《医学统计学》通关必读
《医学统计学》
考试即将来临,
书还没有看完怎么办

某童鞋
小研,听说医学统计学要考试了,书还没有开始预习怎么办?天啦撸,有点慌!
小研
不要担心,小研早就把书本上比较重要的知识点都给你整理好了,赶紧跟小研一起学起来吧!

01
常见概念总结
1.总体(population)
指同质的研究对象中所有观察单位研究指标变量值的集合。总体通常限定于特定的时间与空间范围之内,且为有限数量的观察单位,称为有限总体;有时总体是假设的,没有时间和空间限制,观察单位数是无限的,称为无限总体。
2.样本(sample)
样本是从总体中随机抽取的具有代表性观察单位某项变量值的集合。抽样研究是从总体中随机抽取样本,目的是用样本指标推断总体特征。样本的可靠性:主要是使样本中每一观察单位确属同质总体。样本的代表性:使样本能充分反映总体的实际情况,要求抽样遵循随机化原则,目的是使每个观察单位被抽得的机会相等,避免主观取舍及偏性;还要保证足够的样本量,即保证足够的观察单位个数。
3.参数(parameter)
统计学上描述总体变量的特征称为参数。如总体均数、中位数和众数等描述总体的中心位置或集中趋势;总体标准差、极差、四分位数间距等描述总体的离散趋势等。但总体参数常属未知,而需以样本统计量来估计总体参数称为样本指标。
4.资料的类型
计量资料(measurement data)
又称定量资料(quantitative data)或数值变量(numerical variable)资料。为测定每个观察单位某项指标的大小而获得的资料。必须具备三个特征:其变量值有大小之分;一般有度量衡单位;变量值的获取通常需要借助测量工具。
计数资料(enumeration data)
又称定性资料(qualitative data)或无序分类变量(unordered categorical variable)资料。为将观察单位按某属性或类别分组计数,分组汇总各组观察单位数后而得到的资料。其变量值是定性的,表现为互不相容的属性或类别。分两种情形:
(1)二分类:如检查某单位工作人员血清的乙型肝炎表面抗原,以每个工作人员为观察单位,结果可报告为乙型肝炎表面抗原阴性或阳性两类。两类间相互对立,互不相容。
(2)多分类:如观察某人群的血型分布,以人为观察单位,结果可分为A型、B型、AB型与O型,为互不相容的SpupmkIXww四个类别。
等级资料(ranked data)
又称半定量资料(semi-quantitative data)或有序分类变量(ordered categorical variable)资料。为将观察单位按某种属性的不同程度分成等级后分组计数,分类汇总各组观察单位数后而得到的资料。其变量值具有半定量性质,表现为等级大小或属性程度。如观察某人群某血清反应,以人为观察单位,根据反应强度,结果可分-、、+、++、+++、++++六级。
5.正态分布(normal distribution)
正态分布图形特点:(1)f(x)≥0,即整个概率密度曲线都在x轴上方;(2)f(x)相对于x=u对称,并在x=u处取到最大值;(3)曲线的陡缓由决定,越大,越平缓,越小,曲线越陡峭;(4)当x趋于无穷时,曲线以x轴为渐近线。
正态分布的主要运用:医学参考值范围的制定和统计推断。
6.频数分布:
数值变量资料的统计描述包括集中趋势(cental tendency)和离散趋势(tendency of dispersion)。
正态分布:均数和标准差
偏态分布:中位数和四分位数间距
7.分类变量资料的统计描述:
率:表示在一定的时间或空间内某现象发生的频率或强度。
构成比:表示一种事物内部各组成部分所占的比重或分布。
相对比:是A、B两个有关联的指标之比,表示A与B的若干倍或百分之几。A、B两个指标的性质可以相同,也可以不同,但分母不能为零。
率的标准化:其基本思想是寻找一个统一的分布作为标准组,然后每个比较组均按该分布标准计算相应的率,所得到的率是相对于标准组的,故称为标准化率。
8.统计表与统计图:
统计表的基本结构:表头(位于表的上方)、标目、线条、数字。
统计图的基本结构:标题(位于图的下方)、标目、刻度、图域、图例。
常用统计图:条图、圆图、百分条图、线图、直方图、箱式图、散点图。
9.参数估计(parameterestimation)
用样本统计量去估计总体的参数。
抽样误差(samplingerror):指由于抽样的随机性引起的样本结果与总体真值之间的误差。
标准误(standard error):统计学上将样本统计量的标准差称为标准误,可反映抽样误差的大小,也是统计推断的基础。
点估计(pointestimate):用样本统计量的某个取值直接作为总体参数的估计值。
区间估计(intervalestimate):是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减估计误差得到。
置信区间(confidenceinterval):在区间估计中,由样本统计量所造成的总体参数的估计区间称为置信区间。
置信水平(confidencelevel):如果将构造置信区间的步骤重复多次,置信区间中包含总体参数真值的次数所占的比例为置信水平,也称为置信度或置信系数。其含义为:如果做了100次抽样,大概有95次找到的区间包含真值,而不是95%的可能落在区间,因为统计量不涉及概率问题。
10.P值的统计意义
P值的意思是指在原假设成立的条件下,观察到的实验差别是由于机遇所致的概率。P值越小越有理由拒绝原假设,认为不同组之间有差别的统计学证据就越充分。因此,P≤只能说明差异具有统计学意义,并不代表实际差异的大小。
11.统计推断包括两大部分,分别是参数估计和假设检验。
12.直线回归
建立一个描述应变量依自变量变化而变化的直线方程,并要求各点与该直线纵向距离的平方和为最小。直线回归是回归分析中最基本、最简单的一种,故又称简单回归
直线相关:又称线性相关,是指两列变量中的一列变量在增加(或减少)时,而另一列变量随之而增加(或减少),或这一列变量在增加时,而另一列变量则相应地减少。它们之间存在一种直线关系。直线相关可用直线拟合。
零相关:即没有关系,变量x和y之间的关系十分散乱,无法找出它们之间的联系,各现象间表现为相互独立。这种关系称为零相关。
决定系数:决定系数是指在x或y的总变异中,可以相互以直线关系说明的部分所占的比率。即随x的改变而呈线性改变的平方和,对y总变异平方和的比率等于随y的改变而呈线性改变的平方和占x变数总平方和的比率。
回归系数:即直线的斜率,在直线回归方程中用b 表示,b 的统计意义为X每增(减)一个单位时,Y平均改变b个单位。
相关系数r:用以描述两个随机变量之间线性相关关系的密切程度与相关方向的统计指标。
//////////
02
划重点:概念比较
1.标准差与标准误有何区别和联系?
区别:(1)含义不同: ①s描述个体变量值(x)之间的变异度大小,s越大,变量值(x)越分散;反之变量值越集中,均数的代表性越强。②标准误是描述样本均数之间的变异度大小,标准误 越大,样本均数与总体均原由网数间差异越大,抽样误差越大;反之,样本均数越接近总体均数,抽样误差越小。
(2)与n的关系不同: n增大时,①s→(恒定)。②标准误减少并趋于0(不存在抽样误差)。
(3)用途不同: ①s:表示x的变异度大小,计算cv,估计正常值范围,计算标准误等②:参数估计和假设检验。
联系: 二者均为变异度指标,样本均数的标准差即为标准误,标准差与标准误成正比。
2.标准正态分布(u分布)与t分布有何异同?
相同点:集中位置都为0,都是单峰分布,是对称分布,标准正态分布是t分布的特例(自由度是无限大时)
不同点:t分布是一簇分布曲线,t 分布的曲线的形状是随自由度的变化而变化,标准正态分布的曲线的形状不变,是固定不变的,因为它的形状参数为1。
3.95%的可信区间与95%参考范围的意义有何不同?
95%医学参考值范围,是指95%的正常人某项指标的范围;主要用于划分正常与异常的界限。正态分布公式为“均数1.96标准差(双侧)”,“均数+1.645标准差(单侧上限)”,“均数-1.645标准差(单侧下线)”。95%可信区间,是指这个区间包含总体均数的可能性是95%;总体均数是一个固定的值,是不会因为抽样而发生变化的,所以只能说上面的可信区间包含到这个总体均数的可能性是多少,而不能说总体均数落在这个区间内的可能性是95%。计算公式P1.96Sp.
4.假设检验的主要依据和推理方法是什么?
(1)基本思想:小概率原理的反证法思想
(2)主要依据:“小概率事件原理”,即“概率很小的事件在一次实验中不可能发生”的原理。
(3)推理方法:先假定H0成立,若由此导出一个不合理的现象出现(小概率事件出现),则拒绝H0,若没有出现不合理现象(小概率事件没有出现),则不能拒绝H0。
(4)应用条件:①样本来自正态总体(近似对称);②两样本均数比较时,要求两样本随对应的两总体方差相等,即方差齐性。
5.2x2表资料,如何正确使用卡方检验?
(1)当n≥40且所有T≥5时,用2x2表的检验的基本公式或者专用公式计算;
(2)当n≥40但有、1≤T<//www.58yuanyou.com;5时,需要用校正公式计算;
(3) n<40或T<1时,直接用Fisher确切概率计算概率。
6.I型错误与II型错误的区别及联系何在?
区别:I 型错误是 H0实际上是成立的,但由于抽样的原因,拒绝了H0,称“弃真”,概率用表示;II 型错误是实际上是不成立的,但假设检验没有拒绝它,称“存伪”,概率用 表示。
联系:当样本含量固定时,增大,减小;反之亦然;若同时减小和,则只能增大样本含量。
7.为什么不能用两两比较的t检验进行多个样本均数的比较?
用两两比较的 t 检验进行多个样本均数的比较时,需要进行多次检验,根据概率乘法法则,全部判 断正确的概率大大降低,犯 I 类错误的概率也就增大,甚至远远大于检验水准。因此,多组均数之间的 两两比较不能直接用 t 检验。取而代之的是,必须在方差分析www.58yuanyou.com结果为拒绝 H0接受 H1的基础上,进行多个样本的两两比较。
8.参数检验与非参数检验的比较:
参数检验:已知总体分布类型,对未知参数进行统计推断。依赖于特定分布类型,比较的是www.58yuanyou.com参数。
非参数检验:对总体分布类型不作严格要求。不受分布类型影响,比较的是总体分布位置。
9.两样本均数检验比较的t检验中,什么情况下做单侧检验?什么情况下做双侧检验?
若从专业知识判断一种方法的结果不可能低于或高于另一种方法的结果时,可用单侧检验;尚不 能从专业知识判断两种结果谁高谁低时,则用双侧检验。
10.t检验、u检验、X2检验用途及应用条件:
(1)t检验和u检验的应用条件相同:①样本来自正态总体(近似对称);②两样本均数比较时,要求两样本具有方差齐性,只是t检验的样本含量较小,一般n≤50。
(2)u检验的样本含量较大。它们主要用于:①判断某一样本均数是否来自于已知均数的总体;②两个不同样本均数是否来自均数不相等的总体。
(3)X2检验要求样本来自X2分布的总体,其用途颇广,可用于推断两个总体率或构成比之间有无差别、多个总体率或构成比之间有无差别、多个样本率间的多重比较、两个分类变量之间有无关联性及频数分布是何优度的检验等。
//////////
03
案例题怎么做?
假设检验的分析思路
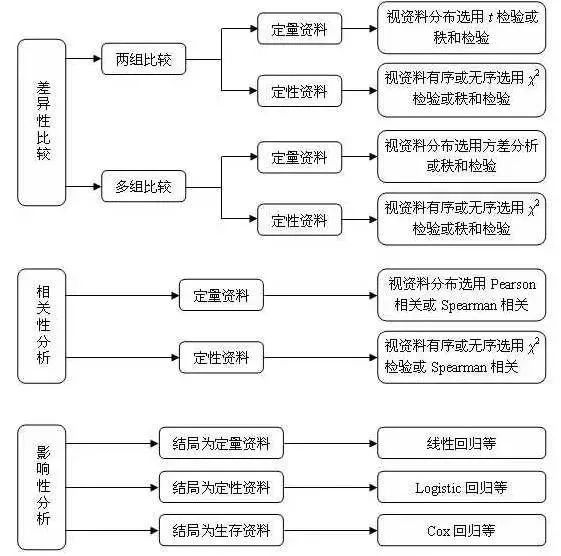
第一步:确定研究目的选择方法
不同研究目的采用的统计方法不同,常见的研究目的主要有三类:一是差异性研究,即比较组间均数、率等的差异,可用的方法有t检验、方差分析、2检验、非参数检验等。二是相关性分析,即分析两个或多个变量之间的关系,可用的方法有相关分析。三是影响性分析,即分析某一结局发生的影响因素,可用的方法有线性回归、logistic回归、Cox回归等。我们在考试中主要是对前两种方法的把握,其中以两独立样本T检验、单因素方差分析、完全随机设计2X2表的2检验、完全随机设计有序分类变量资料的秩和检验为重点。
第二步:明确类型,进一步确定方法
不同数据类型采用的统计方法也不同。定量资料可用的方法有t检验、方差分析、非参数检验、线性相关、线性回归等。分类资料可用的方法有2检验、对数线性模型、logistic回归等。上图简要列出了不同研究目的、不同数据类型常用的统计分析方法,同学们在考试中可根据题型的资料类型进行选择。
第三步:利用软件实现统计分析过程
SPSS中,不同的统计方法对应不同的命令,只要方法选定,便可通过对应的命令辅之以相应的选项实现统计结果的输出。这个过程是上机操作的内容,我们只需要了解操作流程。
第四步:统计结果的输出并分析数据
一般统计软件都会输出很多结果,需要从中选择自己需要的部分,并做出统计学结论。
最后小研祝大家考一个好成绩啦

-安徽中医药大学研究生院-
新媒体工作部
编辑:舒云峰
校对:朱超
责任编辑:张瑀
审核:张瑀