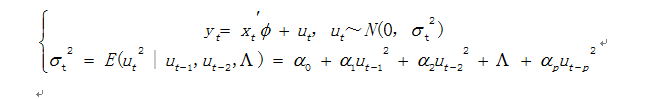
刘程浩
暨南大学金融系 经济学硕士
倡导“先理解业务,再优化分析方法。”
擅长应用数据分析方法进行分析并量化业务痛点,
采集信息并进行数学建模,制定解决方案并将之落地。
全文开头,我就用一个生活中常见的场景做一个铺垫。
大家小时候一定见过和听过老一辈的人说过如何煎中药吧,比方说“五碗水煎一碗药”什么的。可能各地说法不一,有的地方说三碗,有的说六碗……,但意思都差不多。那有个问题想问下大家:中药煎完第一轮后,剩下的药渣是否有“复煎”的价值呢?
其实,如果第一轮的煎药如果就煎的比较透的话,那么剩下的药渣只要一泡水,无论是颜色、气味都远远不如头一道那么浓的。甚至有时候我们较真的去煮上一轮发现,不仅颜色清澈,味道也很淡,更不要说喝了没啥效果了。也就是说,我们判断药渣是否还值得再次去“复煎”,或者说第一轮的煎药是否把药煎透了,是可以通过药渣的情况来决定的。
类似的,我们在通过数据建模之后,例如最常见的回归建模,到底模型是否很原由网好的提取了样本的规律信息了呢?我们除了看方程的可决系//www.58yuanyou.com数R方值外,对残差进行检验和分析也是一种很重要的方法。我在前段时间复盘过去项目时,看到笔记中记录了我接触的几个数据科学家对预测建模只重点关注残差的检验,忽略乃至跳过T检验和F检验的做法,有了更深的理解。
回归方程的建模目的是什么,就是找规律。所以就找规律而言,你得排除一个很大的风险,那就是这个方程对样本信息的代表性不高。因为造成这种情况的原因,要么是漏了某些信息(或者是变量),要么是模型或变量的表达方式不对。我们还是找一个具体的例来打比方会更有感觉写。
假设我们采集到某个菜园大棚内一天内温度和二氧化碳浓度www.58yuanyou.com的数据。这个时候我们会发现温度对植物的呼吸作用会有些影响,在一定的温度范围内温度越高二氧化碳浓度会越低。进行数学建模的话,可以根据散点图的形状,做直线、抛物线、对数曲线……的回归拟合。如果我们采用的是最常用的最小二乘法进行建模的话,以线性回归为例,我们会采用这样的形式,

这个时候好多人会问,怎么多出一个尾巴出来?其实,这个是有道理的。因为我们做一个直线去拟合散点图,是很难把全部点都用一条直线给串起来的,总会有些点没有在直线上。这种情况下,我们所有样本的信息就被分拆成2部分:一部分是可用规律来表示的,就是y=ax+b,另一部分就是不能用这个规律来表示的,也就是模型的误差(有的书叫做随机扰动,但都是一个意思)。那么我们就专门用来表征这个误原由网差。
如果我们的回归方程是理想的,那么这个误差是不能干扰整个线性方程。不然的话试想一下,如果对线性方程有影响,那么说明自变量就不止x一个,还包括误差本身。那么这个方程就不能叫做一元QalLfhucd线性方程了。在上面的例子中,如果我们发现因为光照时间也会影响温度,同时光合作用也会影响二氧化碳浓度,那么说明x(温度)作为自变量还不够彻底,线性方程的解释性不够充分。这样的话就肯定包含了光照时间的影响规律在里面,也就是说误差和应变量y之间有相关关系。
所以,为了满足上面误差项不能影响回归的要求,此时就应当满足以下的3个假设:
(1)误差项是一个期望值为零的随机变量,即E()=0。
(2)的方差都相同或者固定。
(3)误差项是一个服从正态分布的随机变量,且相互独立。
其实刚刚学回归建模的时候,我对这个检验假设也不是理解的很透,只是知道书上要求要做这方面的检验。经过几次客户的挑战之后,我才开始关注起这个问题,才有了后来的“咀嚼和消化”。
对于第一个假设,其实很好消化理解,我们可以从文字和图像的角度来进行解读。首先我们看“语文视角”。E()=0就意味着我们的回归方程拟合的好或足够理想,因为这说明除了温度以外的所有其他因素,它们对二氧化碳浓度所产生的总的随机扰动影响为0。你想啊,由于总误差项之和为0,那么其均值(期望)必然就等于0了。
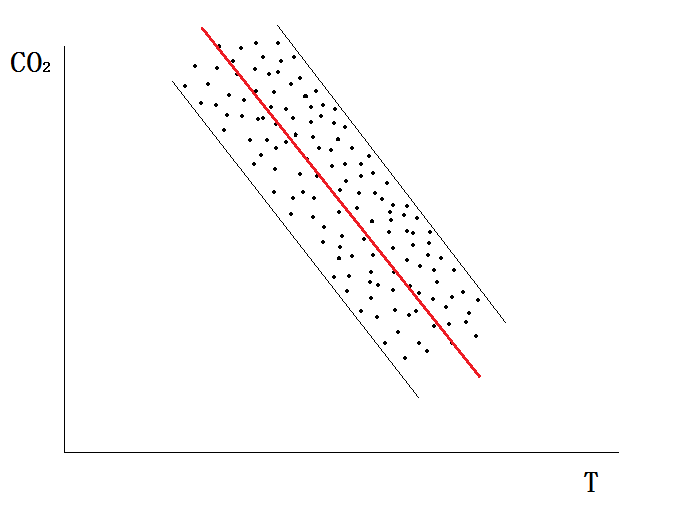
那我们再来看“美术视角”,如下图表现的那样,理想状态下回归方程拟合的好,那么这条回归直线会穿过样本点群中最具代表性的位置(满足MSE准则),如此一来虽然各个样本点有的分布在回归直线的两侧,有的可能就在回归直线上,但是它们各个点和回归直线之间的偏离总和却是为0的。如果样本采集的更凑巧一点的话,散点图和回归直线就好像一根电线的铜芯和绝缘橡胶皮的关系一样,绝缘胶皮扭成什么形状,铜芯就会扭成什么形状,回归方程(“铜芯”)的代表性最好。
对于第二个假设,同样也可以用“语文”和“美术”两个视角来理解。用“语文视角”来理解的话,就是无论温度越来越高/低,还是二氧化碳浓度越来越低/高,误差项都不会随之变化而变化,因为各个误差项之间都保持着固有的稳定性(方差固定)。
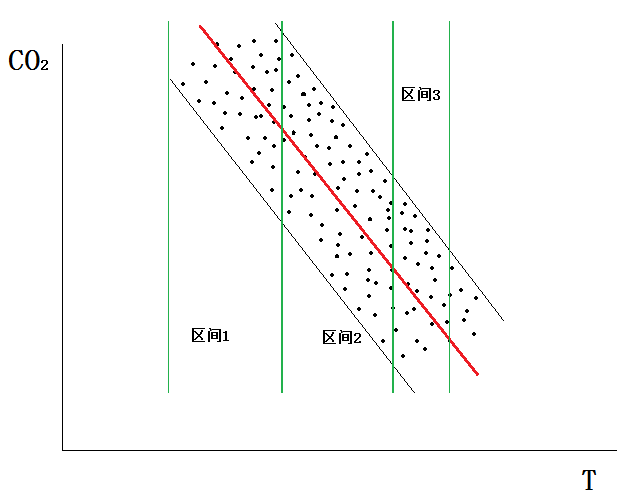
同样用“美术视角”来看如下图,如果我们任意按照温度方向,还是二氧化碳浓度方向,将归回方程和样本点群分成若干分区间,那么每个区间里的误差项的分散程度都一样(也就是方差固定)
对于第三个假设,则相对来说较为复杂些,但用“历史+语文视角”来解释可能更轻松些。关于误差项服从正态分布,得要追溯到伽利略所在的中世纪时代。那个时代科学家大都在天主教廷中任职,因为他们要观测很多天体并做研究。由于不同的望远镜,不同的观测条件,甚至不同的人用相同的正确的方法去观测天体,记录下来的结果都会存在观测误差。所以观测误差是无法避免的。但观测误差总有这样一个规律,也就是说只要不犯错误(系统性偏差),大的误差和小的误差总会出现的比较少,而大多数观测的误差都会集中在某个范围内。经过伽利略、拉普拉斯……高斯等等天文学家、数学家几百年的努力,终于被高斯证明了观测误差是服从正态分布的,并给出了正态分布的数学表达式。所以,第三个假设实际上要说明的就是“只要回归方程拟合的足够理想,即把所有影响二氧化碳浓度的因素都找对了,找齐了,那么剩下回归方程和样本点之间的各个误差项就是属于一种正态分布下的随机扰动了”
综上所述,既然有了关于误差项的假设,我们求出了回归方程后,就得去验证下误差项是不是真的服从些这个假设。不过说实话,对误差项的检验,并不是说一定要100%等于这个假设,因为现实中能够完美地服从者3个假设的回归方程是很难找到的。但这并不妨碍我们去检验在一定的概率下,这个回归方程所产生的误差项的特征,和3个假设的要求有较高的一致性。
最后,在实际应用中,是用残差e来代替的。只要计算出了残差,我们就可以用残差去做检验。
那检验残差是不是就得对这3个假设一个一个去检验呢?当然你可以一个一个去检验。但其实有一个比较快速全面的检验方法。就是利用正态分布的特点,将3个假设合并在一起一起检验。简单的来说,就是要检验残差e是否服从
其中0代表均值,代表固定的方差,N就代表了正态分布。在很多统计软件里都有对残差的检验,例如Excel可提供残差的参数,自行进行检验;SPSS、Eviews、R、SAS……都带有这些功能。
最后再补充一点就是,如果残差检验没有通过,该怎么办呢?其实前人已经总结了很多的方法:
如果只是没有通过均值为0的检验,但是通过了另外2个假设的检验。换句话说是残差分布服从,那么可以对原来的回归方程增加一个截距项即可。
也可以通过中心极限定理得到的“标准化残差”或根据杠杆参数换算得到的“学生化残差”,将之与自变量构成多维的散点图进行分析,推测是漏了变量还是用错了变量的表达式。
有时候极端值的出现也会影响回归方程的代表性,所以也要对其进行探索式的排除。
还有就是社会科学领域的回归模型,可能要更多的去研究业务流程,只有对业务流程吃的比较透,才会对建模的变量和参数选择有深刻的理解,才不会那么容易遗漏变量;或者才会更快的找到被遗漏的变量。
有时候残差还隐含了其他的规律,这时候对残差研究说不定还能找到其他的规律。例如著名的ARCH(p)模型,其核心思想就是误差项在t时刻的方差,依赖于时刻(t-p)的误差平方大小。