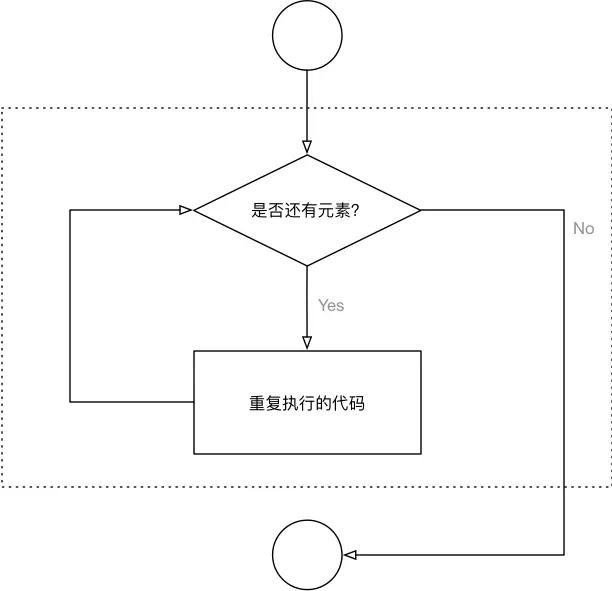
for-in循环流程图
- 尽管 Python 的 列表 中可以 存储不同类型的数据
- 但是在开发中,更多的应用场景是
- 列表 存储相同类型的数据
- 通过 迭代遍历,在循环体内部,针对列表中的每一项元素,执行相同的操作
4.4.2 元组(tuple)
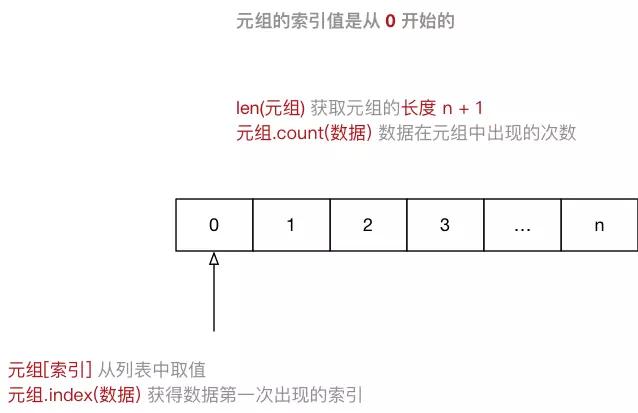
- Tuple(元组)与列表类似,不同之处在于元组的 元素不能修改
- 用于存储 一串 信息,数据 之间使用 , 分隔
- 元组 表示多个元素组成的序列
- 元组 在 Python 开发中,有特定的应用场景
- 元组用 () 定义,元组的 索引 从 0 开始,索引 就是数据在 元组 中的位置编号。
info_tuple = ("zhangsan", 18, 1.75)
创建空元组:
info_tuple = ()
元组中 只包含一个元素 时,需要 在元素后面添加逗号:
info_tuple = (50, )
元组示意图
- 在 Python 中,可以使用 for 循环遍历所有非数字型类型的变量:列表、元组、字典 以及 字符串
- 提示:在实际开发中,除非 能够确认元组中的数据类型,否则针对元组的循环遍历需求并不是很多
- 在开发中,更多的应用场景是:
- 函数的 参数 和 返回值,一个函数可以接收 任意多个参数,或者 一次返回多个数据
- 格式字符串,格式化字符串后面的 () 本质上就是一个元组
- 让列表不可以被修改,以保护数据安全
<补>元组和列表之间的转换
- 使用 list 函数可以把元组转换成列表
list(元组)
- 使用 tuple 函数可以把列表转换成元组
tuple(列表)
4.4.3 字典(dict)
dict(字典) 是 除列表以外 Python 之中 最灵活 的数据类型。
字典同样可以用来 存储多个数据,通常用于存储 描述一个 物体 的相关信息
- 和列表的区别:
- 列表 是 有序 的对象集合
- 字典 是 无序 的对象集合
- 字典用 {} 定义。
- 字典使用 键值对 存储数据,键值对之间使用逗号 , 分隔:
- 键 key 是索引
- 值 value 是数据
- 键 和 值 之间使用冒号 : 分隔
- 键必须是唯一的
- 值 可以取任何数据类型,但 键 只能使用 字符串、数字或 元组
xiaoming = {"name": "小明", "age": 18, "gender": True, "height": 1.75}
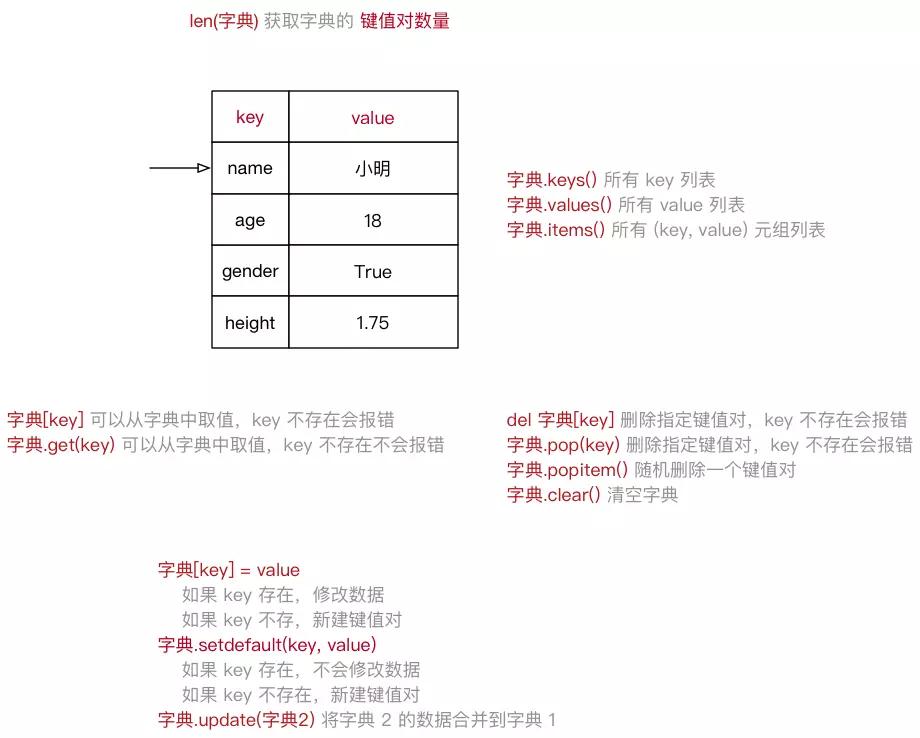
字典示意图
- 字典的遍历 就是 依次 从 字典 中获取所有键值对:
# for 循环内部使用的 `key 的变量` in 字典for k in xiaoming:
print("%s: %s" % (k, xiaoming[k]))
提示:在实际开发中,由于字典中每一个键值对保存数据的类型是不同的,所以针对字典的循环遍历需求并不是很多
- 尽管可以使用 for in 遍历 字典
- 但是在开发中,更多的应用场景是:
- 使用 多个键值对,存储 描述一个 物体 的相关信息 —— 描述更复杂的数据信息
- 将 多个字典 放www.58yuanyou.com在 一个列表 中,再进行遍历,在循环体内部针对每一个字典进行 相同的处理
card_list = [{"name": "张三", "qq": "12345", "phone": "110"},
{"name": "李四", "qq": "54321", "phone": "10086"}
]
4.4.4 字符串(str)
- 字符串 就是 一串字符,是编程语言中表示文本的数据类型
- 在 Python 中可以使用 一对双引号 " 或者 一对单引号 ' 定义一个字符串
- 如果字符串内部需要使用 ",可以使用 ' 定义字符串
- 如果字符串内部需要使用 ',可以使用 " 定义字符串
- 虽然可以使用 \" 或者 \' 做字符串的转义,但是在实际开发中:
- 可以使用 索引 获取一个字符串中 指定位置的字符,索引计数从 0 开始
- 也可以使用 for 循环遍历 字符串中每一个字符
大多数编程语言都是用 " 来定义字符串
string = "Hello Python"for c in string:
print(c)
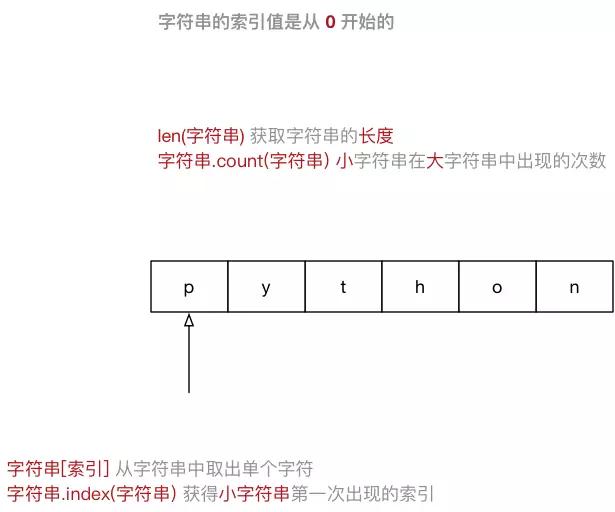
字符串示意图
提示:在 python 中对字符串操作,内置提供的方法足够多,使得在开发时,能够针对字符串进行更加灵活的操作!应对更多的开发需求!
1) 判断类型 - 9
方法说明string.isspace()如果 string 中只包含空格,则返回 Truestring.isalnum()如果 string 至少有一个字符并且所有字符都是字母或数字则返回 Truestring.isalpha()如果 string 至少有一个字符并且所有字符都是字母则返回 Truestring.isdecimal()如果 string 只包含数字则返回 True,全角数字string.isdigit()如果 string 只包含数字则返回 True,全角数字、⑴、\u00b2string.isnumeric()如果 string 只包含数字则返回 True,全角数字,汉字数字string.istitle()如果 string 是标题化的(每个单词的首字母大写)则返回 Truestring.islower()如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 Truestring.isupper()如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True
2) 查找和替换 - 7
方法说明string.startswith(str)检查字符串是否是以 str 开头,是则返回 Truestring.endswith(str)检查字符串是否是以 str 结束,是则返回 Truestring.find(str, start=0, end=len(string))检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1string.rfind(str, start=0, end=len(string))类似于 find(),不过是从右边开始查找string.index(str, start=0, end=len(string))跟 find() 方法类似,不过如果 str 不在 string 会报错string.rindex(str, start=0, end=len(string))类似于 index(),不过是从右边开始string.replace(old_str, new_str, num=string.count(old))把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次
3) 大小写转换 - 5
方法说明string.capitalize()把字符串的第一个字符大写string.title()把字符串的每个单词首字母大写string.lower()转换 string 中所有大写字符为小写string.upper()转换 string 中的小写字母为大写string.swapcase()翻转 string 中的大小写
4) 文本对齐 - 3
方法说明string.ljust(width)返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串string.rjust(width)返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串string.center(width)返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
5) 去除空白字符 - 3
方法说明string.lstrip()截掉 string 左边(开始)的空白字符string.rstrip()截掉 string 右边(末尾)的空白字符string.strip()截掉 string 左右两边的空白字符
6) 拆分和连接 - 5
方法说明string.partition(str)把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面)string.rpartition(str)类似于 partition() 方法,不过是从右边开始查找string.split(str="", num)以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 '\r', '\t', '\n' 和空格string.splitlines()按照行('\r', '\n', '\r\n')分隔,返回一个包含各行作为元素的列表string.join(seq)以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
<补>字符串的切片
- 切片 方法适用于 字符串、列表、元组
- 切片 使用 索引值 来限定范围,从一个大的 字符串 中 切出 小的 字符串
- 列表 和 元组 都是 有序 的集合,都能够 通过索引值 获取到对应的数据
- 字典 是一个 无序 的集合,是使用 键值对 保存数据
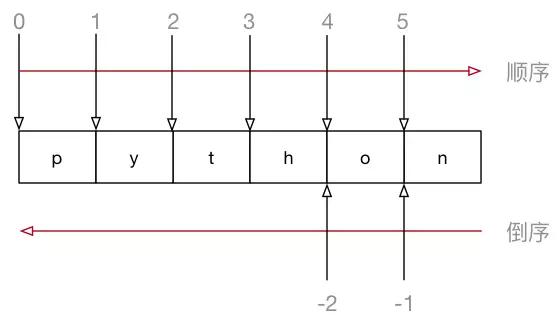
字符串索引示意图
字符串[开始索引:结束索引:步长]
注意:
- 指定的区间属于 左闭右开 型 [开始索引, 结束索引) => 开始索引 <= 范围 < 结束索引
- 从 起始 位开始,到 结束位的前一位 结束(不包含结束位本身)
- 从头开始,开始索引 数字可以省略,冒号不能省略
- 到末尾结束,结束索引 数字可以省略,冒号不能省略
- 步长默认为 1,如果连续切片,数字和冒号都可以省略
<补>索引的顺序和倒序
- 在 Python 中不仅支持 顺序索引,同时还支持 倒序索引
- 所谓倒序索引就是 从右向左 计算索引:最右边的索引值是 -1,依次递减。
num_str = "0123456789"# 1. 截取从 2 ~ 5 位置 的字符串print(num_str[2:6])# 2. 截取从 2 ~ `末尾` 的字符串print(num_str[2:])# 3. 截取从 `开始` ~ 5 位置 的字符串print(num_str[:6])# 4. 截取完整的字符串print(num_str[:])# 5. 从开始位置,每隔一个字符截取字符串print(num_str[::2])# 6. 从索引 1 开始,每隔一个取一个print(num_str[1::2])# 倒序切片# -1 表示倒数第一个字符print(num_str[-1])# 7. 截取从 2 ~ `末尾 - 1` 的字符串print(num_str[2:-1])# 8. 截取字符串末尾两个字符print(num_str[-2:])# 9. 字符串的逆序(面试题)print(num_str[::-1])
4.4.5 公共方法和变量的高级应用
4.4.5.1 内置函数
Python 包含了以下内置函数:
函数描述备注len(item)计算容器中元素个数
del(item)删除变量del 有两种方式max(item)返回容器中元素最大值如果是字典,只针对 key 比较min(item)返回容器中元素最小值如果是字典,只针对 key 比较cmp(item1, item2)比较两个值,-1 小于 / 0 相等 / 1 大于Python 3.x 取消了 cmp 函数
注意:字符串 比较符合以下规则: "0" < "A" < "a"。
4.4.5.2 切片
描述Python 表达式结果支持的数据类型切片"0123456789"[::-2]"97531"字符串、列表、元组
- 切片 使用 索引值 来限定范围,从一个大的 字符串 中 切出 小的 字符串
- 列表 和 元组 都是 有序 的集合,都能够 通过索引值 获取到对应的数据
- 字典 是一个 无序 的集合,是使用 键值对 保存数据
4.4.5.3 运算符
运算符Python 表达式结果描述支持的数据类型+[1, 2] + [3, 4][1, 2, 3, 4]合并字符串、列表、元组*["Hi!"] * 4['Hi!', 'Hi!', 'Hi!', 'Hi!']重复字符串、列表、元组in3 in (1, 2, 3)True元素是否存在字符串、列表、元组、字典not in4 not in (1, 2, 3)True元素是否不存在字符串、列表、元组、字典> >= == < <=(1, 2, 3) < (2, 2, 3)True元素比较字符串、列表、元组
注意
- in 在对 字典 操作时,判断的是 字典的键
- in 和 not in 被称为 成员运算符
4.4.5.4 内置函数完整的 for 循环语法
- 在 Python 中完整的 for 循环 的语法如下:
for 变量 in 集合:
循环体代码else:
没有通过 break 退出循环,循环结束后,会执行的代码
应用场景:
- 在 迭代遍历 嵌套的数据类型时,例如 一个列表包含了多个字典
- 需求:要判断 某一个字典中 是否存在 指定的 值
- 如果 存在,提示并且退出循环
- 如果 不存在,在 循环整体结束 后,希望 得到一个统一的提示
4.4.5.5 变量的引用
- 变量 和 数据 都是保存在 内存 中的
- 在 Python 中 函数 的 参数传递 以及 返回值 都是靠 引用 传递的
在 Python 中:变量 和 数据 是分开存储的,数据 保存在内存中的一个位置,变量 中保存着数据在内存中的地址,就叫做 引用,使用 id() 函数可以查看变量中保存数据所在的 内存地址。
注意:如果变量已经被定义,当给一个变量赋值的时候,本质上是 修改了数据的引用
- 变量 不再 对之前的数据引用
- 变量 改为 对新赋值的数据引用
在 Python 中,变量的名字类似于 便签纸 贴在 数据 上:
- 定义一个整数变量 a,并且赋值为 1
代码图示a = 1
- 将变量 a 赋值为 2
代码图示a = 2

- 定义一个整数变量 b,并且将变量 a 的值赋值给 b
代码图示b = a
在 Python 中,函数的 实参/返回值 都是是靠 引用 来传递来的
def test(num):
print("-" * 50)
print("%d 在函数内的内存地址是 %x" % (num, id(num)))
result = 100
print("返回值 %d 在内存中的地址是 %x" % (result, id(result)))
print("-" * 50) return result
a = 10print("调用函数前 内存地址是 %x" % id(a))
r = test(a)
print("调用函数后 实参内存地址是 %x" % id(a))
print("调用函数后 返回值内存地址是 %x" % id(r))
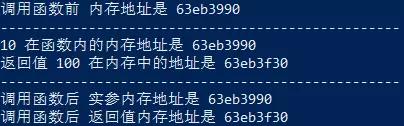
结果
4.4.5.6 可变和不可变类型
- 不可变类型,内存中的数据不允许被修改:
- 数字类型 int, bool, float, complex, long(2.x)
- 字符串 str
- 元组 tuple
- 可变类型,内存中的数据可以被修改:
- 列表 list
- 字典 dict
注意:字典的 key 只能使用不可变类型的数据
注意
- 可变类型的数据变化,是通过 方法 来实现的
- 如果给一个可变类型的变量,赋值了一个新的数据,引用会修改
- 变量 不再 对之前的数据引用
- 变量 改为 对新赋值的数据引用
<补>哈希 (hash)
- Python 中内置有一个名字叫做 hash(o) 的函数:接收一个 不可变类型 的数据作为 参数,返回 结果是一个 整数。
- 哈希 是一种 算法,其作用就是提取数据的 特征码(指纹),相同的内容 得到 相同的结果,不同的内容 得到 不同的结果。
- 在 Python 中,设置字典的 键值对 时,会首先对 key 进行 hash 已决定如何在内存中保存字典的数据,以方便 后续 对字典的操作:增、删、改、查:键值对的 key 必须是不可变类型数据,键值对的 value 可以是任意类型的数据。
4.4.5.7 局部变量和全局变量
- 局部变量 是在 函数内部 定义的变量,只能在函数内部使用;函数执行结束后,函数内部的局部变量,会被系统回收;不同的函数,可以定义相同的名字的局部变量,但是 彼此之间 不会产生影响;局部变量一般临时 保存 函数内部需要使用的数据。
- 全局变量 是在 函数外部定义 的变量(没有定义在某一个函数内),所有函数 内部 都可以使用这个变量。
提示:在其他的开发语言中,大多 不推荐使用全局变量 —— 可变范围太大,导致程序不好维护!
注意:函数执行时,需要处理变量时 会:
- 首先 查找 函数内部 是否存在 指定名称 的局部变量,如果有,直接使用
- 如果没有,查找 函数外部 是否存在 指定名称 的全局变量,如果有,直接使用
- 如果还没有,程序报错!
注意:函数不能直接修改全局变量的引用,如果要修改,必须要用global声明该变量是全局变量。
num = 10def demo1():
print("demo1" + "-" * 50) # global 关键字,告诉 Python 解释器 num 是一个全局变量
global num # 只是定义了一个局部变量,不会修改到全局变量,只是变量名相同而已
num = 100
print(num)def demo2():
print("demo2" + "-" * 50)
print(num)
demo1()
demo2()
print("over")
注意:为了避免局部变量和全局变量出现混淆,在定义全局变量时,有些公司会有一些开发要求,例如:全局变量名前应该增加 g_ 或者 gl_ 的前缀。
5. 判断(分支)
5.1 if 语句语法
1、if 判断语句基本语法:
if 要判断的条件:
条件成立时,要做的事情
……
注意:代码的缩进为一个 tab 键,或者 4 个空格 —— 建议使用空格
- 在 Python 开发中,Tab 和空格不要混用!
2、如果需要在 不满足条件的时候,做某些事情,该如何做呢?
if 要判断的条件:
条件成立时,要做的事情
……else:
条件不成立时,要做的事情
……
- 在程序开发中,通常 在判断条件时,会需要同时判断多个条件,只有多个条件都满足,才能够执行后续代码,这个时候需要使用到 逻辑运算符。
- Python 中的 逻辑运算符 包括:与 and/或 or/非 not 三种
条件1 and 条件2 :两个条件同时满足,返回 True条件1 or 条件2:两个条件只要有一个满足,返回 Truenot 条件:非,不是
3、如果希望 再增加一些条件,条件不同,需要执行的代码也不同 时,就可以使用 elif :
if 条件1:
条件1满足执行的代码
……elif 条件2:
条件2满足时,执行的代码
……elif 条件3:
条件3满足时,执行的代码
……else:
以上条件都不满足时,执行的代码
……
注意
- elif 和 else 都必须和 if 联合使用,而不能单独使用
- 可以将 if、elif 和 else 以及各自缩进的代码,看成一个 完整的代码块
4、在开发中,使用 if 进行条件判断,如果希望 在条件成立的执行语句中 再 增加条件判断,就可以使用 if 的嵌套:
if 条件 1:
条件 1 满足执行的代码
……
if 条件 1 基础上的条件 2:
条件 2 满足时,执行的代码
……
# 条件 2 不满足的处理
else:
条件 2 不满足时,执行的代码 # 条件 1 不满足的处理else:
条件1 不满足时,执行的代码
……
5.2 if语句的应用
5.2.1 随机数的处理
- 在 Python 中,要使用随机数,首先需要导入 随机数 的 模块 —— “工具包”
import random
- 导入模块后,可以直接在 模块名称 后面敲一个 . 然后按 Tab 键,会提示该模块中包含的所有函数
- random.randint(a, b) ,返回 [a, b] 之间的整数,包含 a 和 b
- 例如:
random.randint(12, 20) # 生成的随机数n: 12 <= n <= 20 random.randint(20, 20) # 结果永远是 20 random.randint(20, 10) # 该语句是错误的,下限必须小于上限
5.2.2 石头剪刀布
# 导入随机工具包# 注意:在导入工具包的时候,应该将导入的语句,放在文件的顶部# 因为,这样可以方便下方的代码,在任何需要的时候,使用工具包中的工具import random# 从控制台输入要出的拳 —— 石头(1)/剪刀(2)/布(3)player = int(input("请输入您要出的拳 石头(1)/剪刀(2)/布(3):"))# 电脑 随机 出拳 —— 先假定电脑只会出石头,完成整体代码功能computer = random.randint(1, 3)
print("玩家选择的拳头是 %d - 电脑出的拳是 %d" % (player, computer))# 比较胜负# 1 石头 胜 剪刀# 2 剪刀 胜 布# 3 布 胜 石头# if (()# or ()# or ()):if ((player == 1 and computer == 2) or (player == 2 and computer == 3) or (player == 3 and computer == 1)):
print("欧耶,电脑弱爆了!")# 平局elif player == computer:
print("真是心有灵犀啊,再来一盘")# 其他的情况就是电脑获胜else:
print("不服气,我们决战到天明!")
6. 循环
6.1 程序执行的三大流程
在程序开发中,一共有三种流程方式:
- 顺序 —— 从上向下,顺序执行代码
- 分支 —— 根据条件判断,决定执行代码的 分支
- 循环 —— 让 特定代码 重复 执行
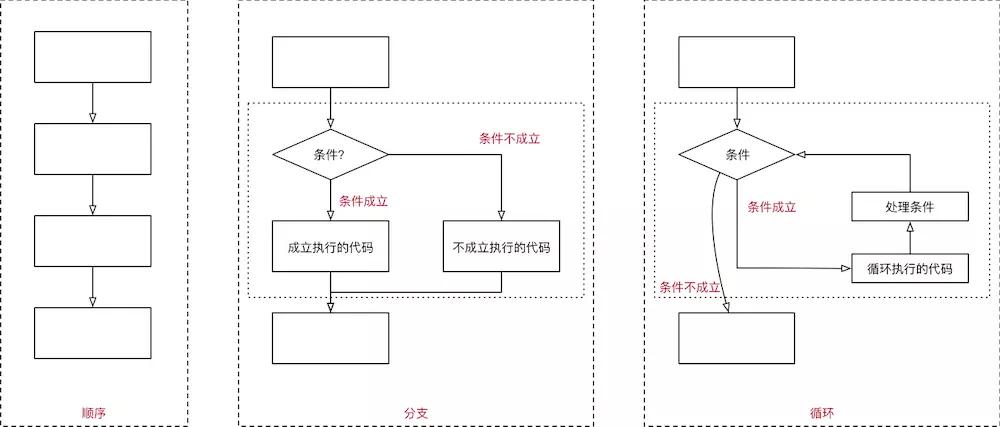
程序执行的三大流程
6.2 while 循环基本使用
while 语句基本语法:
初始条件设置 —— 通常是重复执行的 计数器while 条件(判断 计数器 是否达到 目标次数):
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
...(省略)...
处理条件(计数器 + 1)
由于程序员的原因, 忘记 在循环内部 修改循环的判断条件,导致循环持续执行,程序将陷入 死循环而无法终止!
计数器 +1 :可以通过赋值运算符简化代码的编写。
常见的计数方法有两种,可以分别称为:
- 自然计数法(从 1 开始)—— 更符合人类的习惯
- 程序计数法(从 0 开始)—— 几乎所有的程序语言都选择从 0 开始计数
因此,大家在编写程序时,应该尽量养成习惯:除非需求的特殊要求,否则 循环 的计数都从 0 开始
6.3 break 和 continue
break 和 continue 是 专门在循环中使用的关键字
- break :某一条件满足时,退出循环,不再执行后续的代码
- continue :某一条件满足时,不执行后续的代码直接进入下一次循环
- break 和 continue 只针对 当前所在循环 有效
6.4 while 循环嵌套
- while 嵌套就是:while 里面还有 while,每一次循环中还要做完一个循环。
while 条件 1:
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
...(省略)...
while 条件 2:
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
...(省略)...
处理条件 2
处理条件 1
示例:
"""
打印 9 行小星星:
*
**
***
****
*****
******
*******
********
*********
"""# 定义起始行row = 1# 最大打印 9 行while row <= 9: # 定义起始列
col = 1
# 最大打印 row 列
while col <= row: # end = "",表示输出结束后,不换行
# "\t" 可以在控制台输出一个制表符,协助在输出文本时对齐
print("%d * %d = %d" % (col, row, row * col), end="\t") # 列数 + 1
col += 1
# 一行打印完成的换行
print("") # 行数 + 1
row += 1
<补>字符串中的转义字符
- \t 在控制台输出一个 制表符,协助在输出文本时 垂直方向 保持对齐
- \n 在控制台输出一个 换行符
制表符 的功能是在不使用表格的情况下在 垂直方向 按列对齐文本
转义字符描述\\反斜杠符号\'单引号\"双引号\n换行\t横向制表符\r回车
7. 函数
7.1 函数的基本使用
所谓函数,就是把 具有独立功能的代码块 组织为一个小模块,在需要的时候 调用。在开发程序时,使用函数可以提高编写的效率以及代码的 重用,函数的使用包含两个步骤:
1. 定义函数 —— 封装 独立的功能
2. 调用函数 —— 享受 封装 的成果
- 定义函数:
def 函数名():
函数封装的代码
……
- 函数调用:通过 函数名() 即可完成对函数的调用。
PyCharm 的调试工具:
- F8 Step Over 可以单步执行代码,会把函数调用看作是一行代码直接执行
- F7 Step Into 可以单步执行代码,如果是函数,会进入函数内部
- 函数的文档注释
- 在开发中,如果希望给函数添加注释,应该在 定义函数 的下方,使用 连续的三对引号,在 连续的三对引号 之间编写对函数的说明文字,在 函数调用 位置,使用快捷键 CTRL + Q 可以查看函数的说明信息。
注意:因为 函数体相对比较独立, 函数定义的上方,应该和其他代码(包括注释)保留 两个空行
7.2 函数的参数
7.2.1 形参和实参
- 在函数名的后面的小括号内部填写 参数,多个参数之间使用逗号 , 分隔。
- 函数的参数,增加函数的 通用性,针对 相同的数据处理逻辑,能够 适应更多的数据**:
- 形参:定义 函数时,小括号中的参数,是用来接收参数用的,在函数内部 作为变量使用。
- 实参:调用 函数时,小括号中的参数,是用来把数据传递到 函数内部 用的。
def sum_2_num(num1, num2):
result = num1 + num2
print("%d + %d = %d" % (num1, num2, result))
sum_2_num(50, 20)
7.2.2 可变和不可变参数
问题 1:在函数内部,针对参数使用 赋值语句,会不会影响调用函数时传递的 实参变量? —— 不会!
- 无论传递的参数是 可变 还是 不可变
- 只要 针对参数 使用 赋值语句,会在 函数内部 修改 局部变量的引用,不会影响到 外部变量的引用
问题 2:如果传递的参数是 可变类型,在函数内部,使用 方法 修改了数据的内容, 同样会影响到外部的数据,例如列表变量调用 += 本质上是在执行列表变量的 extend 方法。
7.2.2 缺省参数
定义函数时,可以给 某个参数 指定一个默认值,具有默认值的参数就叫做 缺省参数,* 调用函数时,如果没有传入 缺省参数 的值,则在函数内部使用定义函数时指定的 参数默认值,将常见的值设置为参数的缺省值,从而 简化函数的调用。例如:对列表排序的方法:
gl_num_list = [6, 3, 9]# 默认就是升序排序,因为这种应用需求更多gl_num_list.sort()
print(gl_num_list)# 只有当需要降序排序时,才需要传递 `reverse` 参数gl_num_list.sort(reverse=True)
print(gl_num_list)
- 在参数后使用赋值语句,可以指定参数的缺省值
def print_info(name, gender=True):
gender_text = "男生"
if not gender:
gender_text = "女生"
print("%s 是 %s" % (name, gender_text))
提示
- 缺省参数,需要使用 最常见的值 作为默认值!
- 如果一个参数的值 不能确定,则不应该设置默认值,具体的数值在调用函数时,由外界传递!
注意
- 必须保证 带有默认值的缺省参数 在参数列表末尾
- 在 调用函数时,如果有 多个参数,需要指定参数名,这样解释器才能够知道参数的对应关系!
7.2.3 多值参数
有时可能需要 一个函数 能够处理的参数 个数 是不确定的,这个时候,就可以使用 多值参数。
- python 中有 两种 多值参数:
- 参数名前增加 一个 * 可以接收 元组
- 参数名前增加 两个 ** 可以接收 字典
- 一般在给多值参数命名时,习惯使用以下两个名字
- *args —— 存放 元组 参数,前面有一个 *
- **kwargs —— 存放 字典 参数,前面有两个 **
def demo(num, *args, **kwargs):
print(num)
print(args)
print(kwargs)
demo(1, 2, 3, 4, 5, name="小明", age=18, gender=True)
print("-"*20)
demo(1,(2,3,4,5),{"name":"小明", "age":18, "gender":True})
print("-"*20)
demo(1,(2,3,4,5), name="小明", age=18, gender=True)
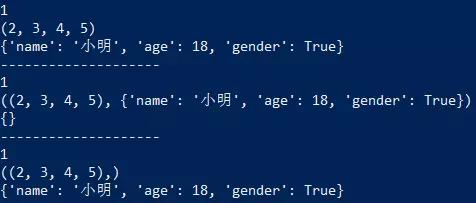
结果
<补> 元组和字典的拆包
- 在调用带有多值参数的函数时,如果希望:
- 将一个 元组变量,直接传递给 args
- 将一个 字典变量,直接传递给 kwargs
- 就可以使用 拆包,简化参数的传递,拆包 的方式是:
- 在 元组变量前,增加 一个 *
- 在 字典变量前,增加 两个 *
def demo(*args, **kwargs):
print(args)
print(kwargs)# 需要将一个元组变量/字典变量传递给函数对应的参数gl_nums = (1, 2, 3)
gl_xiaoming = {"name": "小明", "age": 18}# 会把 num_tuple 和 xiaoming 作为元组传递个 args# demo(gl_nums, gl_xiaoming)demo(*gl_nums, **gl_xiaoming)
7.3 函数的返回值
- 在函数中使用 return 关键字可以返回结果,调用函数一方,可以 使用变量 来 接收 函数的返回结果。
注意:return 表示返回,后续的代码都不会被执行
def sum_2_num(num1, num2):
"""对两个数字的求和"""
return num1 + num2# 调用函数,并使用 result 变量接收计算结果result = sum_2_num(10, 20)
print("计算结果是 %d" % result)
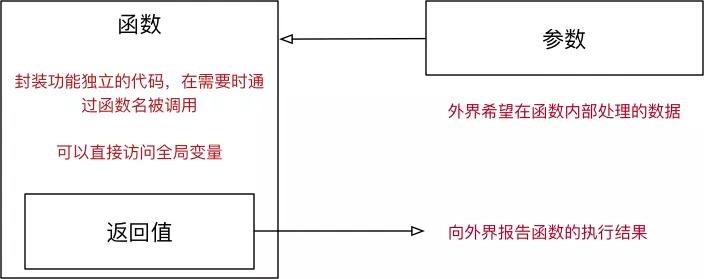
函数参数和返回值
- 在 Python 中,可以 将一个元组 使用 赋值语句 同时赋值给 多个变量
- 注意:变量的数量需要和元组中的元素数量保持一致
# Python 专有,利用元组交换两个变量的值a, b = b, a
7.4 函数的嵌套调用
- 一个函数里面 又调用 了 另外一个函数,这就是 函数嵌套调用。
def test1():
print("*" * 50)
print("test 1")
print("*" * 50)def test2():
print("-" * 50)
print("test 2")
test1()
print("-" * 50)
test2()
提示:工作中针对需求的变化,应该冷静思考, 不要轻易修改之前已经完成的,能够正常执行的函数!
7.5 函数的递归
函数调用自身的 编程技巧 称为递归
特点:一个函数 内部 调用自己
代码特点:
- 函数内部的 代码 是相同的,只是针对 参数 不同,处理的结果不同
- 当 参数满足一个条件 时,函数不再执行,通常被称为递归的出口,否则 会出现死循环!
案例 —— 计算数字累加:
需求:
- 定义一个函数 sum_num原由网bers
- 能够接收一个 num 的整数参数
- 计算 1 + 2 + ... num 的结果
def sum_numbers(num):
if num == 1: return 1
# 假设 sum_numbers 能够完成 num - 1 的累加
temp = sum_numbers(num - 1) # 函数内部的核心算法就是 两个数字的相加
return num + temp
print(sum_numbers(2))
7.6 在模块中定义函数
模块是 Python 程序架构的一个核心概念
模块 就好比是 工具包,要想使用这个工具包中的工具,就需要 导入 import 这个模块, 每一个以扩展名 py 结尾的 Python 源代码文件都是一个 模块,在模块中定义的 全局变量 、 函数 都是模块能够提供给外界直接使用的工具。
- 可以 在一个 Python 文件 中 定义 变量 或者 函数
- 然后在 另外一个文件中 使用 import 导入这个模块
- 导入之后,就可以使用 模块名.变量 / 模块名.函数 的方式,使用这个模块中定义的变量或者函数
模块可以让 曾经编写过的代码 方便的被 复用!
模块名也是一个标识符,如果在给 Python 文件起名时, 以数字开头 是无法在 PyCharm 中通过导入这个模块的。
<补> Pyc 文件
C 是 compiled 编译过 的意思。
- 浏览程序目录会发现一个 __pycache__ 的目录。
- 目录下会有一个 hm_10_分隔线模块.cpython-35.pyc 文件,cpython-35 表示 Python 解释器的版本。
- 这个 pyc 文件是由 Python 解释器将 模块的源码 转换为 字节码。
Python 这样保存 字节码 是作为一种启动 速度的优化。
- 什么是字节码?
- Python 在解释源程序时是分成两个步骤的:
- 首先处理源代码,编译 生成一个二进制 字节码。
- 再对 字节码 进行处理,才会生成 CPU 能够识别的 机器码。
- 有了模块的字节码文件之后,下一次运行程序时,如果在 上次保存字节码之后 没有修改过源代码,Python 将会加载 .pyc 文件并跳过编译这个步骤。
- 当 Python 重编译时,它会自动检查源文件和字节码文件的时间戳。
- 如果你又修改了源代码,下次程序运行时,字节码将自动重新创建。
8. 文件、异常、模块和包
8.1 文件
8.1.1 文件的概念
- 计算机的 文件,就是存储在某种 长期储存设备 上的一段 数据
- 长期存储设备包括:硬盘、U 盘、移动硬盘、光盘...
文件的作用:将数据长期保存下来,在需要的时候使用
文件的存储方式:在计算机中,文件是以 二进制 的方式保存在磁盘上的
文本文件:可以使用 文本编辑软件 查看,本质上还是二进制文件
二进制文件:保存的内容 不是给人直接阅读的,而是 提供给其他软件使用的,例如:图片文件、音频文件、视频文件等等,二进制文件不能使用 文本编辑软件 查看
8.1.2 文件的基本操作
操作文件的套路:
在 计算机 中要操作文件的套路非常固定,一共包含三个步骤:
- 打开文件
- 读、写文件
- 读 将文件内容读入内存
- 写 将内存内容写入文件
- 关闭文件
操作文件的函数/方法
在 Python 中要操作文件需要记住 1 个函数和 3 个方法
序号函数/方法说明01open打开文件,并且返回文件操作对象02read将文件内容读取到内存03write将指定内容写入文件04close关闭文件
open 函数负责打开文件,并且返回文件对象
read/write/close 三个方法都需要通过 文件对象 来调用
读取文件示例
open 函数的第一个参数是要打开的文件名(文件名区分大小写)
如果文件 存在,返回 文件操作对象
如果文件 不存在,会 抛出异常
read 方法可以一次性 读入 并 返回 文件的 所有内容
close 方法负责 关闭文件
如果 忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问
注意:read 方法执行后,会把 文件指针 移动到 文件的末尾
# 1\. 打开 - 文件名需要注意大小写file = open("README")# 2\. 读取text = file.read()print(text)# 3\. 关闭file.close()
提示
- 在开发中,通常会先编写 打开 和 关闭 的代码,再编写中间针对文件的 读/写 操作!
<补> 文件指针
- 文件指针 标记 从哪个位置开始读取数据
- 第一次打开 文件时,通常 文件指针会指向文件的开始位置
- 当执行了 read 方法后,文件指针 会移动到 读取内容的末尾
- 默认情况下会移动到 文件末尾
思考:如果执行了一次 read 方法,读取了所有内容,那么再次调用 read 方法,还能够获得到内容吗?
答案:不能!第一次读取之后,文件指针移动到了文件末尾,再次调用不会读取到任何的内容。
<补> 打开文件的方式
- open 函数默认以 只读方式 打开文件,并且返回文件对象
f = open("文件名", "访问方式")
访问方式说明r以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式。如果文件不存在,抛出异常w以只写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件a以追加方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入r+以读写方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,抛出异常w+以读写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件a+以读写方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入
提示:频繁的移动文件指针,会影响文件的读写效率,开发中更多的时候会以 只读、只写 的方式来操作文件
写入文件示例
# 打开文件f = open("README", "w")
f.write("hello python!\n")
f.write("今天天气真好")# 关闭文件f.close()
<补> 按行读取文件内容:readline()
- read 方法默认会把文件的 所有内容 一次性读取到内存
- 如果文件太大,对内存的占用会非常严重
- readline 方法可以一次读取一行内容
- 方法执行后,会把 文件指针 移动到下一行,准备再次读取
读取大文件的正确姿势
# 打开文件file = open("README")while True: # 读取一行内容
text = file.readline() # 判断是否读到内容
if not text: break
# 每读取一行的末尾已经有了一个 `\n`
print(text, end="")# 关闭文件file.close()
复制大文件
- 打开一个已有文件,逐行读取内容,并顺序写入到另外一个文件
# 1\. 打开文件file_read = open("README")
file_write = open("README[复件]", "w")# 2\. 读取并写入文件while True: # 每次读取一行
text = file_read.readline() # 判断是否读取到内容
if not text: break
file_write.write(text)# 3\. 关闭文件file_read.close()
file_write.close()
8.1.3 文件/目录的常用管理操作
- 在 终端 / 文件浏览器、 中可以执行常规的 文件 / 目录 管理操作,例如:
- 创建、重命名、删除、改变路径、查看目录内容、……
- 在 Python 中,如果希望通过程序实现上述功能,需要导入 os 模块
文件管理操作
序号方法名说明示例01rename重命名文件os.rename(源文件名, 目标文件名)02remove删除文件os.remove(文件名)
目录管理操作
序号方法名说明示例01listdir目录列表os.listdir(目录名)02mkdir创建目录os.mkdir(目录名)03rmdir删除目录os.rmdir(目录名)04getcwd获取当前目录os.getcwd()05chdir修改工作目录os.chdir(目标目录)06path.isdir判断是否是文件os.path.isdir(文件路径)
提示:文件或者目录操作都支持 相对路径 和 绝对路径
8.1.4 文本文件的编码格式
- 文本文件存储的内容是基于 字符编码 的文件,常见的编码有 ASCII 编码,UNICODE 编码等
Python 2.x 默认使用 ASCII 编码格式
Python 3.x 默认使用 UTF-8 编码格式
ASCII 编码
- 计算机中只有 256 个 ASCII 字符
- 一个 ASCII 在内存中占用 1 个字节 的空间
- 8 个 0/1 的排列组合方式一共有 256 种,也就是 2 ** 8
UTF-8 编码格式
- 计算机中使用 1~6 个字节 来表示一个 UTF-8 字符,涵盖了 地球上几乎所有地区的文字
- 大多数汉字会使用 3 个字节 表示
- UTF-8 是 UNICODE 编码的一种编码格式
Ptyhon 2.x 中如何使用中文?
- 在 Python 2.x 文件的 第一行 增加代码# *-* coding:utf8 *-*,解释器会以 utf-8 编码来处理 python 文件,这方式是官方推荐使用的!
- 也可以使用# coding=utf8。
Python 2.x 中如何正确遍历 unicode 字符串?
- 在 Python 2.x 中,即使指定了文件使用 UTF-8 的编码格式,但是在遍历字符串时,仍然会 以字节为单位遍历 字符串
- 要能够 正确的遍历字符串,在定义字符串时, 在字符串的引号前,增加一个小写字母 u,告诉解释器这是一个 unicode 字符串(使用 UTF-8 编码格式的字符串)
# *-* coding:utf8 *-*# 在字符串前,增加一个 `u` 表示这个字符串是一个 utf8 字符串hello_str = u"你好世界"print(hello_str)for c in hello_str:
print(c)
8.2 异常
8.2.1 异常的概念
- 程序在运行时,如果 Python 解释器 遇到 到一个错误,会停止程序的执行,并且提示一些错误信息,这就是 异常
- 程序停止执行并且提示错误信息 这个动作,我们通常称之为:抛出(raise)异常
程序开发时,很难将 所有的特殊情况 都处理的面面俱到,通过 异常捕获 可以针对突发事件做集中的处理,从而保证程序的 稳定性和健壮性
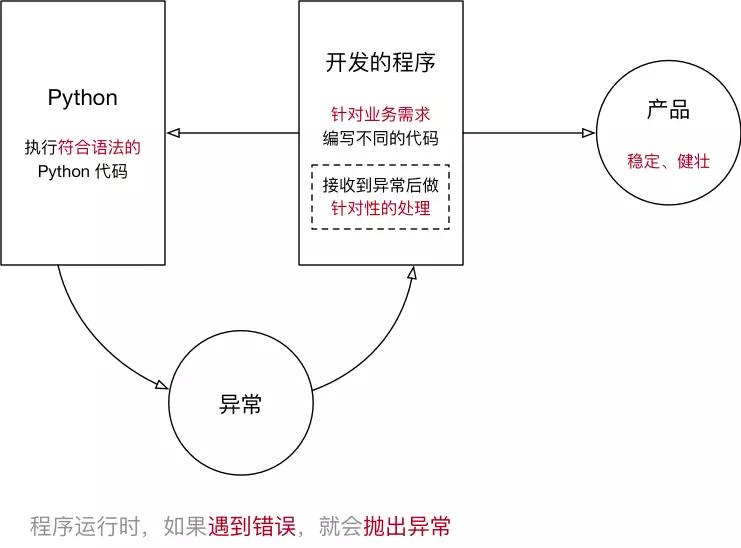
8.2.2 捕获异常:try except else finally
简单的捕获异常语法
- 在程序开发中,如果 对某些代码的执行不能确定是否正确,可以增加 try(尝试) 来 捕获异常
try:
尝试执行的代码except:
出现错误的处理
- try 尝试,下方编写要尝试代码,不确定是否能够正常执行的代码
- except 如果不是,下方编写尝试失败的代码
简单异常捕获1 —— 要求用户输入整数
try: # 提示用户输入一个数字
num = int(input("请输入数字:"))except:
print("请输入正确的数字")
错误类型捕获
- 在程序执行时,可能会遇到 不同类型的异常,并且需要 针对不同类型的异常,做出不同的响应,这个时候,就需要捕获错误类型了
try: # 尝试执行的代码
passexcept 错误类型1: # 针对错误类型1,对应的代码处理
passexcept (错误类型2, 错误类型3): # 针对错误类型2 和 3,对应的代码处理
passexcept Exception as result:
print("未知错误 %s" % result)
- 当 Python 解释器 抛出异常 时,最后一行错误信息的第一个单词,就是错误类型
异常类型捕获2 —— 要求用户输入整数
try:
num = int(input("请输入整数:"))
result = 8 / num
print(result)except ValueError:
print("请输入正确的整数")except ZeroDivisi:
print("除 0 错误")
捕获未知错误
- 在开发时,要预判到所有可能出现的错误,还是有一定难度的
- 如果希望程序 无论出现任何错误,都不会因为 Python 解释器 抛出异常而被终止,可以再增加一个 except
语法如下:
except Exception as result: print("未知错误 %s" % result)
异常捕获完整语法
- 在实际开发中,为了能够处理复杂的异常情况,完整的异常语法如下:
try: # 尝试执行的代码
passexcept 错误类型1: # 针对错误类型1,对应的代码处理
passexcept 错误类型2: # 针对错误类型2,对应的代码处理
passexcept (错误类型3, 错误类型4): # 针对错误类型3 和 4,对应的代码处理
passexcept Exception as result: # 打印错误信息
print(result)else: # 没有异常才会执行的代码
passfinally: # 无论是否有异常,都会执行的代码
print("无论是否有异常,都会执行的代码")
- else 只有在没有异常时才会执行的代码
- finally 无论是否有异常,都会执行的代码
- 之前一个演练的 完整捕获异常 的代码如下:
try:
num = int(input("请输入整数:"))
result = 8 / num
print(result)except ValueError:
print("请输入正确的整数")except ZeroDivisi:
print("除 0 错误")except Exception as result:
print("未知错误 %s" % result)else:
print("正常执行")finally:
print("执行完成,但是不保证正确")
8.2.3 异常的传递
- 异常的传递 —— 当 函数/方法 执行 出现异常,会 将异常传递 给 函数/方法 的 调用一方
- 如果 传递到主程序,仍然 没有异常处理,程序才会被终止
提示:
- 在开发中,可以在主函数中增加 异常捕获,而在主函数中调用的其他函数,只要出现异常,都会传递到主函数的异常捕获中
- 这样就不需要在代码中,增加大量的异常捕获,能够保证代码的整洁
'''
需求:
1. 定义函数 `demo1()` **提示用户输入一个整数并且返回**
2. 定义函数 `demo2()` 调用 `demo1()`
3. 在主程序中调用 `demo2()`
'''def demo1():
return int(input("请输入一个整数:"))def demo2():
return demo1()try:
print(demo2())except ValueError:
print("请输入正确的整数")except Exception as result:
print("未知错误 %s" % result)
8.2.4 抛出异常: raise
应用场景
- 在开发中,除了 代码执行出错 Python 解释器会 抛出 异常之外
- 还可以根据 应用程序 特有的业务需求 主动抛出异常
示例
- 提示用户 输入密码,如果 长度少于 8,抛出 异常
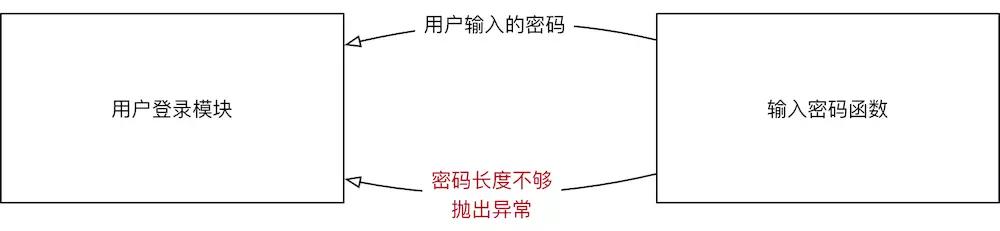
抛出异常
- Python 中提供了一个 Exception 异常类
- 在开发时,如果满足 特定业务需求时,希望 抛出异常,由其他需要处理的函数捕获异常,可以:
- 创建 一个 Exception 的 对象
- 使用 raise 关键字 抛出 异常对象
'''
**需求**
* 定义 `input_password` 函数,提示用户输入密码
* 如果用户输入长度 < 8,抛出异常
* 如果用户输入长度 >=8,返回输入的密码
'''def input_password():
# 1\. 提示用户输入密码
pwd = input("请输入密码:") # 2\. 判断密码长度,如果长度 >= 8,返回用户输入的密码
if len(pwd) >= 8: return pwd # 3\. 密码长度不够,需要抛出异常
# 1> 创建异常对象 - 使用异常的错误信息字符串作为参数
ex = Exception("密码长度不够") # 2> 抛出异常对象
raise extry:
user_pwd = input_password()
print(user_pwd)except Exception as result:
print("发现错误:%s" % result)
8.3 模块和包
8.3.1 模块
模块是 Python 程序架构的一个核心概念
- 每一个以扩展名 py 结尾的 Python 源代码文件都是一个 模块
- 模块名 同样也是一个 标识符,需要符合标识符的命名规则
- 在模块中定义的 全局变量 、函数、类 都是提供给外界直接使用的 工具
- 模块 就好比是 工具包,要想使用这个工具包中的工具,就需要先 导入 这个模块
模块的两种导入方式
1)import 导入
import 模块名1, 模块名2
提示:在导入模块时,每个导入应该独占一行
import 模块名1import 模块名2
- 导入之后
- 通过 模块名. 使用 模块提供的工具 —— 全局变量、函数、类
- 使用 as 指定模块的别名
如果模块的名字太长,可以使用 as 指定模块的名称,以方便在代码中的使用
import 模块名1 as 模块别名
注意: 模块别名 应该符合 大驼峰命名法
2)from...import 导入
- 如果希望 从某一个模块 中,导入 部分 工具,就可以使用 from ... import 的方式
- import 模块名 是 一次性 把模块中 所有工具全部导入,并且通过 模块名/别名 访问
# 从 模块 导入 某一个工具from 模块名1 import 工具名
- 导入之后
- 可以直接使用 模块提供的工具 —— 全局变量、函数、类
注意
如果 两个模块,存在 同名的函数,那么 后导入模块的函数,会 覆盖掉先导入的函数
- 开发时 import 代码应该统一写在 代码的顶部,更容易及时发现冲突
- 一旦发现冲突,可以使用 as 关键字 给其中一个工具起一个别名
- from...import *
# 从 模块 导入 所有工具from 模块名1 import *
注意
这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查
<补> 模块的搜索顺序
Python 的解释器在 导入模块 时,会:
- 搜索 当前目录 指定模块名的文件,如果有就直接导入
- 如果没有,再搜索 系统目录
在开发时,给文件起名,不要和 系统的模块文件 重名
Python 中每一个模块都有一个内置属性 __file__ 可以 查看模块 的 完整路径
原则 —— 每一个文件都应该是可以被导入的
- 一个 独立的 Python 文件 就是一个 模块
- 在导入文件时,文件中 所有没有任何缩进的代码 都会被执行一遍!
实际开发场景
- 在实际开发中,每一个模块都是独立开发的,大多都有专人负责
- 开发人员 通常会在 模块下方 增加一些测试代码
- 仅在模块内使用,而被导入到其他文件中不需要执行
__name__ 属性
- __name__ 属性可以做到,测试模块的代码 只在测试情况下被运行,而在 被导入时不会被执行!
- __name__ 是 Python 的一个内置属性,记录着一个 字符串
- 如果 是被其他文件导入的,__name__ 就是 模块名
- 如果 是当前执行的程序 __name__ 是 __main__
在很多 Python 文件中都会看到以下格式的代码:
# 导入模块# 定义全局变量# 定义类# 定义函数# 在代码的最下方def main():
# ...
pass# 根据 __name__ 判断是否执行下方代码if __name__ == "__main__":
main()
8.3.2 包(Package)
- 包 是一个 包含多个模块 的 特殊目录
- 目录下有一个 特殊的文件 __init__.py
- 包名的 命名方式 和变量名一致,小写字母 + _
好处:使用 import 包名 可以一次性导入 包 中 所有的模块
案例
- 新建一个 hm_message 的 包
- 在目录下,新建两个文件 send_message 和 receive_message
- 在 send_message 文件中定义一个 send 函数
- 在 receive_message 文件中定义一个 receive 函数
- 在外部直接导入 hm_message 的包
__init__.py
- 要在外界使用 包 中的模块,需要在 __init__.py 中指定 对外界提供的模块列表
# 从 当前目录 导入 模块列表from . import send_messagefrom . import receive_message
8.3.3 发布模块
- 如果希望自己开发的模块,分享 给其他人,可以按照以下步骤操作:
- 创建 setup.py
- setup.py 的文件
from distutils.core import setup
setup(name="hm_message", # 包名
version="1.0", # 版本
deion="itheima's 发送和接收消息模块", # 描述信息
long_deion="完整的发送和接收消息模块", # 完整描述信息
author="itheima", # 作者
author_email="itheima@itheima.com", # 作者邮箱
url="www.itheima.com", # 主页
py_modules=["hm_message.send_message", "hm_message.receive_message"])
有关字典参数的详细信息,可以参阅官方网站:https://docs.python.org/2/distutils/apiref.html
- 构建模块
$ python3 setup.py build
- 生成发布压缩包
$ python3 setup.py sdist
注意:要制作哪个版本的模块,就使用哪个版本的解释器执行!
4)安装模块
$ tar -zxvf hm_message-1.0.tar.gz
$ sudo python3 setup.py install
5)卸载模块
直接从安装目录下,把安装模块的 目录 删除就可以
$ cd /usr/local/lib/python3.5/dist-packages/
$ sudo rm -r hm_message*
pip 安装第三方模块
- 第三方模块 通常是指由 知名的第三方团队 开发的 并且被 程序员广泛使用 的 Python 包 / 模块
- 例如 pygame 就是一套非常成熟的 游戏开发模块
- pip 是一个现代的,通用的 Python 包管理工具
- 提供了对 Python 包的查找、下载、安装、卸载等功能
安装和卸载命令如下:
# 将模块安装到 Python 2.x 环境$ sudo pip install pygame
$ sudo pip uninstall pygame# 将模块安装到 Python 3.x 环境$ sudo pip3 install pygame
$ sudo pip3 uninstall pygame
第二部分 面向对象
第二部分 面向对象
1. 面向对象(OOP)基本概念
面向对象编程 —— Object Oriented Programming 简写 OOP
- 面向过程 —— 怎么做?
- 把完成某一个需求的 所有步骤 从头到尾 逐步实现
- 根据开发需求,将某些 功能独立 的代码 封装 成一个又一个 函数
- 最后完成的代码,就是顺序地调用 不同的函数
- 特点:
- 注重 步骤与过程,不注重职责分工
- 如果需求复杂,代码会变得很复杂
- 开发复杂项目,没有固定的套路,开发难度很大!
- 面向对象 —— 谁来做?
相比较函数,面向对象 是更大的封装,根据职责在 一个对象中封装多个方法
- 在完成某一个需求前,首先确定 职责 —— 要做的事情(方法)
- 根据 职责 确定不同的 对象,在 对象 内部封装不同的 方法(多个)
- 最后完成的代码,就是顺序地让 不同的对象 调用 不同的方法
- 特点:
- 注重 对象和职责,不同的对象承担不同的职责
- 更加适合应对复杂的需求变化,是专门应对复杂项目开发,提供的固定套路
- 需要在面向过程基础上,再学习一些面向对象的语法
- 类名 这类事物的名字,满足大驼峰命名法
- 属性 这类事物具有什么样的特征
- 方法 这类事物具有什么样的行为
- 类和对象
- 类 是对一群具有 相同 特征 或者 行为 的事物的一个统称,是抽象的,特征 被称为 属性,行为 被称为 方法。
- 对象 是 由类创建出来的一个具体存在,是类的实例化。
- 在程序开发中,要设计一个类,通常需要满足一下三个要素:
2. 面向对象基础语法
2.1 dir 内置函数和内置方法
在 Python 中 对象几乎是无所不在的,我们之前学习的 变量、数据、函数 都是对象。
在 Python 中可以使用以下两个方法验证:
- 在 标识符 / 数据 后输入一个点 .,然后按下 TAB 键,iPython 会提示该对象能够调用的方法列表。
- 使用内置函数 dir 传入 标识符 / 数据,可以查看对象内的 所有属性及方法。
- 提示__方法名__格式的方法是 Python 提供的 内置方法 / 属性。
序号方法名类型作用01__new__方法创建对象时,会被 自动 调用02__init__方法对象被初始化时,会被 自动 调用03__del__方法对象被从内存中销毁前,会被 自动 调用04__str__方法返回对象的描述信息,print 函数输出使用
提示 利用好 dir() 函数,在学习时很多内容就不需要死记硬背了。
2.2 定义简单的类(只包含方法)
面向对象是更大的封装,在 一个类中封装多个方法,这样通过这个类创建出来的对象,就可以直接调用这些方法了!
定义一个只包含方法的类:
class 类名:
def 方法1(self, 参数列表):
pass
def 方法2(self, 参数列表):
pass
方法 的定义格式和之前学习过的函数几乎一样,区别在于第一个参数必须是 self。
注意:类名 的 命名规则 要符合 大驼峰命名法。
当一个类定义完成之后,要使用这个类来创建对象,语法格式如下:
对象变量 = 类名()
在面向对象开发中,引用的概念是同样适用的!
使用 print输出 对象变量,默认情况下,是能够输出这个变量 引用的对象 是 由哪一个类创建的对象,以及 在内存中的地址(十六进制表示)。
提示:在计算机中,通常使用 十六进制 表示 内存地址。
如果在开发中,希望使用 print输出 对象变量 时,能够打印 自定义的内容,就可以利用 __str__这个内置方法了:
class Cat:
def __init__(self, new_name):
self.name = new_name
print("%s 来了" % self.name) def __del__(self):
print("%s 去了" % self.name) def __str__(self):
return "我是小猫:%s" % self.name
tom = Cat("Tom")
print(tom)
注意:__str__方法必须返回一个字符串。
2.3 方法中的 self 参数
在 Python 中,要 给对象设置属性,非常的容易,只需要在 类的外部的代码 中直接通过 对象.设置一个属性即可,但是不推荐使用:
class Cat:
"""这是一个猫类"""
def eat(self):
print("小猫爱吃鱼") def drink(self):
print("小猫在喝水")
tom = Cat()# 给对象设置属性tom.name = "Tom"
因为:对象属性的封装应该封装在类的内部
由哪一个对象调用的方法,方法内的 self就是哪一个对象的引用
- 在类封装的方法内部,self 就表示当前调用方法的对象自己,在方法内部:
- 可以通过 self.访问对象的属性,也可以通过 self.调用对象的其他方法。
- 调用方法时,程序员不需要传递 self 参数。
- 在 类的外部,通过变量名.访问对象的 属性和方法
- 在 类封装的方法中,通过 self.访问对象的 属性和方法
2.4 初始化方法:__init__
- 当使用 类名() 创建对象时,会 自动 执行以下操作:
- 为对象在内存中分配空间 —— 创建对象
- 为对象的属性设置初始值 —— 初始化方法(__init__)
__init__ 方法是 专门 用来定义一个类具有哪些 属性的方法!
- 在 __init__ 方法内部使用 self.属性名 = 属性的初始值 就可以定义属性,定义属性之后,再使用 类创建的对象,都会拥有该属性。
- 在开发中,如果希望在 创建对象的同时,就设置对象的属性,可以对 __init__ 方法进行 改造:
- 把希望设置的属性值,定义成 __init__方法的参数
- 在方法内部使用 self.属性 = 形参 接收外部传递的参数
- 在创建对象时,使用 类名(属性1, 属性2...) 调用
class Cat:
def __init__(self, name):
print("初始化方法 %s" % name)
self.name = name
...
tom = Cat("Tom")
...
lazy_cat = Cat("大懒猫")
...
2.5 私有属性和私有方法
应用场景
- 在实际开发中,对象 的 某些属性或方法 可能只希望 在对象的内部被使用,而 不希望在外部被访问到
- 私有属性 就是 对象 不希望公开的 属性
- 私有方法 就是 对象 不希望公开的 方法
定义方式
- 在 定义属性或方法时,在 属性名或者方法名前 增加 两个下划线,定义的就是 私有 属性或方法:

私有属性和私有方法
伪私有属性和私有方法
Python 中,并没有 真正意义 的 私有
在给 属性、方法 命名时,实际是对名称做了一些特殊处理,使得外界无法访问到
处理方式:在 名称 前面加上_类名 => _类名__名称
# 私有属性,外部不能直接访问到print(xiaofang._Women__age)# 私有方法,外部不能直接调用xiaofang._Women__secret()
提示:在日常开发中,不要使用这种方式,访问对象的 私有属性 或 私有方法。
3. 封装、继承和多态
面向对象三大特性:
- 封装 根据 职责 将 属性 和 方法 封装 到一个抽象的 类 中
- 继承 实现代码的重用,相同的代码不需要重复的编写
- 多态 不同的对象调用相同的方法,产生不同的执行结果,增加代码的灵活度
3.1 继承
3.1.1 单继承
继承的概念:子类 拥有 父类 以及 父类的父类 中封装的所有 属性 和 方法。
class 类名(父类名):
pass
当 父类 的方法实现不能满足子类需求时,可以对方法进行重写(override)
重写 父类方法有两种情况:
- 覆盖 父类的方法:父类的方法实现 和 子类的方法实现完全不同
- 具体的实现方式,就相当于在 子类中 定义了一个 和父类同名的方法并且实现。
- 对父类方法进行 扩展:子类的方法实现 中 包含 父类的方法实现
- 在子类中 重写 父类的方法;在需要的位置使用 super().父类方法 来调用父类方法的执行代码;其他的位置针对子类的需求,编写 子类特有的代码实现。
关于 super
- 在 Python 中 super 是一个 特殊的类
- super()就是使用 super 类创建出来的对象
- 最常 使用的场景就是在 重写父类方法时,调用 在父类中封装的方法实现
调用父类方法的另外一种方式:在 Python 2.x 时,如果需要调用父类的方法,还可以使用以下方式:父类名.方法(self)。目前在 Python 3.x 还支持这种方式,但不推荐使用,因为一旦 父类发生变化,方法调用位置的 类名 同样需要修改。
父类的 私有属性 和 私有方法
子类对象 不能 在自己的方法内部,直接 访问 父类的 私有属性 或 私有方法
子类对象 可以通过 父类 的 公有方法 间接 访问到 私有属性 或 私有方法
- 私有属性、方法 是对象的隐私,不对外公开,外界 以及 子类 都不能直接访问
- 私有属性、方法 通常用于做一些内部的事情
3.1.2 多继承
子类 可以拥有 多个父类,并且具有 所有父类 的 属性 和 方法,例如:孩子 会继承自己 父亲 和 母亲 的 特性。
class 子类名(父类名1, 父类名2...):
pass
Python 中的 MRO算法(Method Resolution Order)
- 如果 不同的父类 中存在 同名的方法,子类对象 在调用方法时,会调用 哪一个父类中的方法呢?
- 提示:开发时,应该尽量避免这种容易产生混淆的情况! —— 如果 父类之间 存在 同名的属性或者方法,应该 尽量避免使用多继承。
- Python 中针对 类 提供了一个 内置属性__mro__ 可以查看 方法 搜索顺序
- 在搜索方法时,是按照 mro 的输出结果 从左至右 的顺序查找的
- 如果在当前类中 找到方法,就直接执行,不再搜索
- 如果 没有找到,就查找下一个类 中是否有对应的方法,如果找到,就直接执行,不再搜索
- 如果找到最后一个类,还没有找到方法,程序报错
MRO 是 method resolution order —— 方法搜索顺序,主要用于 在多继承时判断 方法、属性 的调用 路径
新式类与旧式(经典)类
- 新式类:以 object 为基类的类,推荐使用
- 经典类:不以 object为基类的类,不推荐使用
在 Python 3.x 中定义类时,如果没有指定父类,会 默认使用 object作为该类的 基类 —— Python 3.x 中定义的类都是 新式类,在 Python 2.x 中定义类时,如果没有指定父类,则不会以 object 作为 基类。
- 为了保证编写的代码能够同时在 Python 2.x 和 Python 3.x 运行!今后在定义类时,如果没有父类,建议统一继承自 object:
class 类名(object):
pass
object 是 Python 为所有对象提供的 基类,提供有一些内置的属性和方法,可以使用 dir(object) 函数查看。
3.2 多态
面向对象三大特性:
- 封装 根据 职责 将 属性 和 方法 封装 到一个抽象的 类 中
- 定义类的准则
- 继承 实现代码的重用,相同的代码不需要重复的编写
- 设计类的技巧
- 子类针对自己特有的需求,编写特定的代码
- 多态 不同的 子类对象 调用相同的 父类方法,产生不同的执行结果
- 增加代码的灵活度
- 以 继承 和 重写父类方法 为前提
- 调用方法的技巧,不会影响到类的内部设计
多态 更容易编写出出通用的代码,做出通用的编程,以适应需求的不断变化!
案例:
在 Dog 类中封装方法 game:普通狗只是简单的玩耍
定义 XiaoTianDog 继承自 Dog,并且重写 game 方法:哮天犬需要在天上玩耍
定义 Person 类,并且封装一个 和狗玩 的方法:在方法内部,直接让 狗对象 调用 game 方法
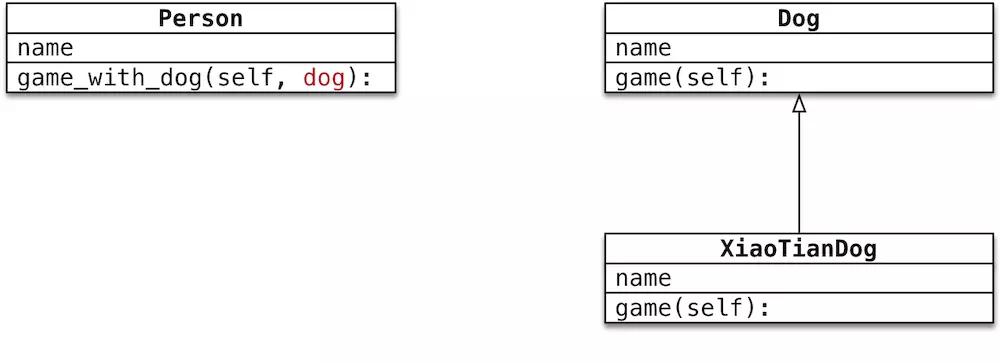
多态示例
Person 类中只需要让 狗对象 调用 game 方法,而不关心具体是 什么狗。
4. 类属性和类方法
4.1 类的结构
通常会把:
创建出来的 对象 叫做 类的实例
创建对象的 动作 叫做 实例化
对象的属性 叫做 实例属性
对象调用的方法 叫做 实例方法
每一个对象 都有自己独立的内存空间,保存各自不同的属性
多个对象的方法,在内存中只有一份,在调用方法时,需要把对象的引用传递到方法内部
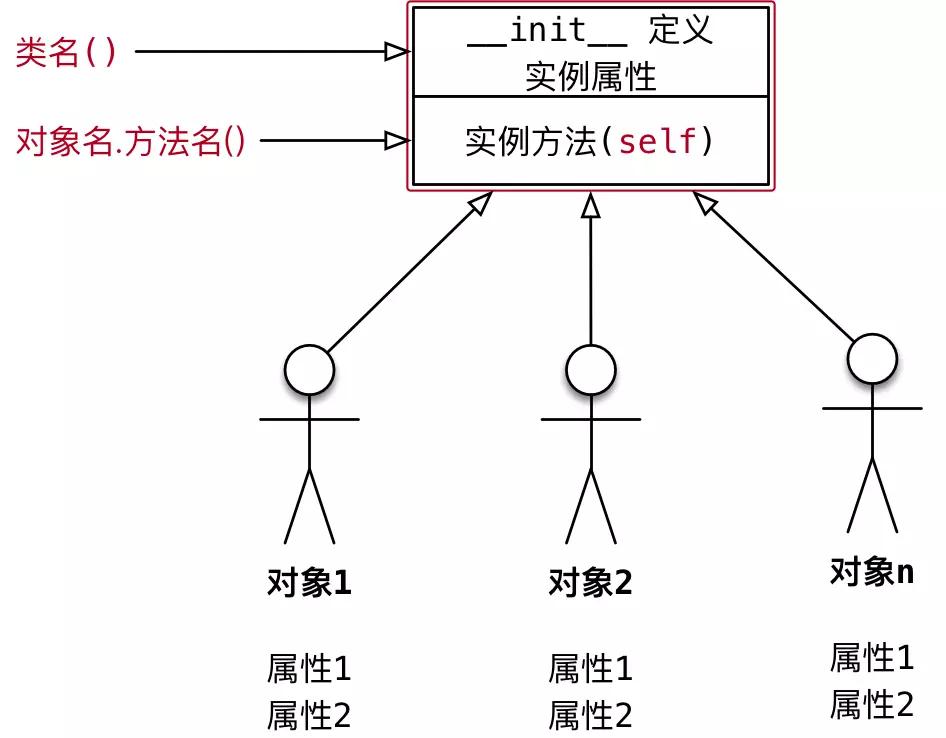
各个不同的属性,独一份的方法
在 Python 中,类是一个特殊的对象。
Python 中 一切皆对象:
- class AAA: 定义的类属于 类对象
- obj1 = AAA() 属于 实例对象
在程序运行时,类同样会被加载到内存
在程序运行时,类对象在内存中只有一份,使用 一个类可以创建出很多个对象实例
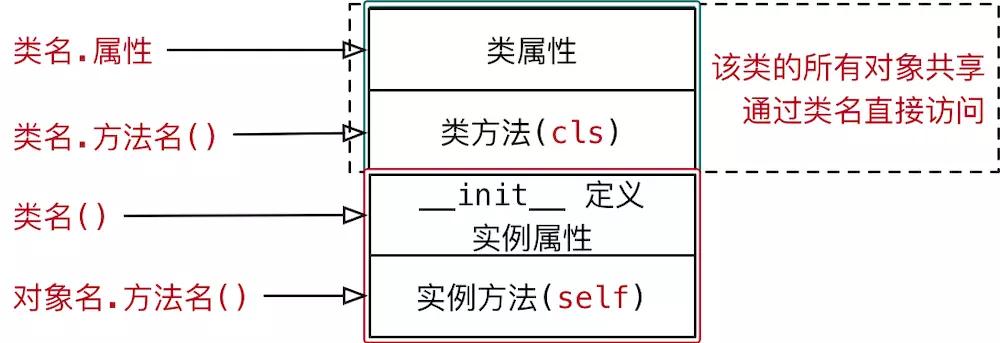
除了封装实例的属性和方法外,类对象还可以拥有自己的属性和方法——类属性、类方法,通过 类名. 的方式可以 访问类的属性 或者 调用类的方法
类的结构
4.2 类属性和实例属性
类属性 就是 类对象中定义的属性
通常用来记录与这个类相关的特征
类属性不会用于记录具体对象的特征
示例:
定义一个 工具类,每件工具都有自己的 name:
需求 —— 知道使用这个类,创建了多少个工具对象?
class Tool(object):
# 使用赋值语句,定义类属性,记录创建工具对象的总数
count = 0
def __init__(self, name):
self.name = name # 针对类属性做一个计数+1
Tool.count += 1# 创建工具对象tool1 = Tool("斧头")
tool2 = Tool("榔头")
tool3 = Tool("铁锹")# 知道使用 Tool 类到底创建了多少个对象?print("现在创建了 %d 个工具" % Tool.count)
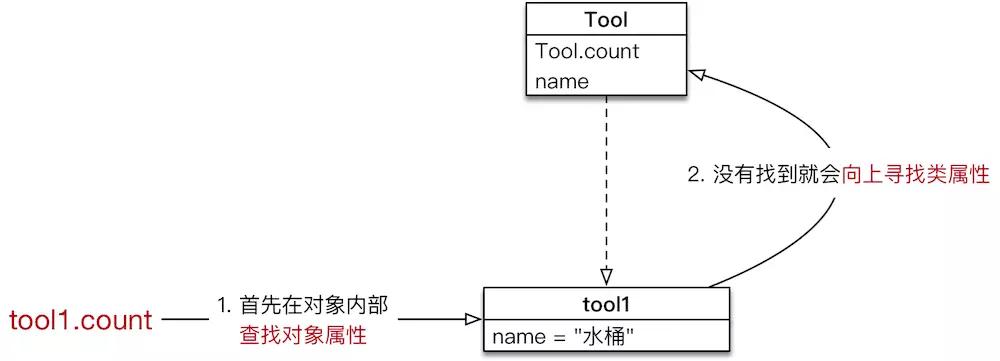
属性的获取机制
在 Python 中 属性的获取 存在一个 向上查找机制
因此,要访问类属性有两种方式:
- 类名.类属性
- 对象.类属性 (不推荐,因为如果使用 对象.类属性 = 值 赋值语句,只会给对象添加一个属性,而不会影响到类属性的值)
4.3 类方法和静态方法
4.3.1 类方法
- 类属性 就是针对 类对象 定义的属性
- 使用 赋值语句 在 class 关键字下方可以定义 类属性
- 类属性 用于记录 与这个类相关 的特征
- 类方法 就是针对 类对象 定义的方法
- 在 类方法 内部可以直接访问 类属性 或者调用其他的 类方法
语法如下
@classmethoddef 类方法名(cls):
pass
- 类方法需要用 修饰器 @classmethod 来标识,告诉解释器这是一个类方法
- 类方法的 第一个参数 应该是 cls
- 由 哪一个类 调用的方法,方法内的 cls 就是 哪一个类的引用
- 这个参数和 实例方法 的第一个参数是 self 类似
- 提示 使用其他名称也可以,不过习惯使用 cls
- 通过 类名. 调用 类方法,调用方法时,不需要传递 cls 参数
- 在方法内部
- 可以通过 cls. 访问类的属性
- 也可以通过 cls. 调用其他的类方法
示例
- 定义一个 工具类,每件工具都有自己的 name
- 需求 —— 在 类 封装一个 show_tool_count 的类方法,输出使用当前这个类,创建的对象个数
@classmethoddef show_tool_count(cls):
"""显示工具对象的总数"""
print("工具对象的总数 %d" % cls.count)
4.3.2 静态方法
- 在开发时,如果需要在 类 中封装一个方法,这个方法:
- 既 不需要 访问 实例属性 或者调用 实例方法
- 也 不需要 访问 类属性 或者调用 类方法
- 这个时候,可以把这个方法封装成一个 静态方法
语法如下
@staticmethoddef 静态方法名():
pass
- 静态方法 需要用 修饰器 @staticmethod 来标识,告诉解释器这是一个静态方法
- 通过 类名. 调用 静态方法
示例:
- 静态方法 show_help 显示游戏帮助信息
- 类方法 show_top_score 显示历史最高分
- 实例方法 start_game 开始当前玩家的游戏
class Game(object):
# 游戏最高分,类属性
top_score = 0 @staticmethod
def show_help():
print("帮助信息:让僵尸走进房间") @classmethod
def show_top_score(cls):
print("游戏最高分是 %d" % cls.top_score) def __init__(self, player_name):
self.player_name = player_name def start_game(self):
print("[%s] 开始游戏..." % self.player_name)
# 使用类名.修改历史最高分
Game.top_score = 999# 1. 查看游戏帮助Game.show_help()# 2. 查看游戏最高分Game.show_top_score()# 3. 创建游戏对象,开始游戏game = Game("小明")
game.start_game()# 4. 游戏结束,查看游戏最高分Game.show_top_score()
探索:
- 实例方法 —— 方法内部需要访问 实例属性
- 实例方法 内部可以使用 类名. 访问类属性
- 类方法 —— 方法内部 只需要访问 类属性
- 静态方法 —— 方法内部,不需要访问 实例属性 和 类属性
5. 单例
5.1 单例设计模式
- 设计模式
- 设计模式 是 前人工作的总结和提炼,通常,被人们广泛流传的设计模式都是针对 某一特定问题 的成熟的解决方案
- 使用 设计模式 是为了可重用代码、让代码更容易被他人理解、保证代码可靠性
- 单例设计模式
- 目的 —— 让 类 创建的对象,在系统中 只有 唯一的一个实例
- 每一次执行 类名() 返回的对象,内存地址是相同的
- 单例设计模式的应用场景
- 音乐播放 对象
- 回收站 对象
- 打印机 对象
- ……
5.2 静态方法: __new__
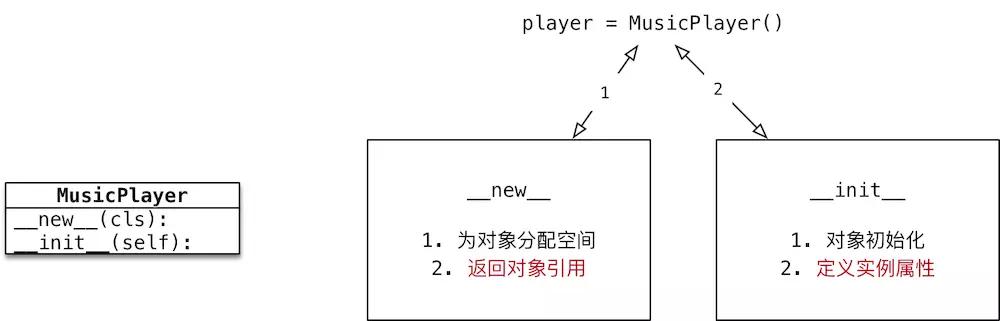
- 使用 类名() 创建对象时,Python 的解释器 首先 会 调用 __new__ 方法为对象 分配空间
- __new__ 是一个 由 object 基类提供的 内置的静态方法,主要作用有两个:
- 返回 对象的引用
- 在内存中为对象 分配空间
- Python 的解释器获得对象的 引用 后,将引用作为 第一个参数,传递给 __init__ 方法
重写 __new__ 方法 的代码非常固定!
- 重写 __new__ 方法 一定要 return super().__new__(cls),否则 Python 的解释器 得不到 分配了空间的 对象引用,就不会调用对象的初始化方法
- 注意:__new__ 是一个静态方法,在调用时需要 主动传递 cls 参数
class MusicPlayer(object):
def __new__(cls, *args, **kwargs):
# 如果不返回任何结果,就不会调用对象的初始化方法
return super().__new__(cls) def __init__(self):
print("初始化音乐播放对象")
player = MusicPlayer()
print(player)
5.3 Python 中的单例
- 单例 —— 让 类 创建的对象,在系统中 只有 唯一的一个实例
- 定义一个 类属性,初始值是 None,用于记录 单例对象的引用
- 重写 __new__ 方法
- 如果 类属性 is None,调用父类方法分配空间,并在类属性中记录结果
- 返回 类属性 中记录的 对象引用
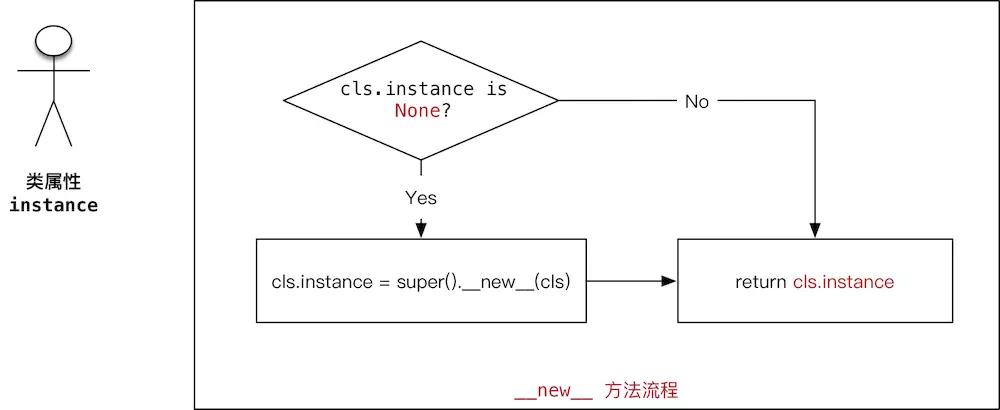
class MusicPlayer(object):
# 定义类属性记录单例对象引用
instance = None
def __new__(cls, *args, **kwargs):
# 1\. 判断类属性是否已经被赋值
if cls.instance is None:
cls.instance = super().__new__(cls) # 2\. 返回类属性的单例引用
return cls.instance
只执行一次初始化工作
- 在每次使用 类名() 创建对象时,Python 的解释器都会自动调用两个方法:
- __new__ 分配空间
- __init__ 对象初始化
- 在对 __new__ 方法改造之后,每次都会得到 第一次被创建对象的引用
- 但是:初始化方法还会被再次调用
需求
- 让 初始化动作 只被 执行一次
解决办法
- 定义一个类属性 init_flag 标记是否 执行过初始化动作,初始值为 False
- 在 __init__ 方法中,判断 init_flag,如果为 False 就执行初始化动作
- 然原由网后将 init_flag 设置为 True
- 这样,再次 自动 调用 __init__ 方法时,初始化动作就不会被再次执行 了
class MusicPlayer(object):
# 记录第一个被创建对象的引用
instance = None
# 记录是否执行过初始化动作
init_flag = False
def __new__(cls, *args, **kwargs):
# 1\. 判断类属性是否是空对象
if cls.instance is None: # 2\. 调用父类的方法,为第一个对象分配空间
cls.instance = super().__new__(cls) # 3\. 返回类属性保存的对象引用
return cls.instance def __init__(self):
if not MusicPlayer.init_flag:
print("初始化音乐播放器")
MusicPlayer.init_flag = True# 创建多个对象player1 = MusicPlayer()
print(player1)
player2 = MusicPlayer()
print(player2)
Tips
1、Python 能够自动的将一对括号内部的代码连接在一起:
return ("户型:%s\n总面积:%.2f[剩余:%.2f]\n家具:%s"
% (self.house_type, self.area,
self.free_area, self.item_list))
2、一个对象的 属性 可以是 另外一个类创建的对象。
3、在__init__方法中定义类的属性时,如果 不知道设置什么初始值,可以设置为 None):None 关键字 表示 什么都没有,表示一个 空对象,没有方法和属性,是一个特殊的常量。可以将 None 赋值给任何一个变量。
在 Python 中针对 None 比较时,建议使用is 判断
4、eval() 函数十分强大 —— 将字符串 当成 有效的表达式 来求值 并 返回计算结果
# 基本的数学计算In [1]: eval("1 + 1")
Out[1]: 2# 字符串重复In [2]: eval("'*' * 10")
Out[2]: '**********'# 将字符串转换成列表In [3]: type(eval("[1, 2, 3, 4, 5]"))
Out[3]: list# 将字符串转换成字典In [4]: type(eval("{'name': 'xiaoming', 'age': 18}"))
Out[4]: dict
在开发时千万不要使用 eval 直接转换 input 的结果,举个例子:
__import__('os').system('ls')# 等价代码import os
os.system("终端命令")