听李宏毅点评GPT-3:来自猎人暗黑大陆的模型

编者按:提起李宏毅老师,熟悉 AI 的读者朋友一定不会陌生。在 GPT-3 推出之后,李宏毅老师专门讲解了这个非同凡响的模型,称之为 “来自猎人暗黑大陆的模型”。
出于知识传播目的,“数据实战派” 根据该讲解视频将李宏毅老师的见解整理成文,有基于原意的删改:
OpenAI 发表了新的巨大的 language model,在此之前 OpenAI 已经发表了 GPT,还有轰动一时的 GPT-2,现在到了 GPT-3(GPT-3 的论文题目为 Language Models are Few-Shot Learners)。
那么,GPT-3 跟 GPT-2 有什么不同呢?基本上没有什么不同,它们都是 language model。GPT-3 神奇的地方是什么呢?神奇的地方是它太过巨大。
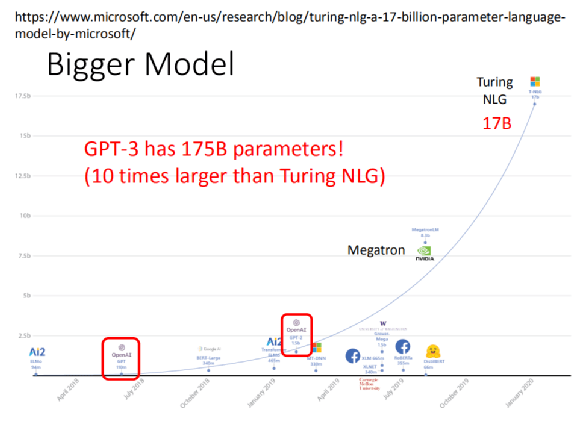
在它之前,最大的 model 是 Turing NLG,在之前已经给大家看过一个 model 大小的比较图,包括从最早的 ELMo 到后来的 Turing NLG 。Turing NLG 已经非常的巨大,它有 17 个 billion 的参数,远超之前 OpenAI 发表的 GPT-2 和最早的 GPT。
而第三代的 GPT 有多大?它是 Turing NLG 的 10 倍,它有 175 个 billion 的参数,也就是 1750 亿个参数,你根本没有办法把它画在这一张图上。

假设我们用长度来代表参数量,ELMO 的参数量是一个长 30 公分的尺,则 GPT-3 约是 ELMO 的 2000 倍。30 公分 휠00 是多少?它比台北 101 还要高。

如果说巨大的东西都是来自暗黑大陆,GPT-3 就像是来自于暗黑大陆的模型。
1详解 GPT 系列的目标
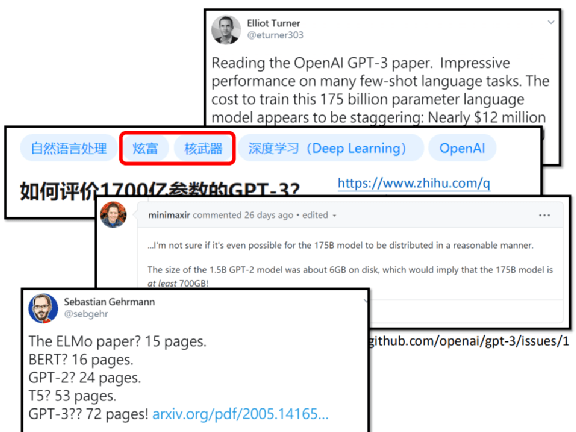
网络上有各式各样的讨论。有人问,商用的 cloud computing platform 训练一个 GPT-3,要花多少钱?要花 1200 万美金,大概 4 亿台币。在知乎上面有关 GPT-3 的讨论,甚至被打上了炫富跟核武器的标签。
而且,GPT-2 有 1.5 个 billion 的参数,就 6GB 了,175 个 billion 的参数大概 700GB,搞不好连下载下来都有困难。
GPT-3 的 paper 也很长,ELMO 有 15 页,BERT 有 16 页,GPT-2 有 24 页,T5 有 53 页,而 GPT-3 有 72 页。
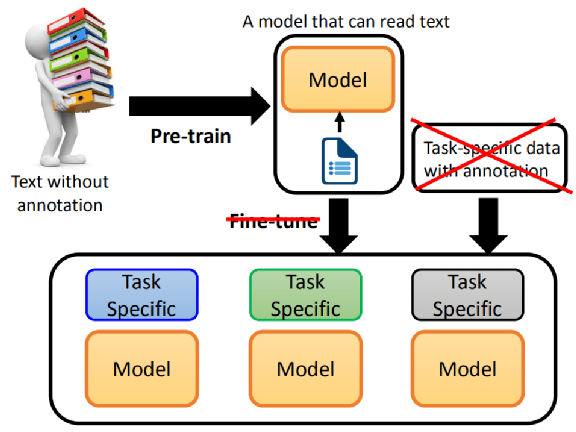
那么,GPT 这一系列的工作想要实现什么?
它想要做的事情是 —— They will shut the learning。
在过去,我们使用 BERT+pre-train model 时,先 pre-train model,接下来为每一个任务准备与这些任务相关的资料,根据这些任务的专业资料进行 fine-tune,会有每一个任务的 model。
所以,如果你要用 BERT 解决任务,其实还是要收集一些资料的,BERT 并没有办法直接去解这些任务,包括 QA 任务还是 NLI 任务。
GPT 系列的工作,就是在问:我们能不能拿掉 fine-tune 这个步骤,能不能 pre-train 一个模型,这个模型就可以直接解决 downstream task,连 fine-tune 都不需要。

GPT 系列的终极目标也许就是这样。
在进行英文能力考试时,我们怎么告诉考生如何回答试题?其实只需要给一个题型的说明。
比如告诉考生,选择最适合题意的字或词,然后也许再多给一个范例,告诉考生这个题目如果真的要解,大概如何解,就结束了。考生只看了题型说明和一点范例,就知道怎么回答接下来的问题。GPT 系列想要做的就是类似的事情。

更具体一些,GPT 做的事情是这个样子,它有三个可能:Few-shot Learning,One-shot Learning,Zero-shot Learning。
在 Few-shot Learning 情况下,首先给 GPT 的 model 看一个句子,这个句子是任务的说明。如果是翻译,任务的说明就是 translate English to French,希望机器能够看得懂这个句子的意思。然后接下来给它几个范例,告诉它 sea otter 就是翻译成这样,Plush girafe 就是翻译成这样。
接下来开始考试,问它 cheese 应该翻译成什么。这个是 Few-shot Learning,即 example 的部分可以提供不止一个 example。
如果是 One-shot Learning,可能就非常接近人类在英文能力考试中的状况了,只给你一段题型说明,再给一个例子,接下来就要自己回答问题。
最疯狂的是 Zero-shot Learning,直接给一个题目的叙述,然后回答问题。不知道一个 language model 有没有可能做到,你交待它 translate English to French,在没有额外训练的状况下,它知道什么叫做 translate English to French。接下来给它一句英文,它就自动知道要输出法文,这显然是很大的挑战。
也许 One-shot Learning 比较接近现实能够实现的情况。机器www.58yuanyou.com至少看到一个例子,One-shot Learning 还是比较有机会。
这里需要再提醒一下,在 GPT-3 中,它的 Few-shot Learning 跟一般所谓的 Few-shot Learning 是不一样的。一般所谓的 Few-shot Learning,是给机器少量的训练资料,用少量的训练资料去 fine-tune model。但在 GPT-3 中没有 fine-tune 这回事,所谓的 Few-shot Learning,所谓的一点点 example,是直接当做 GPT model 的输入,给 GPT 读过这些句子,它要自动知道怎么解接下来的问题。
在这个过程中完全没有调整 model,完全没有所谓的 gradient descent,直接输入文字当作指示,这些文字就让它知道接下来要做什么,期待它看到这些题型的说明和范例,就可以真的回答问题。
在 GPT-3 这篇 paper 里,他们把这种学习的方式叫做 “in-context Learning”。
2GPT-3 的神奇之处
那么,GPT-3 这篇 paper 表现如何?硕大无朋的 GPT-3 表现如何?
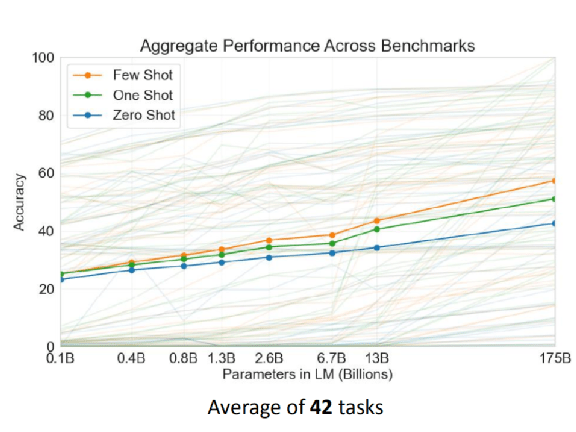
上图是论文中所用的 42 个 task 的平均情况。数目正好是 42,这是个很巧的数字,我们知道 42 是生命的意义(《银河系漫游指南》中的原由网计算机用了 N 久的时间得出的结果),不知道这里的 42 个任务是不是刻意选择出来的。
上图纵轴是正确率,横轴是 model 的大小,从 0.1 billion 一直到 175 billion。蓝色是 Zero Shot,绿色是 One Shot,橙色是 Few Shot。可以看到随着 model 越来越大,不管是 Few-shot Learning、One-shot Learning 还是 Zero-shot Learning 的正确率,都越来越高。
当然有人可能会质疑,为了增加这么一点点正确率,用了大概 10 倍的参数量到底值不值得?至少这个图显示,比较大的 model 确实是有好处的,至于大了 10 倍,只是增加这样的正确率,到底能不能够接受、划不划算,这是一个见仁见智的问题。
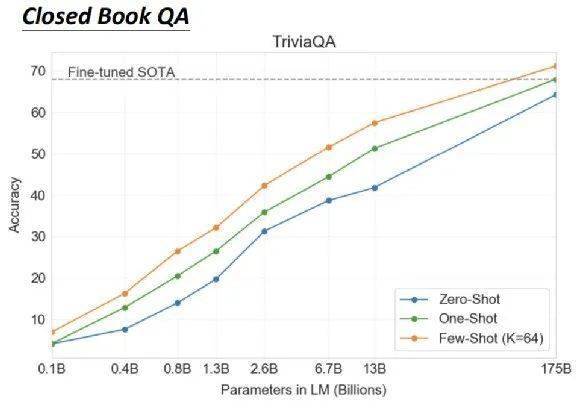
接下来就讲 GPT-3 的几个神奇之处。首先,它可以做 Closed Book QA。在 question answering 中,有一个 knowledge source,有一个 question,然后要找出 aDianxiRdkAnswer。如果机器在回答问题的时候可以看 knowledge source,就是 open book QA,而 Closed Book QA 则是没有 knowledge source,直接问一个问题看看能不能得到答案。比如直接问你,喜马拉雅山有多高,看机器的参数里面会不会有喜马拉雅山高度的资讯,会不会不需要读任何文章,它就知道喜马拉雅山的高度是 8848 公尺。
而 GPT-3 的表现就是这个样子,蓝色的线是 Zero Shot,绿色的线 One Shot,橙子色的线是 Few Shot。神奇的事情是, Few-shot Learning 居然超过了在 TriviaQA 上 fine-tune 最好的 SOTA model。
所以,在这里,巨大的 model 展现了奇迹。如果是只有 13 个 billion,没有办法超越 SOTA,但约 10 倍大,达到 175 个 billion,可以超越 SOTA。
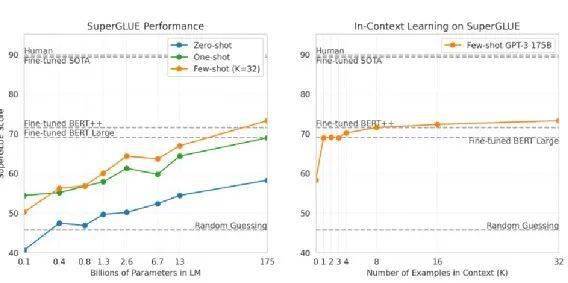
上图是 SuperGDianxiRdkALUE 的部分,同样显示 Zero-shot Learning 、One-shot Learning 、Few-shot Learning 的 performance,谁的参数量越来越多,performance 当然越来越好。如果看最大的 model 的话,它可以超越 Fine-tuned BERT Large model。
右边这张图显示,在做 Few-shot Learning 时,training example 对 performance 所造成的影响。
如果没有给任何 example,也就是 Zero-shot Learning,当然有点差。但随着 example 越来越多,如果只给 1、2、3、4 个,那与 Fine-tuned BERT 的 performance 差不多;如果给到 32 个,就可以超越 Fine-tuned BERT。
GPT-3 是一个 language model,所以它可以生成文本。在 GPT-3 论文中,作者也用 GPT-3 来产生文章。他们给 GPT-3 新闻的标题,然后希望 GPT-3 自己把新闻写出来。
有一个神奇的小发现是:如果不给 GPT-3 任何 example,只给它一则新闻的标题,它会以为这则新闻的标题是推特的一句话,然后接下来它就会自己去回忆想象。
所以在生成文本的时候,GPT-3 不会是 Zero-shot 的,你需要给它几个 example,告诉它有一个标题,下面会接一篇新闻,然后接下来再给他一个标题,希望它可以根据这个标题阐述。
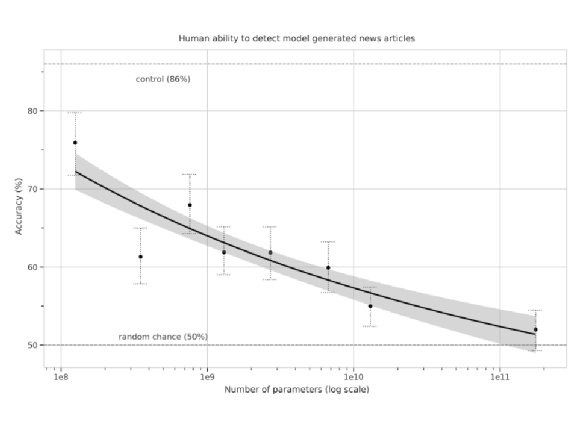
在上图,纵轴代表的是,给人看 GPT-3 产生的新闻与真正的新闻,人DianxiRdkA能不能够判断这篇新闻是真的还是假的。如果人的正确率只有 50%,就代表 GPT-3 产生出来的新闻太过真实,真实到人类没有办法判断它是真的还是假的。我们会发现,随着参数量越来越大,GPT-3 就越来越能骗过人类,最大的 GPT-3 几乎可以骗过人类,人类几乎没有办法分辨 GPT-3 产生出来的新闻跟真实的新闻之间的差异。
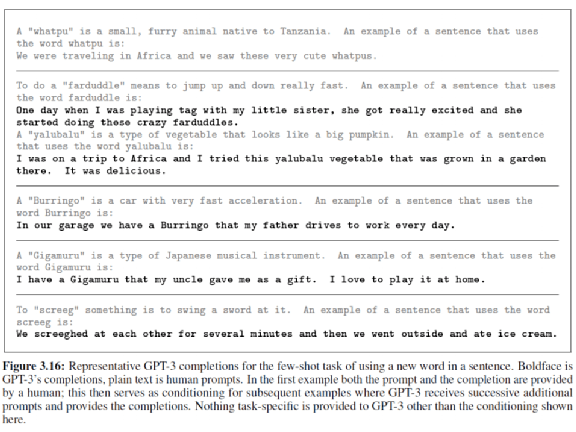
GPT-3 还学会了造句。上图中,浅灰色的文字是人的输入,黑色的文字是 GPT-3 的输出。
你先告诉 GPT-3 要怎么造句,造句是怎么一回事,先给一个词汇的定义。比如,有一个东西叫做 “whatpu”,“whatpu” 是什么,“whatpu” 是一个小的毛茸茸的动物。接下来,以 “whatpu” 为词汇造一个句子,如我们去非洲旅行,我们看到很多可爱的 whatpu。
再给一个胡乱创造的词汇,这个词汇叫做 “Burringo”,是一种跑得很快的车。要 GPT-3 用 “Burringo” 造一个句子,然后 GPT-3 就说在我们家的车库里面有一个 Burringo,我爸爸每天都开 Burringo 上下班。它知道 Burringo 是一个可以开的东西。
再比如,有一个东西叫做 “Gigamuru”,它是日本的乐器。然后让 GPT-3 用 “Gigamuru” 造一个句子.GPT-3 就说,我有一个 Gigamuru,它是我的叔叔给我的礼物,我喜欢在家弹它。它知道 Gigamuru 是一个可以弹的东西。
或者有一个动词 “screeg”,它是挥剑的意思。此时,GPT-3 造出来的句子有些奇怪了,它说我们对彼此 screeghed(它知道要加 ed),即我们彼此挥剑,然后我们就去吃 ice cream,乍一看有点前言不对后语,彼此挥剑感觉应该是敌人,怎么接下来就是吃 ice cream?
但是如果你把 screeg 想成是一种小孩的游戏,它虽然是挥剑,但仍是小孩的一种游戏,小朋友对彼此挥剑之后,接下来去吃冰淇淋,听起来也是合理的。
再来看 GPT-3 能不能学会做数学问题。如何让它做数学问题呢?你就问 “What is 17 minus 14?”,然后给它 “A:”,它自动回答 “3”。它居然会算数学。
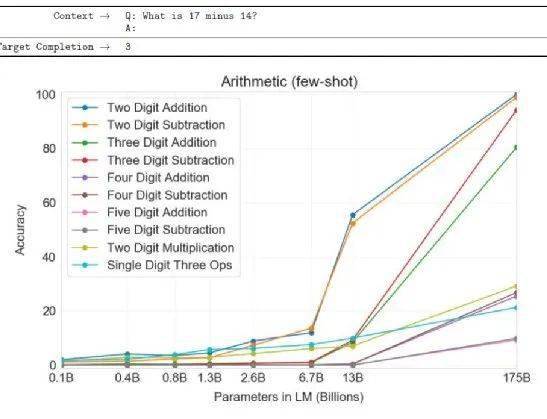
GPT-3 的数学水平可以做到什么程度?上图横轴代表的是使用模型的参数量,纵轴代表的是正确率。如果看这些参数量最多的模型,你会发现,基本上在两位数的加法跟两位数的减法上,可以得到不错的几乎 100% 的正确率。三位数的减法也做得不错,也不知道为什么三位数的加法就稍微差一点。
其他更困难的问题 ——4 位数、5 位数的加法,对它来说就比较困难,但至少它学会了二位数跟三位数的加减法(三位数不算完全学会)。
3GPT-3 的"不神奇"之处
上文我们主要讲了 GPT-3 的神奇。那除了神奇之处以外,也有它不 work 的地方。
从文章里面看,GPT-3 在做 NLI 问题的时候不太行。
所谓 NLI 的问题,即给机器两个句子,要求机器判断这两个句子是矛盾的,还是互相包含,还是中立的关系。
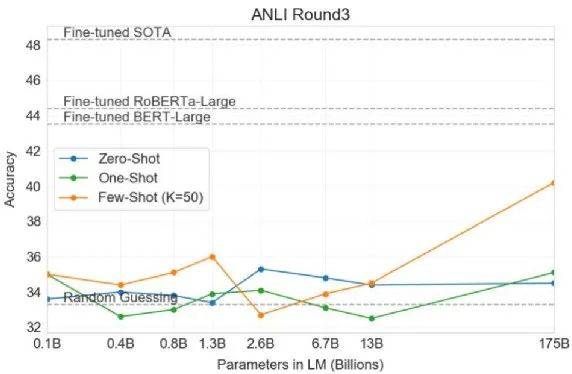
这时会发现,如果使用 GPT-3 的 model,随着模型越来越大,Zero-Shot 跟 One-Shot 基本上表现不佳。
这个灰色的虚线代表的是 Random Guessing。就算是最大的模型,在 Zero-Shot 跟 One-Shot 上,基本都是惨的。只有 Few-Shot Learning,给模型 50 个 example 的时候,看起来是有一些希望,只有在这个状况下显示出一些生命的迹象。
所以, NLI 问题对 GPT-3 来说还是有些困难。
不过,GPT-3 是一个巨大的 language model,它在学习的过程中从来没有看过什么 NLI 问题,只知道 predict 下一个词汇而已。
也许因为在做 NLI 任务的时候,我们放在一起的两个句子很多时候是奇怪和矛盾的句子,两个矛盾的句子放在一起,这种情况本身在人类文字中出现的次数是很少,所以,GPT 系列看到这种接在一起但是矛盾的句子,它会觉得有些困惑。
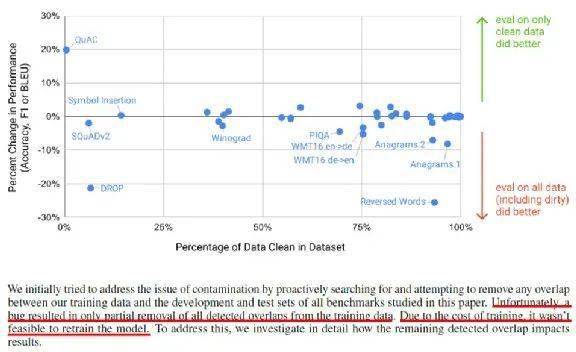
接下来发生了一件有趣的事情。今天我们在训练这种巨大的 model 时,资料往往来自于网络,而网络上爬下来的资料,有可能就包含了我们现在的 testing data。
这件事情是有可能发生的。本来 OpenAI 在做这个实验的时候,他们就想要尽量避免训练数据中杂了 downstream task 的数据。但是他们在写的时候有一个 bug,所以没有成功实现这一点。但是这个 bug 太严重了,无法想象犯了错误的 researcher,他心理压力有多大。
而 “Due to the cost of training,it wasn&apost feasible to retrain the model”,因为 GPT-3 太大了,虽然有一个 bug,但没办法重新训练,只能够就这样了。
虽然没有办法重新训练,那我们就改一下 testing data。所以他们把 downstream task data 分成 clean data 和 dirty data。
clean data,即 GPT-3 在训练的时候,没有接触到的 data。dirty data,即 GPT-3 在训练的时候接触过的 data。如果这些点在这一个水平线之下的话,就代表有看到 dirty data 的 performance 比较好,在水平线之上,就代表给 GPT-3 只看 clean data 的 performance 比较好。也就是说,有一些混杂的资料对它来说也没占到什么便宜。即训练数据有没有被污染,有没有混杂到 downstream task 的数据,对 GPT-3 来说也许影响并没有那么大,所以有一个 bug 就算了。
4超大规模的 model,语言水平究竟如何?
现在,我们有了这么多巨大的 model,它们到底能够了解人类语言到什么样的程度?
有一个比赛叫做 Turing Advice Challenge。它跟 GPT-3 没有什么直接关系了,只是想到现在有这么多巨大的 model,好像都理解人类的语言,那它们可以像人类一样知道怎么使用这些语言吗?而 Turing Advice Challenge 这个比赛,就是要机器去 reddit 上给人类意见。reddit 上会有很多 points,举例来说,有人会给一些感情上的问题。这个 point 是放在 Turing Advice Challengepaper 里面的例子。

有一个人说,她男朋友跟她交往 8 个月,然后有一天她男朋友要给她一个生日礼物,她男朋友就把所有的朋友都找齐,然后秀出了他的背,他的背上有一个他女朋友的脸的刺青,而这个女生会觉得不太行,问怎么办,期待网友给一些建议。
在这个问题上,GPT 建议分手。

对机器而言,要给出像样的建议不太容易。
再举个例子,有人问了一个问题,说他要上高中解剖课,但是他很害怕死掉的动物,那怎么办?有一个人给了一个建议,他建议说你可以越级上报,提问者也觉得这个建议有用。我其实有点不太确定这个建议有没有用,不过至少这个问问题的人觉得是有用的。
那么,机器怎么学会给建议呢?你训练一个 model,这个 model “吃” 下 reddit 上的一个 point,然后它会想办法去模仿 point 下面的回复。
这个比赛提供了 600k 训练数据,也就是 600k 个 reddit 上的 point 及 point 下的回应,而期待机器可以学会正确的回应。
这里以 T5 当作例子,那个时候还没有 GPT-3。T5 答案是这样,你去和你的老师说,你想要一个 project,然后这个 project 可以看到死的动物。
这个回答显然就是不知所云,看起来是合理的句子,看起来像在讲些什么,但实际上没有什么作用。今天,这些巨大的 language model,它往往能得到的表现就是样子。
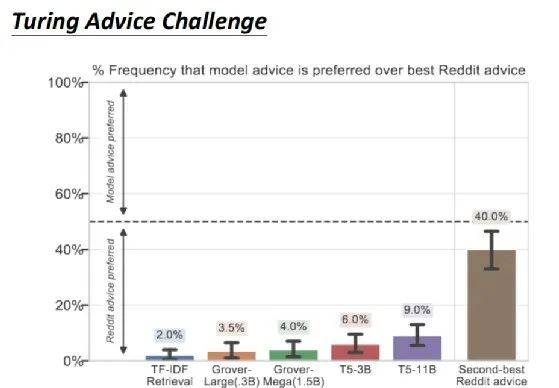
上图是一些真正的实验结果。在 Turing Advice Challenge 中,包括 Grover、T5 等各式各样的模型。结果是,就算是 T5,人们也只有在 9% 的情况下,才觉得 T5 提出来的建议比人提出来的建议有效。
如果现在比较 reddit 上评分第一高的建议与第二高的建议,其实评分第二高的建议还有 40% 的人是觉得有用的,但 T5 只有 9% 的人是觉得有用。
这说明了,用这种巨大的 language model 帮助机器产生的文字,和人类对语言使用的能力仍相差甚远。
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为 星标账号在看”。
收藏
举报