策划 | 蔡芳芳
作者 | Lukas Eder
编译 | 刘雅梦
编辑 | Linda
导读:从早期开始,编程语言设计者就有这样的愿望:设计一种语言,在这种语言中,告诉机器我们想要的结果是什么(WHAT),而不是如何(HOW)获得结果。SQL 可以做到这点。在 SQL 中,我们不关心数据库是如何检索信息的,就可以得到结果。本文介绍了使用声明式 SQL10 个不为人知的技巧。
介 绍
为了理解这 10 个 SQL 技巧的价值,首先需要了解下 SQL 语言的上下文。为什么我要在 Java 会议上讨论 SQL 呢?(我可能是唯一一个在 Java 会议上讨论 SQL 的了)下面讲下为什么:

从早期开始,编程语言设计者就有这种的愿望:设计一种语言,在这种语言中,告诉机器我们想要的结果是什么(WHAT),而不是如何(HOW)获得结果。例如,在 SQL 中,我们告诉计算机我们要“连接”(联接)用户表和地址表,并查找居住在瑞士的用户。我们不关心数据tpGAvzvBXC库将如何检索这些信息(比如,是先加载用户表呢,还是先加载地址表?这两个表是在嵌套循环中联接呢,还是使用 hashmap 联接?是先将所有数据加载到内存中,然后再过滤出瑞士用户呢,还是先加载瑞士地址?等等。)
与每个抽象一样,我们仍然需要了解数据库背后的基本原理,以帮助数据库在查询时做出正确的决策。例如,做如下事情是有必要:
- 在表之间建立合适的外键(这能告诉数据库每个地址都有一个对应的用户)
- 在搜索字段上添加索引:国家(这能告诉数据库可以在 O(log N) 而不是 O(N) 的复杂度内查找到特定的国家 )。
但是,一旦数据库和应用程序变得成熟之后,我们就可以把所有重要的元数据放在适当的位置上了,并且只需专注于业务逻辑即可。下面的 10 个技巧展示了,仅用几行声明式 SQL 就能编写强大惊人功能的能力,它不仅可以生成简单的输出,也可以生成复杂的输出。
1. 一切都是表
这是一条最微不足道的技巧,甚至不能说是真正的技巧,但它是全面理解 SQL 的基础:一切都是表:当我们看到这样的 SQL 语句时:
SELECT *
FROM person
……我们很快就能在 FROM 子句中找到 person 表。很好,那是一张表。但我们能意识到整个语句也是一张表吗?例如,我们可以这样写:
SELECT *
FROM (
SELECT *
FROM person
) t
现在,我们已经创建了一张所谓的“派生表”,即 FROM 子句中的嵌套 SELECT 语句。
这是微不足道的,但是如果仔细想想,它是相当优雅的。我们还可以在某些数据库(比如 PostgreSQL、SQL Server)中使用 VALUES 构造函数来创建临时内存表:
SELECT *
FROM (
VALUES(1),(2),(3)
) t(a)
临时表就这样产生了:
a
—
1
2
3
如果对应的数据库不支持该子句,则可以回到使用派生表上,比如,在 Oracle 中:
SELECT *
FROM (
SELECT 1 AS a FROM DUAL UNION ALL
SELECT 2 AS a FROM DUAL UNION ALL
SELECT 3 AS a FROM DUAL
) t
既然我们已经看到了 VALUES 和派生表实际上是相同的,那么从概念上,我们回顾一下 INSERT 语句,它有两种类型:
-- SQL Server, PostgreSQL, some others:
INSERT INTO my_table(a)
VALUES(1),(2),(3);
-- Oracle, many others:
INSERT INTO my_table(a)
SELECT 1 AS a FROM DUAL UNION ALL
SELECT 2 AS a FROM DUAL UNION ALL
SELECT 3 AS a FROM DUAL
在 SQL 中,一切都是表。当您在表中插入行时,实际上并不是插入单独的行。是插入整张表。在大多数情况下,大部分人只是碰巧插入了一张单行表,因此没有意识到 INSERT 真正做了什么。
一切都是表。在 PostgreSQL 中,甚至函数都是表:
SELECT *
FROM substring('abcde', 2, 3)
上面语句的结果是:
substring
———
bcd
如果你正在使用 Java 编程,那么可以使用 Java 8 Stream API 来做进一步的类比。考虑如下等价概念:
TABLE : Stream<Tuple<..>>
SELECT : map
DISTINCT : distinct
JOIN : flatMap
WHERE / HAVING : filter
GROUP BY : collect
ORDER BY : sorted
UNION ALL : concat
在 Java 8 中,“一切都是流”(至少在你开始使用流时是这样)。无论如何转换流,例如,使用 map 或 filter 转换,结果类型始终都是流。
我们写了一篇完整的文章来更深入地解释这一点,并将 Stream API 与 SQL 进行了对比:Common SQL Clauses and Their Equivalents in Java 8 Streams
如果你正在寻找“更好的流”(即,具有更多 SQL 语义的流),请查看 jOO,它一个将 SQL 窗口函数引入到 Java 中的开源库。
2. 使用递归 SQL 生成数据
公共表表达式(Common Table Expressions ,CTE,在 Oracle 中也叫做子查询分解),它是在 SQL 中声明变量的唯一方法(除了模糊 WINDOW 子句之外,WINDOW 子句也只有在 PostgreSQL 和 Sybase SQL 中可用)。
这是一个功能强大的概念。非常强大。考虑如下声明:
-- 表变量
WITH
t1(v1, v2) AS (SELECT 1, 2),
t2(w1, w2) AS (
SELECT v1 * 2, v2 * 2
FROM t1
)
SELECT *
FROM t1, t2
它的结果是:
v1 v2 w1 w2
-----------------
1 2 2 4
使用简单的 WITH 子句,我们可以指定一系列表变量(请记住:一切都是表),这些变量甚至可以是相互依赖的。
这很容易理解。它已经使得 CTE(Common Table Expressions)非常有用了,但是,真正了不起的是,它们还允许递归!考虑如下 PostgreSQL 示例:
WITH RECURSIVE t(v) AS (
SELECT 1 -- 种子行
UNION ALL
SELECT v + 1 -- 递归
FROM t
)
SELECT v
FROM t
LIMIT 5
它的结果是:
v
—
1
2
3
4
5
它是如何工作的呢?一旦你看懂了一些关键词,它就相对容易了。我们定义了一个公共表表达式,它恰好有两个 UNION ALL 子查询。
第一个 UNION ALL 子查询是我们通常所说的“种子行”。它“播种”(初始化)递归。它可以生成一行或多行,稍后我们将在这些行上递归。记住:一切都是表,所以递归将发生在整张表上,而不是单个行 / 值上。
第二个 UNION ALL 子查询在发生递归的地方。如果你仔细观察,会发现它从 t 中选择。也就是说,允许第二个子查询从我们即将声明的 CTE 中递归地选择。因此,它还可以访问使用它的 CTE 声明的列 v。
在我们的示例中,我们使用行 (1) 对递归进行种子处理,然后通过添加 v + 1 来进行递归。最后通过设置 LIMIT 5 来终止递归(需要谨防潜在的无限递归 ,就像使用 Java 8 的流一样)。
附注:图灵完备
递归 CTE 使得 SQL:1999 图灵完备,这意味着任何程序都可以用 SQL 编写!(如果你够疯狂的话)
一个经常出现在博客上的令人印象深刻的例子是:Mandelbrot 集,如
http://explainextended.com/2013/12/31/happy-new-year-5/ 所示。
WITH RECURSIVE q(r, i, rx, ix, g) AS (
SELECT r::DOUBLE PRECISION * 0.02, i::DOUBLE PRECISION * 0.02,
.0::DOUBLE PRECISION , .0::DOUBLE PRECISION, 0
FROM generate_series(-60, 20) r, generate_series(-50, 50) i
UNION ALL
SELECT r, i, CASE WHEN abs(rx * rx + ix * ix) <= 2 THEN rx * rx - ix * ix END + r,
CASE WHEN abs(rx * rx + ix * ix) <= 2 THEN 2 * rx * ix END + i, g + 1
FROM q
WHERE rx IS NOT NULL AND g < 99
)
SELECT array_to_string(array_agg(s ORDER BY r), '')
FROM (
SELECT i, r, substring(' .:-=+*#%@', max(g) / 10 + 1, 1) s
FROM q
GROUP BY i, r
) q
GROUP BY i
ORDER BY i
在 PostgreSQL 上运行上面的代码,我们将得到如下结果:
.-.:-.......==..*.=.::-@@@@@:::.:.@..*-. =.
...=...=...::+%.@:@@@@@@@@@@@@@+*#=.=:+-. ..-
.:.:=::*....@@@@@@@@@@@@@@@@@@@@@@@@=@@.....::...:.
...*@@@@=.@:@@@@@@@@@@@@@@@@@@@@@@@@@@=.=....:...::.
.::@@@@@:-@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@..-:@=*:::.
.-@@@@@-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.=@@@@=..:
...@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@@@@@:..
....:-*@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@::
.....@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-..
.....@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-:...
.--:+.@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@...
.==@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-..
..+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-#.
...=+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
-.=-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..:
.*%:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@-
. ..:... ..-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
.............. ....-@@@@@@@@@@@@@@@@@@@@@@@@@@@原由网@@@@@@@@@@@@@@@@@@@@@@@@%@=
.--.-.....-=.:..........原由网::@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
..=:-....=@+..=.........@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:.
.:+@@::@==@-*:%:+.......:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
::@@@-@@@@@@@@@-:=.....:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:
.:@@@@@@@@@@@@@@@=:.....%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
.:@@@@@@@@@@@@@@@@@-...:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:-
:@@@@@@@@@@@@@@@@@@@-..%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
%@@@@@@@@@@@@@@@@@@@-..-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
@@@@@@@@@@@@@@@@@@@@@::+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@+
@@@@@@@@@@@@@@@@@@@@@@:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
@@@@@@@@@@@@@@@@@@@@@@-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
印象是不是非常深刻?
3. 累计计算
这个博客 有很多累计计算的示例。它们是学习高级 SQL 最有教育意义的示例之一,因为至少有十几种方法可以实现累计计算。
在概念上,累计计算很容易理解。
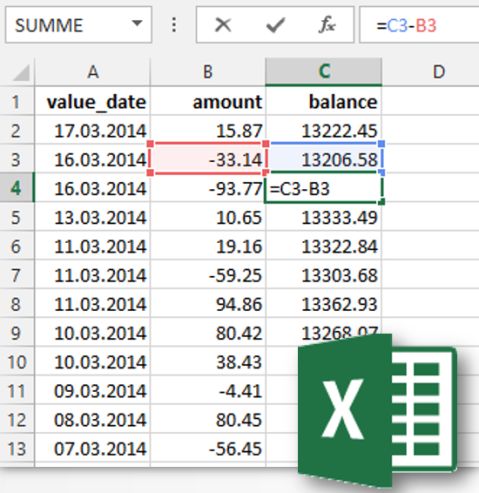
在 Microsoft Excel 中,我们只需计算前两个(或后两个)值的和(或差),然后使用可用的十字光标将该公式拉过整个电子表格。我们在电子表格中“运行”这个总数。即一个“累计”。
在 SQL 中,最好的方法是使用 窗口函数,这也是该博客多次讨论的另一主题。
窗口函数是一个功能强大的概念,一开始可能不太容易理解,但事实上,它们非常非常简单:
窗口函数是在相对当前行而言的一个子集上的聚合/排序,当前行由 SELECT 转换。
就是这样简单!
它本质上的意思是,一个窗口函数可以对当前行的“上”或“下”行执行计算。然而,与普通的聚合和 GROUP BY 不同,它们不转换行,这使得它们非常有用。
语法总结如下,个别部分是可选的:
function(...) OVER (
PARTITION BY ...
ORDER BY ...
ROWS BETWEEN ... AND ...
)
因此,我们可以使用任何类型的函数(稍后我们将介绍此类函数的示例),后面紧跟其后的是 OVER 子句,该子句指定窗口。即,这个 OVER 子句定义如下:
- PARTITION :窗口只考虑与当前行在同一分区中的行
- ORDER:窗口排序可以独立于我们选择的内容
- ROWS(或 RANGE )框架定义:窗口可以被限制在固定数量的行的“前面”和“后面”。
这就是窗口函数的全部功能。
那么它又是如何帮助我们累计计算的呢?考虑以下数据:
| ID | VALUE_DATE | AMOUNT | BALANCE |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | 99.17 | 19985.81 |
| 9981 | 2014-03-16 | 71.44 | 19886.64 |
| 9979 | 2014-03-16 | -94.60 | 19815.20 |
| 9977 | 2014-03-16 | -6.96 | 19909.80 |
| 9971 | 2014-03-15 | -65.95 | 19916.76 |
假设 BALANCE 是我们想从 AMOUNT 中计算出来的
直观视觉上,我们可以立即看出以下情况是成立的:
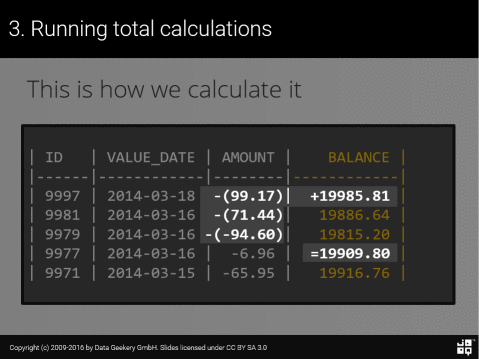
因此,使用简单的英语,任何余额都可以用以下伪 SQL 表示:
TOP_BALANCE – SUM(AMOUNT) OVER (
“all the rows on top of the current row”
)
在真正的 SQL 中,可以这样写:
SUM(t.amount) OVER (
PARTITION BY t.account_id
ORDER BY t.value_date DESC,
t.id DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND 1 PRECEDING
)
说明:
- 分区计算每个银行帐户的总和,而不是整个数据集的总和
- 排序将确保事务在求和之前(在分区内)是有序的
- 在求和之前,rows 子句只考虑前面的行(在分区内,给定顺序)
所有这些都发生在内存中的数据集上,该数据集由我们通过 FROM .. WHERE 子句选择出来,因此速度非常快。
插 曲
在我们开始讨论其他精彩技巧之前,先考虑一下:我们已经学习了
- (递归)公共表表达式(CTE)
- 窗口函数
这两个功能都是:
- 非常棒
- 功能极其强大
- 声明式
- SQL 标准的一部分
- 适用于大多数流行的 RDBMS(除了 MySQL)
- 非常重要的构建块
如果能从本文中得出什么结论,那就是我们应该完全了解现代 SQL 的这两个构建块。为什么呢?因为:

4. 查找最大无间隔序列
Stack Overflow 有一个非常好的功能:徽章,它可以激励人们尽可能长时间地呆在他们的网站上。

就规模而言,你可以看到我有多少徽章。
你要怎么计算这些徽章呢?让我们看看“爱好者”和“狂热者”。这些徽章是颁发给那些在他们平台上连续停留一定时间的人。无论结婚纪念日或是妻子生日,你都必须登录,否则计数器将再次从零开始。
当我们进行声明式编程时,是不需要维护任何状态和内存计数器的。现在,我们想用在线分析 SQL 的形式来表达这一点。即,考虑如下数据:
| LOGIN_TIME |
|---------------------|
| 2014-03-18 05:37:13 |
| 2014-03-16 08:31:47 |
| 2014-03-16 06:11:17 |
| 2014-03-16 05:59:33 |
| 2014-03-15 11:17:28 |
| 2014-03-15 10:00:11 |
| 2014-03-15 07:45:27 |
| 2014-03-15 07:42:19 |
| 2014-03-14 09:38:12 |
那没什么用。我们从时间戳中删除小时。这很简单:
SELECT DISTINCT
cast(login_time AS DATE) AS login_date
FROM logins
WHERE user_id = :user_id
得到的结果是:
| LOGIN_DATE |
|------------|
| 2014-03-18 |
| 2014-03-16 |
| 2014-03-15 |
| 2014-03-14 |
现在,我们已经学习了窗口函数,我们只需为每个日期添加一个简单的行www.58yuanyou.com数即可:
SELECT
login_date,
row_number OVER (ORDER BY login_date)
FROM login_dates
结果如下:
| LOGIN_DATE | RN |
|------------|----|
| 2014-03-18 | 4 |
| 2014-03-16 | 3 |
| 2014-03-15 | 2 |
| 2014-03-14 | 1 |
还是很容易的吧。现在,如果我们不单独选择这些值,而是减去它们,会发生什么?
SELECT
login_date -
row_number OVER (ORDER BY login_date)
FROM login_dates
将会得到如下结果:
| LOGIN_DATE | RN | GRP |
|------------|----|------------|
| 2014-03-18 | 4 | 2014-03-14 |
| 2014-03-16 | 3 | 2014-03-13 |
| 2014-03-15 | 2 | 2014-03-13 |
| 2014-03-14 | 1 | 2014-03-13 |
真的。很有趣。所以,14–1=13,15–2=13,16–3=13,但是 18–4=14。没有人能比 Doge 说得更好了:

有一个关于这种行为的简单示例:
- ROW_NUMBER 没有间隔,这就是它的定义
- 但是,我们的数据有间隔
所以,当我们从一个非连续日期的“gapful”序列中减去一个连续整数的“gapless”序列时,我们将得到连续日期中每个“gapless”子序列的相同日期,并且它是一个新的日期,其中日期序列是有间隔的。
嗯。
这意味着我们现在可以简单地 GROUP BY 该任意日期值了:
SELECT
min(login_date), max(login_date),
max(login_date) -
min(login_date) + 1 AS length
FROM login_date_groups
GROUP BY grp
ORDER BY length DESC
我们做到了。最大的连续无间隔序列被找到了:
| MIN | MAX | LENGTH |
|------------|------------|--------|
| 2014-03-14 | 2014-03-16 | 3 |
| 2014-03-18 | 2014-03-18 | 1 |
完整的查询如下:
ITH
login_dates AS (
SELECT DISTINCT cast(login_time AS DATE) login_date
FROM logins WHERE user_id = :user_id
),
login_date_groups AS (
SELECT
login_date,
login_date - row_number OVER (ORDER BY login_date) AS grp
FROM login_dates
)
SELECT
min(login_date), max(login_date),
max(login_date) - min(login_date) + 1 AS l原由网ength
FROM login_date_groups
GROUP BY grp
ORDER BY length DESC

最后,没那么难吧?当然,最主要的是有了这个想法,但是查询本身真的非常简单优雅。没有比这更简洁的方法来实现一些命令式算法了。
5. 求序列的长度
在前面,我们看到了一系列连续的值。这很容易处理,因为我们可以滥用整数的连续性。如果一个“序列”的定义不那么直观,而且除此之外,几个序列包含相同的值呢?考虑以下数据,其中 LENGTH 是要计算的每个序列的长度:
| ID | VALUE_DATE | AMOUNT | LENGTH |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | 99.17 | 2 |
| 9981 | 2014-03-16 | 71.44 | 2 |
| 9979 | 2014-03-16 | -94.60 | 3 |
| 9977 | 2014-03-16 | -6.96 | 3 |
| 9971 | 2014-03-15 | -65.95 | 3 |
| 9964 | 2014-03-15 | 15.13 | 2 |
| 9962 | 2014-03-15 | 17.47 | 2 |
| 9960 | 2014-03-15 | -3.55 | 1 |
| 9959 | 2014-03-14 | 32.00 | 1 |
是的,你猜对了。“序列”是由连续(按 ID 排序)行且具有相同的 SIGN(AMOUNT) 这一事实来定义的。再次检查如下的数据格式:
| ID | VALUE_DATE | AMOUNT | LENGTH |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | +99.17 | 2 |
| 9981 | 2014-03-16 | +71.44 | 2 |
| 9979 | 2014-03-16 | -94.60 | 3 |
| 9977 | 2014-03-16 | - 6.96 | 3 |
| 9971 | 2014-03-15 | -65.95 | 3 |
| 9964 | 2014-03-15 | +15.13 | 2 |
| 9962 | 2014-03-15 | +17.47 | 2 |
| 9960 | 2014-03-15 | - 3.55 | 1 |
| 9959 | 2014-03-14 | +32.00 | 1 |
我们怎么做呢?很“简单”