从核酸提取、文库构建,到上机测序、数据分析,越来越多的实验室选择将这些决定实验命运的关键步骤掌控在自己手中。下面就由小编带大家看一看自建库和测序过程中有哪些需要特别注意的环节,干货满满,不要错过哦~

问
常规Illumina NGS文库长什么样?
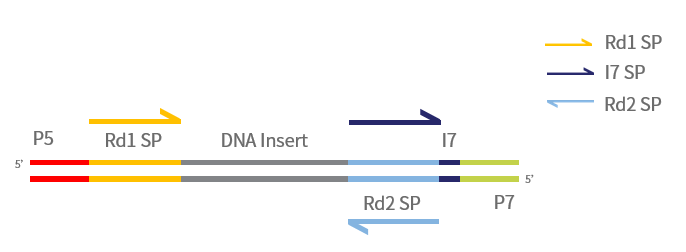
图1 单端index文库测序模式图
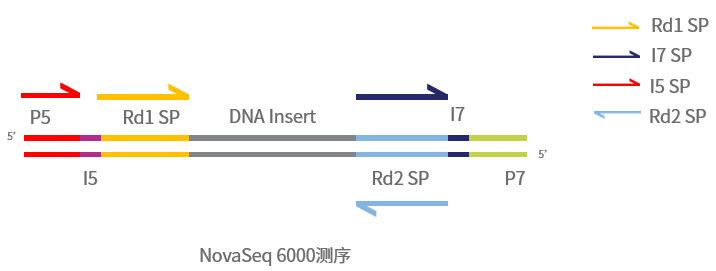
图2 双端index文库测序模式图(NovaSeq 6000平台)
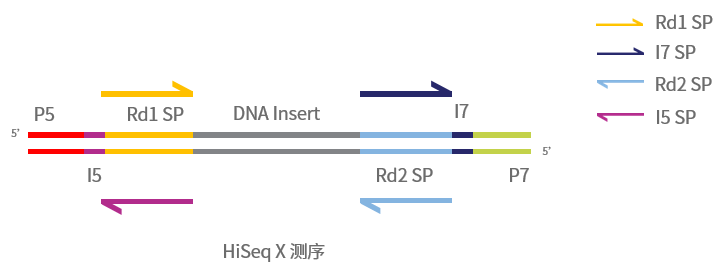
图3 双端index文库测序模式图(HiSeq X平台)
答

如图,文库结构可分为以下几个部分:插入片段,P5、P7接头,测序引物结合位点及index。
其中P5、P7接头位于文库两端,可以与flowcell上的寡核苷酸结合,在簇生成和测序过程中可作为引物或起到固定模板链的作用。
Index是不同样本的区分依据,当同一条lane中混入多个样本测序时,即可根据index区分来自不同样本的reads。根据建库时使用接头结构不同,又分为单index文库和双index文库。随着测序通量的不断增加,每条lane可以容纳的样本量也越来越多,双index可以变化出更多种组合,且能够降低标签串扰的比例,因此一些对灵敏度要求较高的检测通常会构建双index文库[1]。
图中黄色和蓝色的部分是测序引物结合位点,相信机智的你一定发现了:index5在NovaSeq 6000和HiSeq X平台的测序方向是不同的。完成Read1、index7测序之后,NovaSeq 6000平台会继续以这条链为模板进行ind原由网ex5的测序,测序引物是flowcell上的P5接头,因此index5的测序方向和Read1、index7是一致的。而HiSeq X平台的index5、Read2测序则是在末端翻转后进行的,因此index5的测序方向与Read2一致,而与Read1、index7相反,同样的index5在HiSeq X和NovaSeq 6000平台测得的序列是反向互补的,因此在填写文库信息的时候一定要注意测序平台和序列的对应关系。

问
文库构建的主要步骤?
答
以基因组DNA为例,构建DNA小片段文库的主要步骤如下:1)使用转座酶或超声波将基因组DNA打断;2)末端修复;3)3’端加A;4)接头上3’端突出的T碱基与待测片段3’端的A碱基互补配对,为待测片段两端添加上接头;5)连接接头后纯化;6)PCR扩增;7)PCR后纯化。
问
碱基不平衡对测序结果的影响?
答
Illumina 测序仪在收集信号时,并不是拍摄一张彩色照片一次完成的,而是分 A、C、G、T www.58yuanyou.com4 个波长,分别拍摄 4 张单色照片,然后通过软件处理把这 4 张图叠加成一张。这是一种权宜之计,目的是减少图片文件的大小,从而降低对于数据存贮空间的要求。但也有缺点,一旦某一张或几张照片的信号强度不够,或者没有信号,则图片的叠加就不能准确完成。碱基不平衡文库(即A、G、C、T 四种碱基的含量远远偏离 25%)在测序时会导致某些图片(波长)没有信号或者信号很弱,在碱基识别时准确性降低。常见的碱基不平衡文库有BS甲基化文库、单细胞转录组文库、PCR产物文库等,为了减少碱基不平衡对测序结果的影响,通常会混入一定比例的phix文库。
问
Phix文库的作用?
答
Phix 文库是校准文库,是 illumina 的一种试剂,来源于病毒基因组DNA。其基因序列已精确知晓,GC 比例约为 40%,与人类、哺乳类的基因组的 GC 比例接近。其基因序列又与人类的基因序列相去甚远,且不含有index。在与哺乳类基因组一起测序时,可以通过基因序列比对或数据拆分而将之去除。在测碱基不平衡的文库样本时,可以加入大量的 phix 文库,以部分抵消样本的不平衡性。也可以少量地加入phix文库,以作为 control library 来验证测序质量。
问
Index可以容纳多少种文库?
答
以8碱基index为例,单端index文库理论上可以有4^8=65536种index,双端index文库理论上可以有65536^2=4294967296种index,但实际pooling时为了避免因对焦不准造成index读错,造成数据无法拆分,需要使用碱基分布均匀的in原由网dex。
问
文库质检的方法?
答
上机前我们会使用Aglient 2100或LabChip GX Touch生物芯片分析系统检测文库片段大小,并使用StepOnePlusTMReal-Time PCR System,以P5、P7接头作为引物进行QPCR定量。由于Illumina文库开始测序之前会先以P5、P7接头为引物进行桥式PCR,在flowcell上生成簇,因此这样的上机定量结果是比较准确的。
问
文库pooling的原则?
答
不同文库应按照有效浓度和目标下机数据量pooling,即各文库混合后摩尔浓度比=需求数据量比。除此之外还需要考虑index的碱基分布,如同1条lane中同一个位置的同一种碱基占比最好在50%以下,每3位中至少有1位碱基不同,不同文库的index应至少有2个碱基的差异等。
问
文库测序过滤内容和参数?
答
1)去除低质量的reads:reads中质量值Q≤19的碱基占总碱基的50%以上则舍弃该条read,对于双端测序,若一端为低质量reads,则会去掉两端reads;
2)去除接头污染的reads:reads中接头污染的碱基数大于5bp则舍弃该条read,对于双端测序,若一端受到接头污染,则去掉两端的reads;
3)去除含N较多的reads:reads中读N碱基比例大于5%则舍弃该条read,对于双端测序,若一端含N比例大于5%,则会去掉两端reads。
问
测序中的Duplication是什么?
答
Duplication是指起始与终止位置完全一致的片段。引起Duplication的主要原因是在测序中有PCR过程,来源于同一个DNA片段PCR的产物被重复测序,就会产生duplication。次要原因是正巧两个插入片段的头和尾的位置完全一致,导致这一现象可能的原因有以下几种:a. 物种基因组小,本身的片段多样性低,测定的数据量多,重复的数据多;b. 建库过程中建库起始量少,片段多样性低,在相同的PCR条件下,会造成文库总量低,后期数据的dup率高;c.片原由网段打断或加接头存在偏好性,文库的多样性较差。Dup率计算主要有以下2种方法:一种是数据质控时计算,利用 reads 序列来计算dup,要求 read 序列一样才算作duplication,duplicate reads数目除以总 reads数目计算比率;另一种是比对分析时计算,根据read比对上基因组的位置来判断,比对的位置一样www.58yuanyou.com就算作duplication,一般会有 2bp的容错。
问
HiSeq X和NovaSeq 6000数据产出水平如何?
答
对于质检合格的碱基平衡文库,使用PE150试剂测序,我们承诺HiSeq X平台数据产出≥120Gb/lane,NovaSeq 6000平台S4试剂数据产出≥850Gb/lane。实际统计HiSeq X平均每条lane数据产出145.71 Gb,平均Q30为93.8%;NovaSeq平均每条lane数据产出958Gb,平均Q30为93.0%,在碱基准确度、测序均一性、可用数据比例等方面均表现卓越。
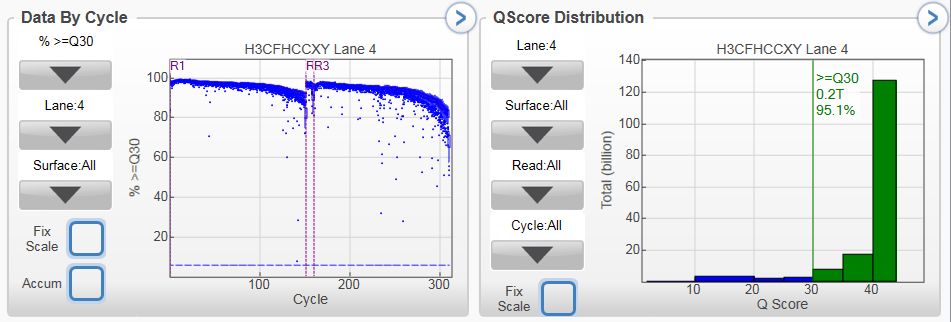
图4 HiSeq X平台下机数据SAV图
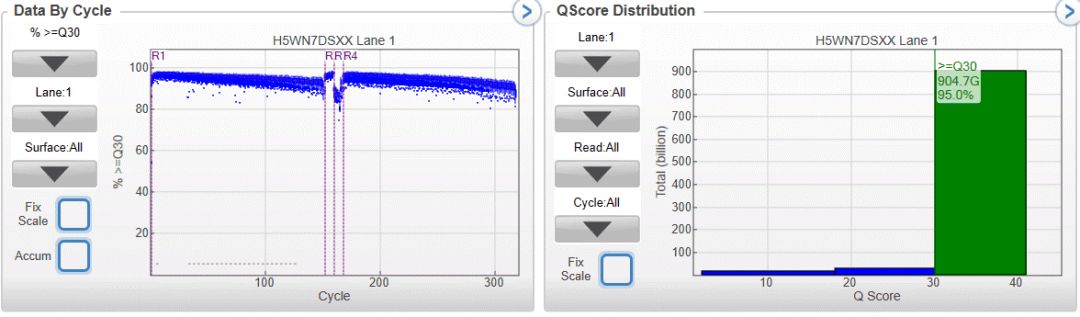
图5 NovaSeq6000平台S4试剂下机数据SAV图
看完小编整理的10个文库测序常见问题,你心中的疑惑是否已经有答案了呢~如果还有疑问,您还可以拨打安诺基因科服电话4008-986-980,我们随时为您解答~
参考文献
[1] Macconaill L E, Burns R T, NagA, et al. Unique, dual-indexed sequencing adapters with UMIs effectively eliminate index cross-talk and significantly improve sensitivity of massively parallel sequencing[J]. Bmc Genomics, 2018, 19(1):30.
文案:纯测序产品经理 齐钰
设计:胡珊珊