PaperWeekly 原创 作者 | 海晨威
研究方向 | 自然语言处理
2020 年的 Moco 和 SimCLR 等,掀起了对比学习在 CV 领域的热潮,2021 年的 SimCSE,则让 NLP 也乘上了对比学习的东风。下面就尝试用 QA 的形式挖掘其中一些细节知识点,去更好地理解对比学习和 SimCSE。
- 如何去理解对比学习,它和度量学习的差别是什么?
- 对比学习中一般选择一个 batch 中的所有其他样本作为负例,那如果负例中有很相似的样本怎么办?
- infoNCE loss 如何去理解,和 CE loss有什么区别?
- 对比学习的 infoNCE loss 中的温度常数的作用是什么?
- SimCSE 中的 dropout mask 指的是什么,dropout rate 的大小影响的是什么?
SimCSE 无监督模式下的具体实现流程是怎样的,标签生成和 loss 计算如何实现?
如何去理解对比学习,它和度量学习的差别是什么?
对比学习的思想是去拉近相似的样本,推开不相似的样本,而目标是要从样本中学习到一个好的语义表示空间。
论文[1] 给出的 “Alignment and Uniformity on the Hypersphere”,就是一个非常好的去理解对比学习的角度。
好的对比学习系统应该具备两个属性:Alignment和Uniformity(参考上图)。
所谓“Alignment”,指的是相似的例子,也就是正例,映射到单位超球面后,应该有接近的特征,也即是说,在超球面上距离比较近;
所谓“Uniformity”,指的是系统应该倾向在特征里保留尽可能多的信息,这等价于使得映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。分布均匀意味着两两有差异,也意味着各自保有独有信息,这代表信息保留充分(参考自 [2])。
度量学习和对比学习的思想是一样的,都是去拉近相似的样本,推开不相似的样本。但是对比学习是无监督或者自监督学习方法,而度量学习一般为有监督学习方法。而且对比学习在 loss 设计时,为单正例多负例的形式,因为是无监督,数据是充足的,也就可以找到无穷的负例,但如何构造有效正例才是重点。
而度量学习多为二元组或三元组的形式,如常见的 Triplet 形式(anchor,positive,negative),Hard Negative 的挖掘对最终效果有较大的影响。
对比学习中一般选择一个 batch 中的所有其他样本作为负例,那如果负例中有很相似的样本怎么办?
在无监督无标注的情况下,这样的伪负例,其实是不可避免的,首先可以想到的方式是去扩大语料库,去加大 batch size,以降低 batch 训练中采样到伪负例的概率,减少它的影响。
另外,神经网络是有一定容错能力的,像伪标签方法就是一个很好的印证,但前提是错误标签数据或伪负例占较小的比例。
PS:也确有人考虑研究过这个问题,可以参考论文 [3][4]。
infoNCE loss 如何去理解,和 CE loss 有什么区别?
infoNCE loss全称 info Noise Contrastive Estimation loss,对于一个 batch 中的样本 i,它的 loss 为:
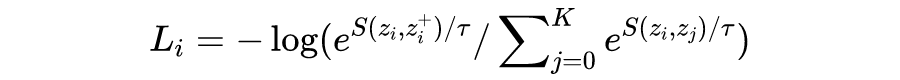
要注意的是,log 里面的分母叠加项是包括了分子项的。分子是正例对的相似度,分母是正例对+所有负例对的相似度,最小化 infoNCE loss,就是去最大化分子的同时最小化分母,也就是最大化正例对的相似度,最小化负例对的相似度。
上面公式直接看可能没那么清晰,可以把负号放进去,分子分母倒过来化简一下就会很明了了。
CE loss,Cross Entropy loss,在输入 p 是 softmax 的输出时:
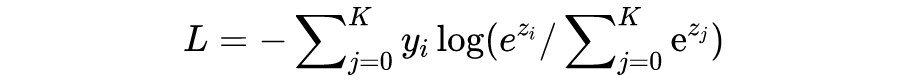
在分类场景下,真实标签 y 一般为 one-hot 的形式,因此,CE loss 可以简化成(i 位置对应标签 1):
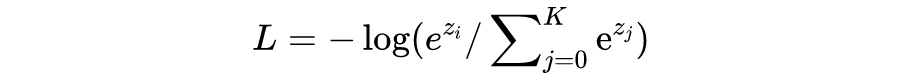
看的出来,info NCE loss 和在一定条件下简化后的 CE loss 是非常相似的,但有一个区别要注意的是:
infoNCE loss 中的 K 是 batch 的大小,是可变的,是第 i 个样本要和 batch 中的每个样本计算相似度,而 batch 里的每一个样本都会如此计算,因此上面公式只是样本 i 的 loss。
CE loss 中的 K 是分类类别数的大小,任务确定时是不变的,i 位置对应标签为 1 的位置。不过实际上,infoNCE loss 就是直接可以用 CE loss 去计算的。
注:1)info NCE loss 不同的实现方式下,它的计算方式和 K 的含义可能会有差异;2)info NCE loss 是基于 NCE loss 的,对公式推导感兴趣的可以参考 [5]。
对比学习的 infoNCE loss 中的温度常数 t 的作用是什么?
论文[6]给出了非常细致的分析,知乎博客 [7]则对论文 [6]做了细致的解读,这里摘录它的要点部分:
温原由网度系数的作用是调节对困难样本的关注程度: 越小的温度系数越关注于将本样本和最相似的困难样本分开,去得到更均匀的表示。然而困难样本往往是与本样本相似程度较高的,很多困难负样本其实是潜在的正样本,过分强迫与困难样本分开会破坏学到的潜在语义结构,因此,温度系数不能过小。
考虑两个极端情况,温度系数趋向于 0 时,对比损失退化为只关注最困难的负样本的损失函数;当温度系数趋向于无穷大时,对比损失对所有负样本都一视同仁,失去了困难样本关注的特性。
还有一个角度:
可以把不同的负样本想像成同极点电荷在不同距离处的受力情况,距离越近的点电荷受到的库伦斥力更大,而距离越远的点电荷受到的斥力越小。
对比损失中,越近的负例受到的斥力越大,具体的表现就是对应的负梯度值越大 [4]。这种性质更有利于形成在超球面均匀分布的特征。
对照着公式去理解:
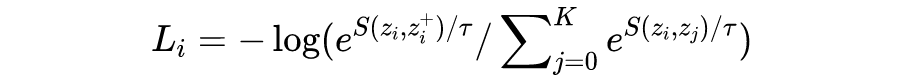
当温度系数很小时,越相似也即越困难的负例,对应的 就会越大,在分母叠加项中所占的比重就会越大,对整体 loss 的影响就会越大,具体的表现就是对应的负梯度值越大 [7]。
当然,这仅仅是提供了一种定性的认识,定量的认识和推导可以参见博客 [7]。
SimCSE 中的 dropout mask 指的是什么,dropout rate 的大小影响的是什么?
一般而言的 mask 是对 token 级别的 mask,比如说 BERTisxNtBR MLM 中的 mask,batch 训练时对 padding 位的 mask 等。
SimCSE 中的 dropout mask,对于 BERT 模型本身,是一种网络模型的随机,是对网络参数 W 的 mask,起到防止过拟合的作用。
而 SimCSE 巧妙的把它作为了一种 noise,起到数据增强的作用,因为同一句话,经过带 dropout 的模型两次,得到的句向量是不一样的,但是因为是相同的句子输入,最后句向量的语义期望是相同的,因此作为正例对,让模型去拉近它们之间的距离。
在实现上,因为一个 batch 中的任意两个样本,经历的 dropout mask 都是不一样的,因此,一个句子过两次 dropout,SimCSE 源码中实际上是在一个 batch 中实现的,即 [a,a,b,b...] 作为一个 batch 去输入。
dropout rate 大小的影响,可以理解为,这个概率会对应有 dropout 的句向量相对无 dropout 句向量,在整个单位超球体中偏移的程度,因为 BERT 是多层的结构,每一层都会有 原由网dropout,这些 noise 的累积,会让句向量在每个维度上都会有偏移的,只是 p 较小的情况下,两个向量在空间中仍较为接近,如论文所说,“keeps a steady alignment”,保证了一个稳定的对齐性。
SimCSE 无监督模式下的具体实现流程是怎样的,标签生成和 loss 计算如何实现?
这里用一个简单的例子和 Pytorch 代码来说明:
前向句子 embedding 计算:
假设初始输入一个句子集 sents = [a,b],每一句要过两次 BERT,因此复制成 sents = [a,a,b,b]。
sents 以 batch 的形式过 BERT 等语言模型得到句向量:batch_emb = [a1,a2,b1,b2]。
batch 标签生成:
标签为 1 的地方是相同句子不同 embedding 对应的位置。
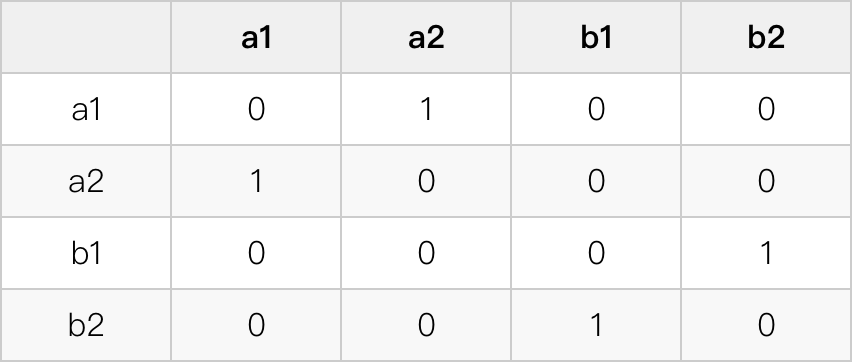
pytorch 中的 CE_loss,要使用一维的数字标签,上面的 one-hot 标签可转换成:[1,0,3,2]。
可以把 label 拆成两个部分:奇数部分 [1,3...] 和偶数部分 [0,2...],交替的每个奇数在偶数前面。因此实际生成的时候,可以分别生成两个部分再 concat 并 reshape 成一维。
pytorch 中 label 的生成代码如下:
# 构造标签
batch_size = batch_emb.size( 0)
y_true = torch.cat([torch.arange( 1,batch_size,step= 2,dtype=torch.long).unsqueeze( 1),
torch.arange( 0,batch_size,step= 2,dtype=twww.58yuanyou.comorch.long).unsqueeze( 1)],
dim= 1).reshapisxNtBRe([batch_size,])
score 和 loss计算:
batch_emb 会先 norm,再计算任意两个向量之间的点积,得到向量间的余弦相似度,维度是:[batch_size, batch_size]。
但是对角线的位置,也就是自身的余弦相似度,需要 mask 掉,因为它肯定是 1,是不产生 loss 的。
然后,要除以温度系数,再进行 loss 的计算,loss_func 采用 CE loss,注意 CE loss 中是自带 softmax 计算的。
# 计算score和loss
norm_emb = F.normalize(batch_emb, dim= 1, p= 2)
sim_score = torch.matmul(norm_emb, norm_emb.transpose( 0, 1))
sim_score = sim_score - torch.eye(batch_size) * 1e12
sim_score = sim_score * 20# 温度系数为 0.05,也就是乘以20
loss = loss_func(sim_score, y_true)
完整代码:
loss_func = nn.CrossEntropyLoss
defsimcse_loss(batch_emb):
"""用于无监督SimCSE训练的loss
"""
# 构造标签
batch_size = batch_emb.size( 0)
y_true = torch.cat([torch.arange( 1, batch_size, step= 2, dtype=torch.long).unsqueeze( 1),
torch.arange( 0, batch_size, step= 2, dtype=torch.long).unsqueeze( 1)],
dim= 1).reshape([batch_size,])
# 计算score和loss
norm_emb = F.normalize(batch_emb, dim= 1, p= 2)
sim_score = torch.matmul(norm_emb, norm_emb.transpose( 0, 1))
sim_score = sim_score - torch.eye(batch_size) * 1e12
sim_score = sim_score * 20
loss = loss_func(sim_score, y_true)
returnloss
注:看过论文源码 [8]的同学可能会发现,这个和论文源码中的实现方式不一样,论文源码是为了兼容无监督 SimCSE 和有监督 SimCSE,并兼容有 hard negative 的三句输入设计的,因此实现上有差异。
看过苏神源码[9]的同学也会发现,构造标签的地方不一样,那是因为 keras 的 CE loss 用的是 one-hot 标签,pytorch 用的是数字标签,但本质一样。
参考文献
[1] Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
[3] Debiased Contrastive Learning
[4] ADACLR: Adaptive Contrastive Learning Of Representation By Nearest Positive Expansion
[6] Understanding the Behaviour of Contrastive Loss
[8] https://github.com/princeton-nlp/SimCSE
[9] https://github.com/bojone/SimCSE
更多阅读
# 投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是 最新论文解读,也可以是 学术热点剖析、 科研心得或 竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。