参与文末每日话题讨论,赠送异步新书
异步图书君
在有关21世纪的所有预测中,最不希望的一个也许是我们需要每天收集世界上任何地方、关于任何事情的海量数据。近几年来,人们见证了关于世界、生活和技术方面难以置信的数据爆炸,这也是我们确信引发变革的源动力。虽然我们生活在信息时代,但是仅仅收集数据而不发掘价值和抽取知识是没有任何意义的。
在20世纪开始的时候,随着统计学的诞生,世界都在收集数据和生成统计。那个时候,唯一可靠的工具是铅笔和纸张,当然还有观察者的眼睛和耳朵。虽然在19世纪取得了长足的发展,但是科学观察依然处在新生阶段。
100多年后,我们有了计算机、电子感应器以及大规模数据存储。我们不但可以持续地保存物理世界的数据,还可以通过社交网络、因特网和移动电话保存我们的生活数据。而且,存储技术水准的极大提高也使得以很小的容量存储月度数据成为可能,甚至可以将其放进手掌中。
但是存储数据不是获取知识。存储数据只是把数据放在某个地方以便后用。同样,随着存储容量的快速演化,现代计算机的容量甚至在以难以置信的速度提升。在读博士期间,我记得当我收到一个崭新、耀眼的全功能PC来开展科研工作时,我在试验室是多么的骄傲。而今天,我口袋里老旧的智能手机,还要比当时的PC快20倍。
机器学习是计算机科学、概率论和统计学相互融合的领域。机器学习的核心问题是推断问题或者说是如何使用数据和例子生成知识或预测。这也给我们带来了机器学习的两个基础问题:从大量数据中抽取模以及高层级知识的算法设计,和使用这些知识的算法设计——或者说得更科学一些:学习和推断。
皮埃尔-西蒙拉普拉斯(Pierre-Simon Laplace,1749—1827),法国数学家,也是有史以来最伟大的科学家之一,被认为是第一批理解数据收集重要性的人:他发现了数据不可靠,有不确定性,也就是今天说的有噪声。他也是第一个研究使用概率来处理不确定性等问题,并表示事件或信息信念度的人。
在他的论文《概率的哲学》(Essai philosophique sur les probabilits,1814)中,拉普拉斯给出了最初的支持新老数据推理的数学系统,其中的用户信念会在新数据可用的时候得到更新和改进。今天我们称之为贝叶斯推理。事实上,托马斯贝叶斯确实是第一个、早在18世纪末就发现这个定理的人。如果没有贝叶斯工作的铺垫,皮埃尔-西蒙拉普拉斯就需要重新发现同一个定理,并形成贝叶斯理论的现代形式。有意思的是,拉普拉斯最终发现了贝叶斯过世之后发表的文章,并承认了贝叶斯是第一个描述归纳推理系统原理的人。今天,我们会提及拉普拉斯推理,而不是贝叶斯推理,并称之为贝叶斯-普莱斯-拉普拉斯定理(Bayes-Price-Laplace Theorem)。
一个多世纪以后,这项数学技术多亏了计算概率论的新发现而得到重生,并诞生了机器学习中一个最重要、最常用的技术:概率图模型。
从此刻开始,我们需要记住,概率图模型中的术语图指的是图论,也就是带有边和点的数学对象,而不是图片或者图画。众所周知,当你想给别人解释不同对象或者实体之间的关系时,你需要拿纸画出带有连线或箭头的方框。这是一种简明易懂的方法,可以来介绍任何不同元素之间的关系。
确切地说,概率图模型(Probabilistic Graphical Models,PGM)是指:你想描述不同变量之间的关系,但是,你又对这些变量不太确定,只有一定程度的相信或者一些不确定的知识。现在我们知道,概率是表示和处理不确定性的严密的数学方法。
概率图模型是使用概率来表示关于事实和事件的信念和不确定知识的一种工具。它也是现在最先进的机器学习技术之一,并有很多行业成功的案例。
概率图模型可以处理关于世界的不完整的知识,因为我们的知识总是有限的。我们不可能观察到所有的事情,不可能用一台计算机表示整个宇宙。和计算机相比,我们作为人类从根本上是受限的。有了概率图模型,我们可以构建简单的学习算法,或者复杂的专家系统。有了新的数据,我们可以改进这些模型,尽全力优化模型,也可以对未知的局势和事件做出推断或预测。
在本文中,你将会学到关于概率图模型的基础知识,也就是概率知识和简单的计算规则。我们会提供一个概率图模型的能力概览,以及相关的R程序包。这些程序包都很成功,我们只需要探讨最重要的R程序包。
我们会看到如何一步一步地开发简单模型,就像方块游戏一样,以及如何把这行模型连接在一起开发出更加复杂的专家系统。我们会介绍下列概念和应用。每一部分都包含几个可以直接用R语言上手的示例:
机器学习。
使用概率表示不确定性。
概率专家系统的思想。
使用图来表示知识。
概率图模型。
示例和应用。
1.1 机器学习
为了完成任务,或者从数据中得出结论,计算机以及其他生物需要观察和处理自然世界的各种信息。从长期来看,我们一直在设计和发明各种算法和系统,来非常精准地并以非凡的速度解决问题。但是所有的算法都受限于所面向的具体任务本身。另外,一般生物和人类(以及许多其他动物)展现了在通过经验、错误和对世界的观察等方式取得适应和进化方面令人不可思议的能力。
试图理解如何从经验中学习,并适应变化的环境一直是科学界的伟大课题。自从计算机发明之后,一个主要的目标是在机器上重复生成这些技能。
机器学习是关于从数据和观察中学习和适应的算法研究,并实现推理和借助学到的模型和算法来执行任务。由于我们生活的世界本身就是不确定的,从这个意义上讲,即便是最简单的观察,例如天空的颜色也不可能绝对的确定。我们需要一套理论来解决这些不确定性。最自然的方法是概率论,它也是本文的数学基础。
但是当数据量逐渐增长为非常大的数据集时,即便是最简单的概率问题也会变得棘手。我们需要一套框架支持面向现实世界问题复杂度的模型和算法的便捷开发。
说到现实世界的问题,我们可以设想一些人类可以完成的任务,例如理解人类语言、开车、股票交易、识别画中的人脸或者完成医疗诊断等。
在人工智能的早期,构建这样的模型和算法是一项非常复杂的任务。每次产生的新算法,其实现和规划总是带着内在的错误和偏差。本文给出的框架,叫作概率图模型,旨在区分模型设计任务和算法实现任务。因为,这项技术基于概率论和图论,因此它拥有坚实的数学基础。但是同时,这种框架也不需要实践者一直编写或者重写算法,因为算法是针对非常原生的问题而设计的,并且已经存在了。
同时,概率图模型基于机器学习技术,它有利于实践人员从数据中以最简单的方式创造新的模型。
概率图模型中的算法可以从数据中学到新的模型,并使用这些数据和模型回答相关问题,当然也可以在有新数据的时候改进模型。
1.2 使用概率表示不确定性
概率图模型,从数学的角度看,是一种表示几个变量概率分布的方法,也叫作联合概率分布。换句话说,它是一种表示几个变量共同出现的数值信念的工具。基于这种理解,虽然概率图模型看起来很简单,但是概率图模型强调的是对于许多变量概率分布的表示。在某些情况下,“许多”意味着大量,比如几千个到几百万个。在这一部分里,我们会回顾概率图模型的基本概念和R语言的基本实现。如果你对这些内容很熟悉,你可以跳过这一部分。我们首先研究为什么概率是表示人们对于事实和事件信念的优良工具,然后我们会介绍概率积分的基本概念。接着,我们会介绍贝叶斯模型的基础构建模块,并做一些简单而有意思的计算。
1.2.1 信念和不确定性的概率表示
{--:}Probability theory is nothing but common sense reduced to calculation
{--:}Thorie analytique des probabilits, 1821.
{--:} Pierre-Simon, marquis de Laplace
正如皮埃尔-西蒙拉普拉斯所说,概率是一种量化常识推理和信念程度的工具。有意思的是,在机器学习的背景下,信念这一概念已经被不知不觉地扩展到机器上,也就是计算机上。借助算法,计算机会对确定的事实和事件,通过概率表示自己的信念。
让我们举一个众人熟知的例子:掷硬币游戏。硬币正面或者反面向上的概率或机会是多少?大家都应该回答是50%的机会或者0.5原由网的概率(记住,概率是0和1之间的数)。
这个简单的记法有两种理解。一种是频率派解释,另一种是贝叶斯派解释。第一种频率派的意思是如果我们投掷多次,长期来看一半次数正面向上,另一半次数反面向上。使用数字的话,硬币有50%的机会一面朝上,或者概率为0.5。然而,频率派的思想,正如它的名字,只在试验可以重复非常多的次数时才有效。如果只观察到一两次事实,讨论频率就没有意义了。相反,贝叶斯派的理解把因素或事件的不确定性通过指认数值(0~1或者0%~100%)来量化。如果你投掷一枚硬币,即使在投掷之前,你也肯定会给每个面指认50%的机会。如果你观看10匹马的赛马,而且对马匹和骑手一无所知,你也肯定会给每匹马指认0.1(或者10%)的概率。
投掷硬币是一类可以重复多次,甚至上千次或任意次的试验。然而,赛马并不是可以重复多次的试验。你最喜欢的团队赢得下次球赛的概率是多少?这也不是可以重复多次的试验:事实上,你只可以试验一次,因为只有一次比赛。但是由于你非常相信你的团队是今年最厉害的,你会指认一个概率,例如0.9,来确信你的团队会拿下下一次比赛。
贝叶斯派思想的主要优势是它不需要长期频率或者同一个试验的重复。
在机器学习中,概率是大部分系统和算法的基础部件。你可能想知道收到的邮件是垃圾邮件的概率。你可能想知道在线网站下一个客户购买上一个客户同一个商品的概率(以及你的网站是否应该立刻给它打广告的概率)。你也想知道下个月你的商铺拥有和这个月同样多客户的概率。
从这些例子可以看出,完全频率派和完全贝叶斯派之间的界限远远不够清晰。好消息是不论你选择哪一种理解,概率计算的规则是完全相同的。
1.2.2 条件概率
机器学习尤其是概率图模型的核心是条件概率的思想。事实上,准确地说,概率图模型都是条件概率的思想。让我们回到赛马的例子。我们说,如果你对骑手和马匹一无所知,你可以给每一匹马(假定有10匹马)指认0.1的概率。现在,你知道这个国家最好的骑手也参加了这项赛事。你还会给这些骑手指认相同的机会吗?当然不能!因此这个骑手获胜的概率可能是19%,进而所有其他骑手获胜的概率只有9%。这就是条件概率:也就是基于已知其他事件的结果,当前事件的概率。这种概率的思想可以完美地解释改变直觉认识或者(更技术性的描述)给定新的信息来更新信念。概率图模型就是关注这些技术,只是放在了更加复杂的场景中。
1.2.3 概率计算和随机变量
在之前的部分,我们看到了为什么概率是表示不确定性或者信念,以及事件或事实频率的优良工具。我们也提到了不管是贝叶斯派还是频率派,他们使用的概率计算规则是相同的。在本部分中,我们首先回顾概率计算规则,并介绍随机变量的概念。它是贝叶斯推理和概率图模型的核心概念。
样本空间,事件和概率
一个样本空间是一个试验所有可能输出的集合。在这个集合中,我们称中的一个点,为一个实现。我们称的一个子集为一个事件。
例如,如果我们投掷一枚硬币一次,我们可以得到正面(H)或者反面(T)。我们说样本空间是={H,T}。一个事件可以是我得到了正面(H)。如果我们投掷一枚硬币两次,样本空间变得更大,我们可以记录所有的可能={HH,HT,TH,TT}。一个事件可以是我们首先得到了正面。因此我的事件是E={HH,HT}。
更复杂的例子可以是某人身高的米数度量
原文中此处为链接,暂不支持采集
。样本空间是所有从0.0到10.9的正数。你的朋友很有可能都没有10.9米高,但是这并不会破坏我们的理论。
一个事件可以是所有的篮球运动员,也就是高于2米的人。其数学记法写作,相对区间=[0,10.9],E=[2,10.9]。
一个概率是指派给每一个事件E的一个实数P(E)。概率必须满足下列3个公理。在给出它们之前,我们需要回顾为什么需要使用这些公理。如果你还记得我们之前说的,不论我们对概率做何理解(频率派或贝叶斯派),控制概率计算的规则是一样的:
对于任意事件E,P(E)≥0:我们说概率永远为正。
P()=1,意味着包含所有可能事件的概率为1。因此,从公理1和2看到,任何概率都在0和1之间。
如果有独立事件E1,E2,...,那么
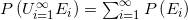
。
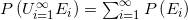
随机变量和概率计算
在计算机程序中,变量是与计算机内存中一部分存储空间相关联的名称或者标记。因此一个程序变量可以通过它的位置(和许多语言中的类型)来定义,并保存有且仅有一个取值。这个取值可以很复杂,例如数组或者数据结构。最重要的是,这个取值是已知的,并且除非有人特意改变,它保持不变。换句话说,取值只能在算法确定要改变它的时候才会发生变化。
而随机变量有点不同:它是从样本空间到实数的函数映射。例如,在一些试验中,随机变量被隐式地使用:
当投掷两颗骰子的时候,两个点数之和X是一个随机变量。
当投掷一枚硬币N次时,正面向上的次数X是一个随机变量。
对于每一个可能的事件,我们可以关联一个概率Pi。所有这些概率的集合是随机变量的概率分布。
让我们看一个例子:考虑投掷一枚硬币3次的试验。(样本空间中的)样本点是3次投掷的结果。例如,HHT,两次正面向上和一次背面向上是一个样本点。
因此我们可以很容易地列举所有可能的输出,并找出样本空间:
{-:-}S={HHH, HHT, HTH,THH,TTH,THT,HTT,TTT}
假设Hi为第i次投掷正面向上的事件。例如:
{-:-}H1={HHH,HHT,HTH,HTT}
如果我们给每个事件指认1/8的概率,那么使用列举的方法,我们可以看到P(H1)=P(H2)=P(H3)=1/2。
在这个概率模型中,事件H1、H2、H3是相互独立的。要验证这个结论,我们首先有:

我们还必须验证每一对乘积。例如:
对于另外两对也需要同样的验证。所以H1、H2、H3是相互独立的。通常,我们把两个独立事件的概率写作它们独自概率的乘积:P(A∩B)=P(A)P(B)。我们把两个不相干独立事件的概率写作它们独立概率的和:P(A∪B)=P(A)+P(B)。
如果我们考虑不同的结果,可以定义另外一种概率分布。例如,假设我们依然投掷3次骰子。这次随机变量X是完成3次投掷后,正面向上的总次数。
使用列举方法我们可以得到和之前一样的样本空间:
{-:-}S={HHH, HHT, HTH,THH,TTH,THT,HTT,TTT}
但是这次我们考虑正面向上的次数,随机变量X会把样本空间映射到表1-1所示的数值:
表1-1
s |
HHH |
HHT |
HTH |
THH |
TTH |
THT |
HTT |
TTT |
X(s) |
3 |
2 |
2 |
2 |
1 |
1 |
1 |
0 |
因此随机变量X的取值范围是{0,1,2,3}。和之前一样,如果我们假设所有点都有相同的概率1/8,我们可以推出X取值范围的概率函数,如表1-2所示:
表1-2
x |
0 |
1 |
2 |
3 |
P(X=x) |
1/8 |
3/8 |
3/8 |
1/8 |
1.2.4 联合概率分布
让我们回到第一个游戏,同时得到2次正面向上和一次6点,低概率的获胜游戏。我们可以给硬币投掷试验关联一个随机变量N,它是2次投掷后获得正面的次数。这个随机变量可以很好地刻画我们的试验,N取0、1和2。因此,我们不说对两次正面向上的事件感兴趣,而等价的说我们对事件N=2感兴趣。这种表述方便我们查看其他事件,例如只有1次正面(HT或TH),甚至0次正面(TT)。我们说,给N的每个取值指派概率的函数叫作概率分布。另一个随机变量是D,表述投掷骰子之后的点数。
当我们同时考虑两个试验(投掷硬币2次和投掷一个骰子)的时候,我们对同时获得0、1或2的概率以及1、2、3、4、5或6的点数概率更感兴趣。这两个同时考虑的随机变量的概率分布写作P(N,D),称作联合概率分布。
如果一直加入越来越多的试验和变量,我们可以写出一个很长很复杂的联合概率分布。例如,我们可能对明天下雨的概率,股市上涨的概率,以及明天上班路上高速堵车的概率感兴趣。这是一个复杂的例子但是没有实际意义。我们几乎可以确定股市和天气不会有依赖关系。然而,交通状况和天气状况是密切关联的。我可以写出分布P(W,M,T)——天气、股市、交通——但是它似乎有点过于复杂了。
一个概率图模型就是一个联合概率分布。除此以外,并无他物。
联合概率分布的最后一个重要概念是边缘化(Marginalization)。当你考察几个随机变量的概率分布,即联合概率分布时,你也许想从分布中消除一些变量,得到较少变量的分布。这个操作很重要。联合分布P(X,Y)的边缘分布P(X)可以通过下列操作获得:
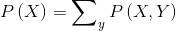
其中我们按照y所有可能的取值汇总概率。通过这个操作,你可以从P(X,Y)消除Y。作为练习,可以考虑一下这个概率与之前看到的两个不相干事件概率之间的关系。
对于数学见长的读者,当Y是连续值时,边缘化可以写作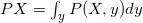
。
这个操作非常重要,但对于概率图模型也很难计算。几乎所有的概率图模型都试图提出有效的算法,来解决这个问题。多亏了这些算法,我们可以处理现实世界里包含许多变量的复杂而有效的模型。
1.2.5 贝叶斯规则
让我们继续探讨概率图模型的一些基本概念。我们看到了边缘化的概念,它很重要,因为当有一个复杂模型的时候,你可能希望从一个或者少数变量中抽取信息。此时就用上边缘化的概念了。
但是最重要的两个概念是条件概率和贝叶斯规则。
条件概率是指在知道其他事件发生的条件下当前事件的概率。很明显,两个事件必须某种程度的依赖,否则一个事件的发生不会改变另一个事件:
明天下雨的概率是多少?明天路上拥堵的概率是多少?
知道明天要下雨的话,路上拥堵的概率又是多少?它应该比没有下雨知识的情况下要高。
这就是条件概率。更形式化的,我们可以给出下列公式:
{-:-}=\frac{P\left( X,Y \right)}{P\left( X \right)}
从这两个等式我们可以轻松地推导出贝叶斯公式:
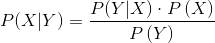
这个公式是最重要的公式,它可以帮助我们转换概率关系。这也是拉普拉斯生涯的杰作,也是现代科学中最重要的公式。然而它也很简单。
在这个公式中,我们把P(X|Y)叫作是给定Y下X的后验分布。因此,我们也把P(X)叫作先验分布。我们也把P(Y|X)叫做似然率,P(Y)叫做归一化因子。
我们再解释一下归一化因子。回忆一下:P (X,Y )= P (Y |X) P (X )。而且我们有
,即旨在消除(移出)联合概率分布中单个变量的边缘化。
因此基于上述理解,我们可以有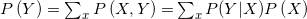
。
借助简单的代数技巧,我们可以把贝叶斯公式改写成一般的形式,也是最方便使用的形式:
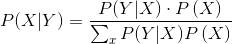
这个公式之美,以至于我们只需要给定和使用P(Y|X)和P(X),也就是先验和似然率。虽然形式简单,分母中的求和正如以后所见,可能是一个棘手的问题,复杂的问题也需要先进的技术。
理解贝叶斯公式
现在我们有X和Y两个随机变量的贝叶斯公式,让我们改写成另外两个变量的形式。毕竟,用什么字母并不重要,但是它可以给出公式背后的自然理解:
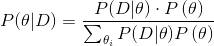
这些概念背后的直觉逻辑如下:
先验分布P()是指我们在知道其他信息之前对的认识——我的初始信念。
给定值下的似然率,是指我可以生成什么样的数据D。换句话说,对于所有的,D的概率是多少。
后验概率P(|D),是指观察到D之后,对的新信念。
这个公式也给出了更新变量信念的前向过程。使用贝叶斯规则可以计算新的分布。如果又收到了新的信息,我们可以一次又一次更新信念。
贝叶斯规则的第一个例子
在这一部分中,我们会看到第一个R语言的贝叶斯程序。我们会定义离散随机变量,也就是随机变量只能取预定义数量的数值。假设我们有一个制作灯泡的机器。你想知道机器是正常工作还是有问题。为了得到答案你可以测试每一个灯泡,但是灯泡的数量可能很多。使用少量样本和贝叶斯规则,你可以估计机器是否在正常的工作。
在构建贝叶斯模型的时候,我们总是需要建立两个部件:
先验分布
似然率
在这个例子中,我们不需要特殊的程序包;我们只需要编写一个简单的函数来实现贝叶斯规则的简单形式。
先验分布是我们关于机器工作状态的初始信念。我们确定了第一个刻画机器状态的随机变量M。这个随机变量有两个状态{working,broken}。我们相信机器是好的,是可以正常工作的,所以先验分布如下:
{-:-}P(M= working)=0.99
{-:-}P(M= broken)=0.01
简单地说,我们对于机器正常工作的信念度很高,即99%的正常和1%的有问题。很明显,我们在使用概率的贝叶斯思想,因为我们并没有很多机器,而只有一台机器。我们也可以询问机器供应商,得到生产正常机器的频率信息。我们也可以使用他们提供的数字,这种情况下,概率就有了频率派的解释。但是,贝叶斯规则在所有理解下都适用。
第二个变量是L,是机器生产的灯泡。灯泡可能是好的,也可能是坏的。所以这个随机变量包含两个状态{good,bad}。
同样,我们需要给出灯泡变量L的先验分布:在贝叶斯公式中,我们需要给出先验分布和似然率分布。在这个例子中,似然率是P(L|M),而不是P(L)。
这里我们事实上需要定义两个概率分布:一个是机器正常M=working时的概率,一个是机器损坏M=broken时的概率。我们需要回答两遍:
当机器正常的时候,生产出好的灯泡或者坏的灯泡的可能性是多少?
当机器不正常的时候,生产出好的灯泡或者坏的灯泡的可能性是多少?
让我们给出最可能的猜测,不管是支持贝叶斯派还是频率派,因为我们有下列统计:
{-:-}P(L=good |M= working)=0.99
{-:-}P(L=bad |M= working)=0.01
{-:-}P(L=good |M= broken)=0.6
{-:-}P(L=bad |M= broken)=0.4
我们相信,如果机器正常,生产100个灯泡只会有一个是坏的,这比之前说的还要高些。但是在这个例子中,我们知道机器工作正常,我们期望非常高的良品率。但是,如果机器坏掉,我们认为至少40%的灯泡都是坏的。现在,我们已经完整地刻画了模型,并可以使用它了。
使用贝叶斯模型是要在新的事实可用时计算后验分布。在我们的例子中,我们想知道,在已知最后一个灯泡是坏的情况下机器是否可以正常工作。所以,我们想计算P(M|L)。我们只需要给出P(M)和P(L|M),最后只需用一下贝叶斯公式来转换概率分布。
例如,假设最后生成的灯泡是坏的,即L=bad。使用贝叶斯公式我们有:
{-:-}P(M=working|L=bad)=
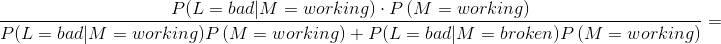
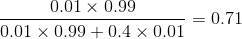
正如所见,机器正常工作的概率是71%。这个值比较低,但是符合机器依然正常的直观感觉。尽管我们收到了一个坏灯泡,但也仅此一个,也许下一个就好了。
让我们重新计算同样的问题,其中机器正常与否的先验概率和之前的相同:50%的机器工作正常,50%的机器工作不正常。结果变成:
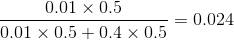
机器有2.4%的概率正常工作。这就很低了。确实,给定机器质量后,正如建模成似然率,机器似乎要生产出坏灯泡。在这个例子中,我们并没有做有关机器正常的任何假设。生产出一个坏灯泡可以看作出问题的迹象。
贝叶斯规则的第一个R语言例子
看了之前的例子,有人会问第一个有意义的问题:如果观察多个坏灯泡我们需要怎么办?只看到一个坏灯泡就说机器需要维修,这似乎有些不合情理。贝叶斯派的做法是使用后验概率作为新的概率,并在序列中更新后验分布。然后,徒手做起来会很繁重,我们会编写第一个R语言贝叶斯程序。
下列代码是一个函数,计算给定先验分布、似然率和观察数据序列后的后验概率。这个函数有3个变量:先验分布、似然率和数据序列。prior和data是向量,likelihood是矩阵:
prior <-c(working =0.99, broken =0.01) likelihood <-rbind( working =c(good =0.99, bad =0.01), broken =c(good =0.6, bad =0.4)) data <-c("bad", "bad", "bad", "bad")
所以我们定义了3个变量,包含工作状态working和broken的prior,刻画每个机器状态(working和broken)的likelihood,灯泡变量L上的distribution。因此一共有4个值,R矩阵类似于之前定义的条件概率:
likelihood good bad working 0.99 0.01 broken 0.60 0.40
data变量包含观察到的,用于测试机器和计算后验概率的灯泡序列。因此,我们可以定义如下贝叶斯更新原由网函数:
bayes < -function(prior, likelihood, data) { posterior < -matrix(0, nrow =length(data), ncol =length(prior)) dimnames(posterior) < -list(data, names(prior)) initial_prior < -prior for (i in 1:length(data)) { posterior[i, ] < - prior *likelihood[, data[i]]/ sum(prior *likelihood[,data[i]]) prior < -posterior[i, ] } return(rbind(initial_prior, posterior)) }
这个函数做了下列事情:
创建一个矩阵,存储后验分布的连续计算结果。
然后对于每一个数据,给定当前先验概率计算后验概率:和之前的一样,你可以看到贝叶斯公式的R代码。
最后,新的先验概率是当前的后验概率,而且同样的过程可以迭代。
最终,函数返回了一个矩阵,包含初始先验概率和所有后续后验概率。
让我们多运行几次,理解一下工作原理。我们使用函数matplot绘出两个分布的演化情况。一个是机器正常(绿色线)的后验概率,一个是机器故障(红色线)的后验概率,如图1-1所示。
<strong>matplotstrong>(<strong>bayesstrong>(prior, likelihood, data), t ='b', lty =1, pch =20, col =<strong>cstrong>(3, 2))
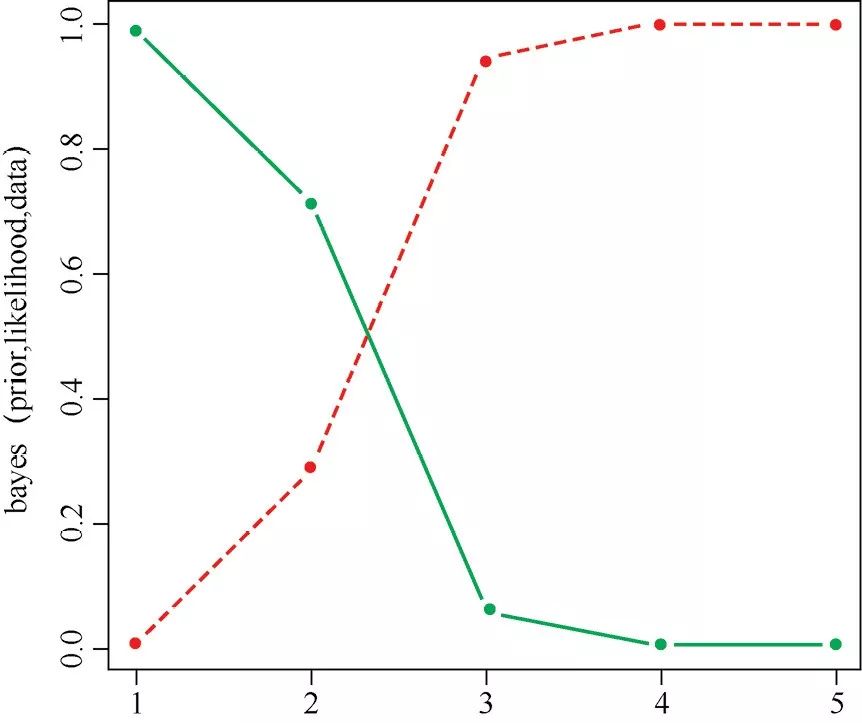
图1-1
结果可以从图中看到:随着坏灯泡的增多,机器正常的概率快速下降(实线或绿色线)
原文中此处为链接,暂不支持采集
我们原本希望100只灯泡中只有1个坏灯泡,不要太多就好。所以这个机器现在需要维护了。红色线或虚线表示机器有问题。
如果先验概率不同,我们可以看到不同的演化。例如,假设我们不知道机器是否可以正常工作,我们为每一种情况指认相同的概率:
prior < -<strong>cstrong>(working =0.5, broken =0.5)
再次运行代码:
<strong>matplotstrong>(<strong>bayesstrong>(prior, likelihood, data), t ='b', lty =1, pch =20, col =<strong>cstrong>(3, 2))
我们又得到了一个快速收敛的曲线,其中机器有问题的概率很高。这对于给定一批坏灯泡的情形来说,并不意外,如图1-2所示。
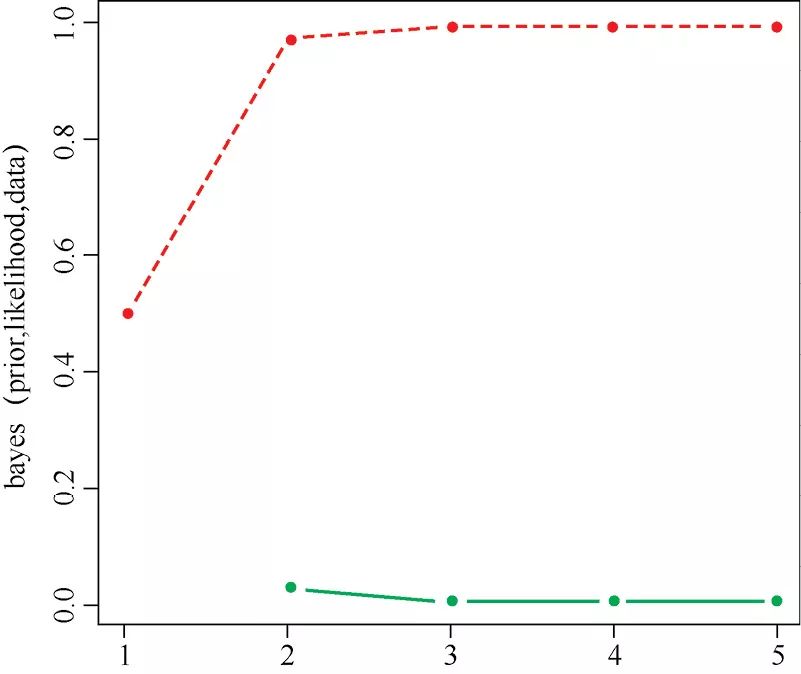
图1-2
如果一直变换数据,我们可以看到不同的行为。例如,假设机器正常工作的概率是99%。我们观察10个灯泡,其中第一个灯泡是坏的。我们有R代码:
prior =c(working =0.99, broken =0.01) data =c("bad", "good", "good", "good", "good", "good", "good", "good", "good", "good") matplot(bayes(prior, likelihood, data), t ='b', pch =20, col =c(3, 2))
结果如图1-3所示。
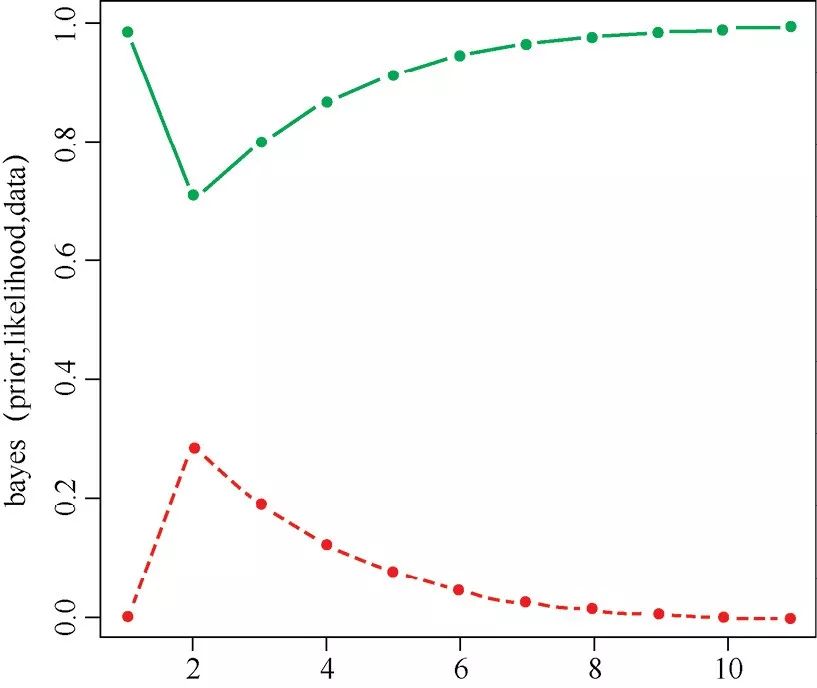
图1-3
算法在第一个灯泡处犹豫了一下。因为这么好的机器,不大可能生产出一个坏灯泡。但是然后它又收敛到很高的概率,因为好灯泡的序列不会预示任何问题。
我们的第一个R语言贝叶斯模型就完成了。本文的其他部分,会介绍如何创建带有多于两个随机变量现实世界的模型,以及如何解决两个重要问题:
推断的问题,即收到新数据时计算后验概率的问题。
学习的问题,即数据集里先验概率的确定问题。
细心的读者也许会问:刚才看到的这个简单的算法可以解决推断问题吗?它确实可以,但是只能在有两个离散变量的时候。这有些过于简单,而无法捕捉现实世界的复杂性。
1.3 概率图模型
在本章的最后一部分,我们会介绍概率图模型,作为原生框架支持通过简单的模块生成复杂的概率模型。这些复杂模型通常对于要解决的复杂任务是必需的。而复杂并不意味着混乱,简单的事情是最好、最有效的。复杂是指为了表示和解决拥有很多输入、部件或者数据的任务,我们需要一个不完全平凡的模型,但是要满足足够的复杂度。
这个复杂的模型可以分解成几个相互交互的简单问题。最终,最简单的构建模块是一个变量。这个变量有一个随机值,或者像之前部分看到的带有不确定性的一个值。
1.3.1 概率模型
如果你还记得,我们看到使用概率分布表示复杂概念是有可能的。当我们有许多随机变量时,我们把这个分布叫作联合分布。有时拿到几百个甚至上千个更多的随机变量并非不可能。表示这么庞大的分布是非常困难的,在大多数情况下也是不可能的。
例如,在医学诊断中,每一个变量表示一个症状。我们可以拿到许多这样的变量。其他变量可以表示病人的年龄、性别、体温、血压等。我们可以使用许多不同的变量表示病人状态。我们也可以加入其他信息,例如最近的天气条件,病人的年龄和饮食状况。
从这个复杂的系统中,我们想解决两个问题:
从病人的数据库中,我们希望评估和发现所有概率分布,以及相关参数。这当然是自动的过程。
我们希望把问题放入模型中,例如,“如果我们观察到了一系列症状,我们病人是否还健康?”。类似的,“如果我改变病人的饮食,并开了这个药,我的病人是否会恢复?”。
然而,还有一个重要的问题:在这个模型中,我们想利用其他重要的知识,甚至是最重要的知识之一:不同模型部件之间的交互。换句话说,不同随机变量之间的依赖。例如,症状和疾病之间有明显的依赖关系。另外,饮食和症状之间的依赖关系比较遥远,或者通过其他变量例如年龄、性别有所依赖。
最终,在这个模型中完成的所有推理都天然地带有概率的性质。从对变量X的观察,我们想推出其他变量的后验分布,得到它们的概率而不是简单的是或不是的回答。有了这个概率,我们可以拿到比二元响应更丰富的回答。
1.3.2 图和条件独立
让我们做一个简单的计算。假设我们有两个二元随机变量,我们把它们命名为X和Y。这两个变量的联合概率分布是P(X,Y)。它们是二元变量,因此我们可以为每一个取值,为简便起见称之为x1、x2和y1、y2。
我们需要给定多少概率值?一共有4个,即P(X= x1, Y= y1)、P(X= x1, Y= y2)、P(X= x2, Y=y1)和P(X= x2, Y= y2)。
假设我们不止有两个二元随机变量,而是10个。这还是一个非常简单的模型,对吧?我们把这些变量叫作X1、X2、X3、X4、X5、X6、X7、X8、X9、X10。这种情况下,我们需要提供210=1 024个值来确定我们的联合概率分布。如果我们还有10个变量,也就是一共20个变量该怎么办?这还是一个非常小的模型。但是我们需要给定220=1 048 576个值。这已经超过了一百万个值了。因此对于这么简单的模型,建模任务已经变得几乎不可能了!
概率图模型正是简洁地描述这类模型的框架,并支持有效的模型构建和使用。事实上,使用概率图模型处理上千个变量并不罕见。当然,计算机模型并不会存储几十亿个值,但是计算机会使用条件独立,以便模型可以在内存中处理和表示。而且,条件独立给模型添加了结构知识。这类知识给模型带来了巨大的不同。
在一个概率图模型中,变量之间的知识可以用图表示。这里有一个医学例子:如何诊断感冒。这只是一个示例,不代表任何医学建议。为了简单,这个例子做了极大的精简。我们有如下几个随机变量:
Se:年内季节。
N:鼻子堵塞。
H:病人头痛。
S:病人经常打喷嚏。
C:病人咳嗽。
Cold:病人感冒。
因为每一个症状都有不同的程度,所以我们很自然地使用随机变量来表示这些症状。例如,如果病人的鼻子有点堵塞,我们会给这个变量指派,例如60%。即P(N=blocked)=0.6和P(N=notblocked)=0.4。
在这例子中,概率分布P(Se,N,H,S,C,Cold)一共需要425=128个值(4个季节,每一个随机变量取2个值)。这已经很多了。坦白讲,这已经很难确定诸如“鼻子不堵塞的概率”“病人头痛和打喷嚏等的概率”。
但是,我们可以说头痛与咳嗽或鼻子堵塞并不是直接相关,除非病人得了感冒。事实上,病人头痛有很多其他原因。
而且,我们可以说季节对打喷嚏、鼻子阻塞有非常直接的影响,或者咳嗽对于头痛的影响很少或没有。在概率图模型中,我们会用图表示这些依赖关系。如图1-4所示,每一个随机变量都是图中的节点,每一个关系都是两个节点间的箭头。
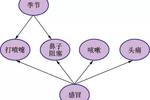
图1-4
如图1-4所示,概率图模型中的每一个节点间都存在有向关系,即箭头。我们可以使用这种方式来简化联合概率分布,以便概率可以追踪。
使用图作为模型来简化复杂(或者甚至混乱)的分布有诸多好处:
首先,可以从上个例子中看到,通常我们建模一个问题的时候,随机变量只与其他随机变量的小规模子集直接交互。因此,使用图可以使得模型更加紧凑和易于处理。
图中的知识和依赖易于理解和沟通。
图模型引出了联合概率分布的紧凑表示,并且易于计算。
执行推断和学习的算法可以使用图论和相关算法,以便改进和推动所有推断和学习:与初始的联合概率分布相比,使用概率图模型会以几个级数的速度加速计算。
1.3.3 分解分布
在之前的普通感冒诊断的例子中,我们定义了一个简单的模型,包含变量Se、N、H、S、C和R。我们看到,对于这样一个简单的专家系统,我们就需要128个参数!
我们还看到,我们可以基于常识或者简单的知识做出几个独立假设。在以后的内容中,我们会看到如何从数据集中发现这些假设(也叫作结构学习)。
所有我们可以做出假设,重写联合概率分布:
{-:-}P(Se,N,H,S,C,Cold)
{-:-}=P(Se)P(S|Se,Cold)P(N|Se,Cold)P(Cold)P(C|Cold)P(H|Cold)
在这个分布中,我们进行了分解。也就是说,我们把原来的联合概率分布表示为一些因子的乘积。在这个例子中,因子是更加简单的概率分布,例如P(C|Cold),病人感冒的情况下咳嗽的概率。由于我们可以把所有的变量看作二元的(除了季节,它有4个取值),每一个小的因子(分布)只需要确定少量的参数:4+23+23+2+22+22=30。我们只需要30个简单的参数,而不是128个!这是个巨大的改进。
我说过,参数非常容易确定,不管是通过手工还是根据数据。例如,我们不知道病人是否得了感冒,因此我们可以给变量Cold指派相同的概率,即P(Cold=true)=P(Cold=false)=0.5。
类似的,我们也很容易确定P(C|Cold),因为如果病人得了感冒(Cold = true),他很有可能咳嗽。如果他没有感冒,病人咳嗽的概率很低,但是不是零不能确定,因为还有其他可能的原因。
1.3.4 有向模型
通常,有向概率图模型可以按照如下形式分解多个随机变量X1,X2,...,Xn上的联合概率分布:
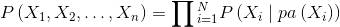
pa(Xi)是图中定义的变量Xi的父变量的子集。
图中的父变量很容易理解:当箭头从A指向B时,A就是B的父变量。一个节点可以有很多可能的子节点,也可以有很多可能的父节点。
有向模型非常适合建模需要表示因果关系的问题。它也非常适合参数学习,因为每一个局部概率分布都很容易学习。
我们在本文中多次提到了概率图模型可以使用简单的模块进行构建,并组合出更大的模型。在有向模型中,模块指的是小的概率分布P(Xi|pa(Xi))。
而且,如果我们想给模型扩展9个新的变量以及一些关系,我们只需简单扩展图形。有向概率图模型的算法适用于任何图形,不管什么样的规模。
尽管如此,并不是所有的概率分布都可以表示成有向概率图模型。有时,我们也有必要放松一些假设。
同时,注意到图必须是无环的很重要。这意味着,你不可能同时找到从A到B的箭头和从B到A的箭头,如图1-5所示。
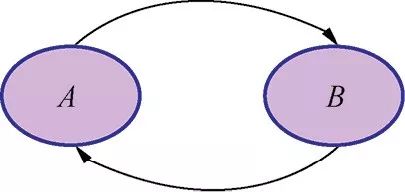
图1-5
事实上,这个图并不表示之前定义的分解过程。它可能意味着A是B的原因,同时B也是A的原因。这是矛盾的,也没有等价的数学表示。
当假设或者关系不是有向的,还存在第二种概率图模型的形式。它的边都是无向的。它也叫作无向概率图模型原由网或者马尔科夫网络。
1.3.5 无向模型
无向概率图模型可以按照如下形式分解多个随机变原由网量X1,X2,...,Xn上的联合概率分布:
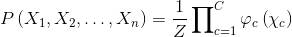
这个公式的解释如下:
左边的第一个项是通常的联合概率分布。
常数Z是归一化常数,确保右侧所有项的和是1,因为这是一个概率分布。
c是变量c子集上的因子,以便这个子集的每一个成员是一个极大团,也就是内部所有节点都相互连接的子图,如图1-6所示。
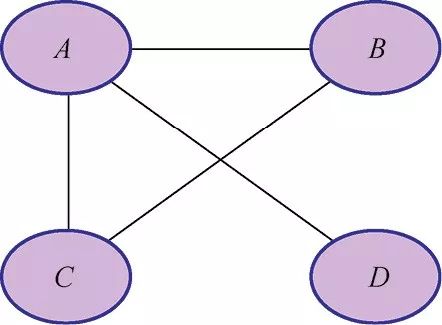
图1-6
在上图中,我们有4个节点,并且函数c定义在子集,也就是极大团{ABC}和{A,D}上。因此这里的概率分布并不复杂。这种类型的模型在计算机视觉、图像处理、财经和其他变量间关系遵循一定模式的领域都有广泛的应用。
1.3.6 示例和应用
现在来讨论一下概率图模型的应用。其实这些应用用几百页去讲述也很//www.58yuanyou.com难涵盖其中的一部分。正如我们看到的,概率图模型是一种建模复杂概率模型的很有用的框架,可以使得概率易于理解和处理。
在这部分中,我们会使用之前的两个模型:灯泡机和感冒诊断。
回忆一下,感冒诊断模型有下列分解形式:
{-:-}P(Se,N,H,S,C,Cold)=P(Se)P(S|Se,Cold)P(N|Se, Cold)P(Cold)P(C|Cold)P(H|Cold)
而灯泡机仅仅通过两个变量定义:L和M。分解形式也很简单。
{-:-}P(L,M)=P(M)P(L|M)
对应分布的图模型也很简单,如图1-7所示。
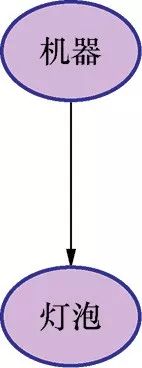
图1-7
为了表示概率图模型,我们会使用R程序包gRain。安装如下:
source("http://bioconductor.org/biocLite.R") biocLite() install.packages("gRain")
需要注意,这个安装过程可能会持续几分钟,因为这个程序包还依赖于许多其他的程序包(尤其是我们经常用到的gRbase程序包),而且提供了对图模型的一些基本操作函数。当程序包安装好后,你可以加载:
library("gRbase")
首先,我们想定义一个带有变量A、B、C、D、E的简单无向图:
graph < -ug("A:B:E + C:E:D")class(graph)
我们定义了带有团A、B和E以及另一个团C、E和D的图模型。这形成了一个蝴蝶状的图。它的语法很简单:字符串的每一个团用+分开,每一个团使用冒号分隔的变量名定义。
接着我们需要安装图的可视化程序包。我们会使用流行的Rgraphviz。要安装可以输入:
install.packages("Rgraphviz") plot(graph)
你可以得到第一个无向图,如图1-8所示。
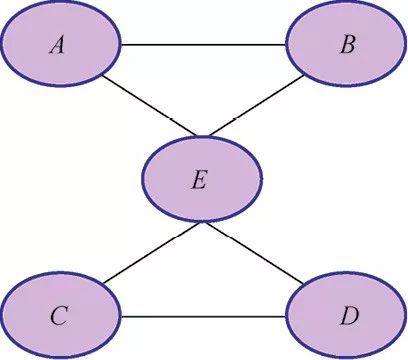
图1-8
接着,我们希望定义一个有向图。假设我们依然有变量{A, B, C, D, E}:
dag < -dag("A + B:A + C:B + D:B + E:C:D")dagplot(dag)
语法依然很简单:没有父节点的节点单独表示,例如A,否则父节点通过冒号分隔的节点列表刻画。
这个程序包提供了多种定义图模型的语法。你也可以按照节点的方式构建图模型。我们会在本文中用到几种表示法,以及一个非常著名的表示法:矩阵表示法。一个图模型可以等价地表示为一个方阵,其中每一行和每一列表示一个节点。如果节点间存在边,那么矩阵的系数是1,否则为0。如果图是无向的,矩阵会是对称的;否则可以是任何样式。
最终,通过第二个例子我们可以得到图1-9所示的图模型。
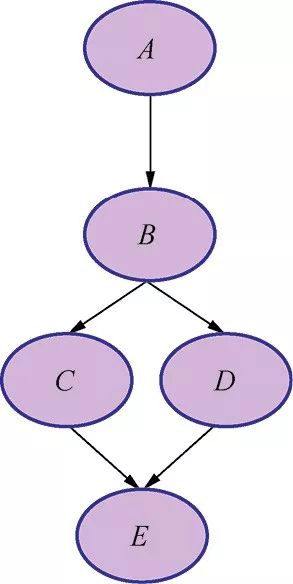
图1-9
现在我们想为灯泡机问题定义一个简单的图模型,并给出数值概率。我们再做一遍计算,看看结果是否一致。
首先,我们为每一个节点定义取值:
machine_val < -c("working", "broken") light_bulb_val < -c("good", "bad")
然后为两个随机变量定义百分比数值:
machine_prob < -c(99, 1) light_bulb_prob < -c(99,1, 60, 40)
接着,使用gRain定义随机变量:
M < -cptable(~machine, values = machine_prob, levels = machine_val) L < -cptable(~light_bulb |machine, values = light_bulb_prob, levels = light_bulb_val)
这里,cptable表示条件概率表:它是离散型随机变量概率分布的内存表示。
最后,我们可以构建新的概率图模型。
plist < -compileCPT(list(M, L)) plist
打印网络的时候,结果如下:
CPTspec with probabilities: P( machine ) P( light_bulb |machine )
这里,可以清楚地看到之前定义的概率分布。如果我们打印出变量的分布,我们可以再次看到之前的结果:
plist$machine plist$light_bulb
输出的结果如下:
>plist$machine machine working broken 0.99 0.01 >plist$light_bulb machine light_bulb working broken good 0.99 0.6 bad 0.01 0.4
现在我们从模型中找出后验概率。首先,给模型输入证据(即我们观察到一个坏灯泡),操作如下:
net < -grain(plist) net2 < -setEvidence(net, evidence =list(light_bulb ="bad")) querygrain(net2, nodes =c("machine"))
程序包会借助推断算法计算结果,并输出下列结果:
$machine machine working broken 0.7122302 0.2877698
这个结果与之前使用贝叶斯方法得到的结果完全相同。现在我们可以创建更加强大的模型,以及针对不同的问题应用不同的算法。
1.4 小结
在本文中,我们学到了概率论的基础概念。
我们看到了如何以及为什么使用概率来表示数据和知识的不确定性,同时我们还介绍了贝叶斯公式。这是计算后验概率的最重要的公式。也就是说,当新的数据可用时,要更新关于一个事实的信念和知识。
我们看到了什么是联合概率分布,同时看到它会很快变得很复杂以至于难以处理。我们学到了概率图模型的基础知识,它是对概率模型进行易于处理、高效和简单建模的原生框架。最后,我们介绍了概率图模型的不同类型,并学到如何使用R程序包来编写第一个模型。
本文摘自《概率图模型:基于R语言》

概率图模型:基于R语言
作者: 【法】David Bellot(大卫贝洛特)
★ 概率图,热门的机器学习研究方向★ 借助流行的R语言,掌握贝叶斯网络和马尔科夫网络概率图模型结合了概率论与图论的知识,提供了一种简单的可视化概率模型的方法,在人工智能、机器学习和计算机视觉等领域有着广阔的应用前景。本书旨在帮助读者学习使用概率图模型,理解计算机如何通过贝叶斯模型和马尔科夫模型来解决现实世界的问题,同时教会读者选择合适的R语言程序包、合适的算法来准备数据并建立模型。本书适合各行业的数据科学家、机器学习爱好者和工程师等人群阅读、使用。
在“异步图书”后台回复“关注”,即可免费获得2000门在线视频课程;推荐朋友关注根据提示获取赠书链接,免费得异步图书一本。赶紧来参加哦!
扫一扫上方二维码,回复“关注”参与活动!
今日活动转发本文到朋友圈或者50人以上读者群,截图给“异步图书后台”,并在文末留言说出你对本文的感想,12.20日我们将选出1名读者赠送本书。
昨日获奖读者:青年 tengsorflow
点击阅读原文,购买《概率图——基于R语言一书》