Yelp是美国著名商户点评网站,创立于2004年,囊括各地餐馆、购物中心、酒店、旅游等领域的商户,用户可以在Yelp网站中给商户打分,提交评论,交流购物体验等。在Yelp中搜索一个餐厅或者旅馆,能看到它的简要介绍以及网友的点论,点评者还会给出多少星级的评价,通常点评者都是亲身体验过该商户服务的消费者,评论大多形象细致。
Yelp Reviews
Yelp Reviews是YebUDNDdahJtlp为了学习目的而发布的一个开源数据集。它包含了由数百万用户评论,商业属性和来自多个大都市地区的超过20万张照片。这是一个常用的全球NLP挑战数据集,包含5,200,000条评论,174,000条商业属性。 数据集下载地址为:
https://www.yelp.com/dataset/download
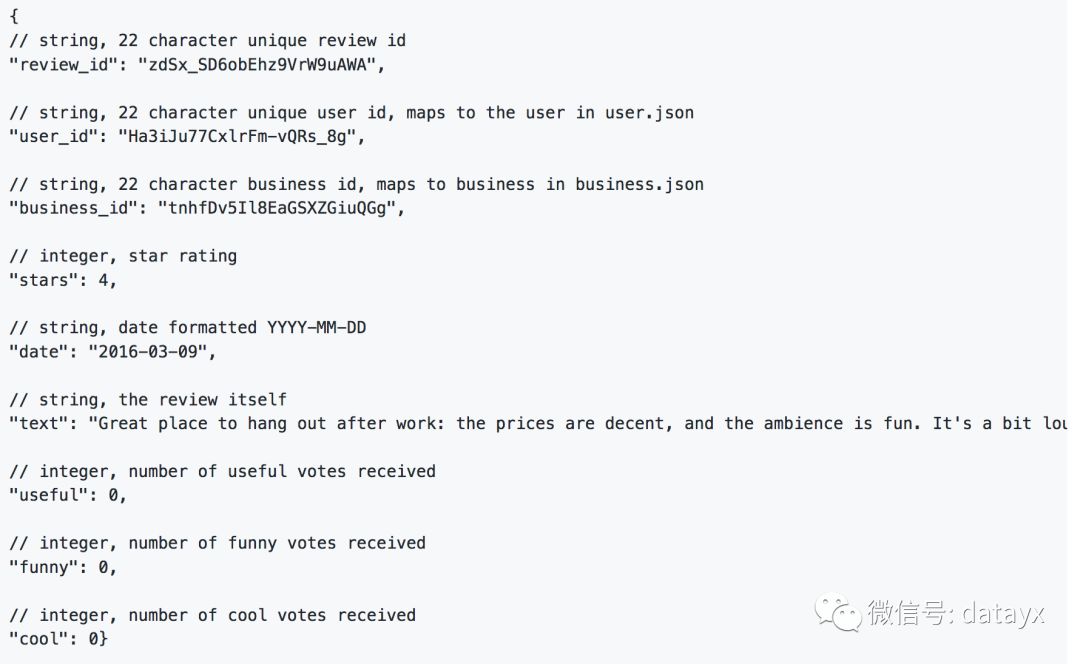
Yelp Reviews格式分为JSON和SQL两种,以JSON格式为例,其中最重要的review.json,包含评论数据,格式如下:
数据清洗
Yelp Reviews文件格式为JSON和SQL,使用起来并不是十分方便。专门有个开源项目用于解析该JSON文件:
https://github.com/Yelp/dataset-examples
该项目可以将Yelp Reviews的Yelp Reviews转换成CSV格式,便于进一步处理,该项目的安装非常简便,同步完项目后直接安装即可。
git clone https://github.com/Yelp/dataset-examplespython setup.py install
假如需要把review.json转换成CSV格式,命令如下:
python json_to_csv_converter.py /dataset/yelp/dataset/review.json//www.58yuanyou.com
命令执行完以后,就会在review.json相同目录下生成对应的CSV文件review.csv。查看该CSV文件的表头,内容如下,其中最重要的两个字段就是text和stars,分别代表评语和打分。
#CSV格式表头内容:#funny,user_id,review_id,text,business_id,stars,date,useful,cool
使用pandas读取该CSV文件,开发阶段可以指定仅读取前10000行。
#开发阶段www.58yuanyou.com读取前10000行df = pd.read_csv(filename,sep=',',header=0,nrows=10000)
pandas的可以配置的参数非常多,其中比较重要的几个含义如下:
- sep : str, default ‘,’。指定分隔符。
- header: int or list of ints, default ‘infer’。指定行数用来作为列名,数据开始行数。如果文件中没有列名,设置为原由网None。设置为0则认为第0行是列名
- nrows : int, default None 需要读取的行数(从文件头开始算起)
- skiprows : list-like or integer, default None。需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
- skip_blank_lines : boolean, default True。如果为True,则跳过空行;否则记为NaN
按照列名直接获取数据,读取评论内容和打分结果,使用list转换成list对象。
text=list(df['text'])stars=list(df['stars'])
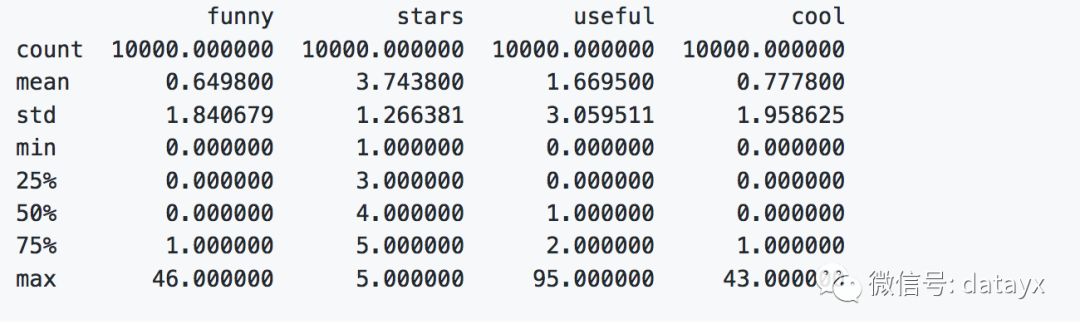
查看打分结果的分布。
#显示各个评分的个数print df.describe()
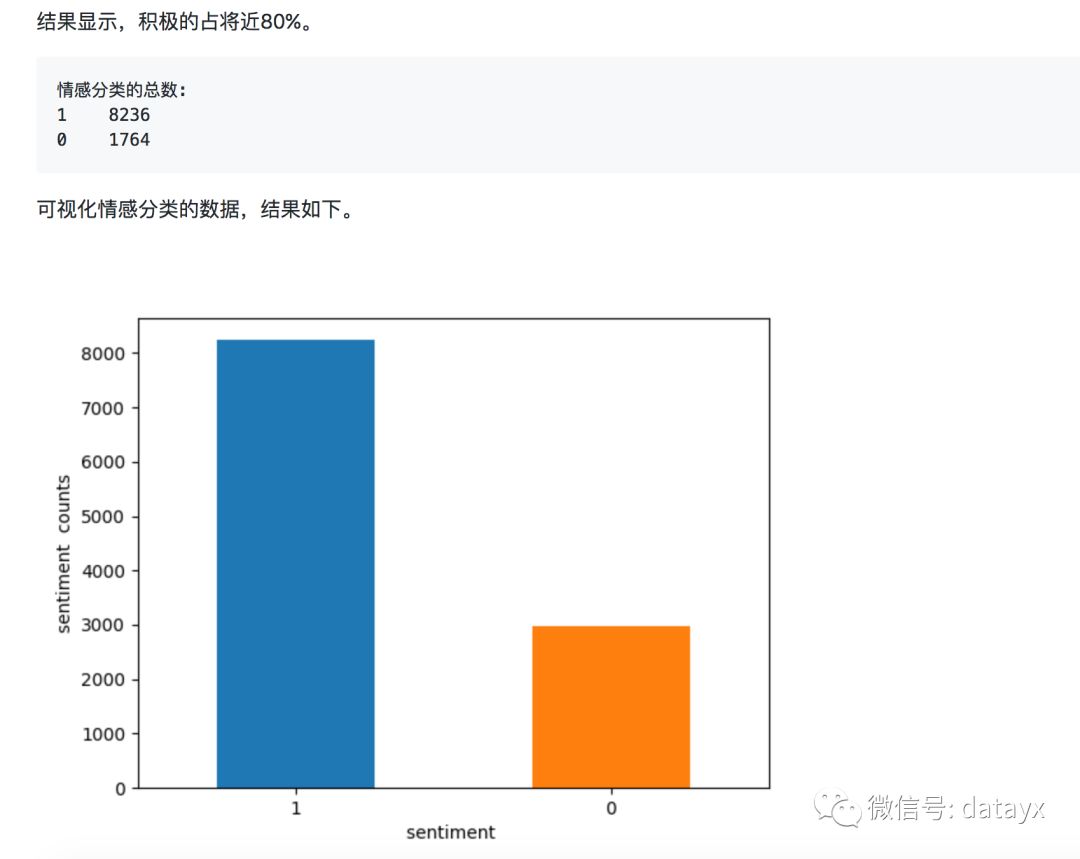
分布结果如下,一共有10000个评分,最高分5分,最低1分,平均得分为3.74。
pandas下面分析数据的分布非常方便,而且可以支持可视化。以分析stars评分的分布为例,首先按照stars评分统计各个评分的个数。
#绘图plt.figure()count_classes=pd.value_counts(df['stars'],sort=True)
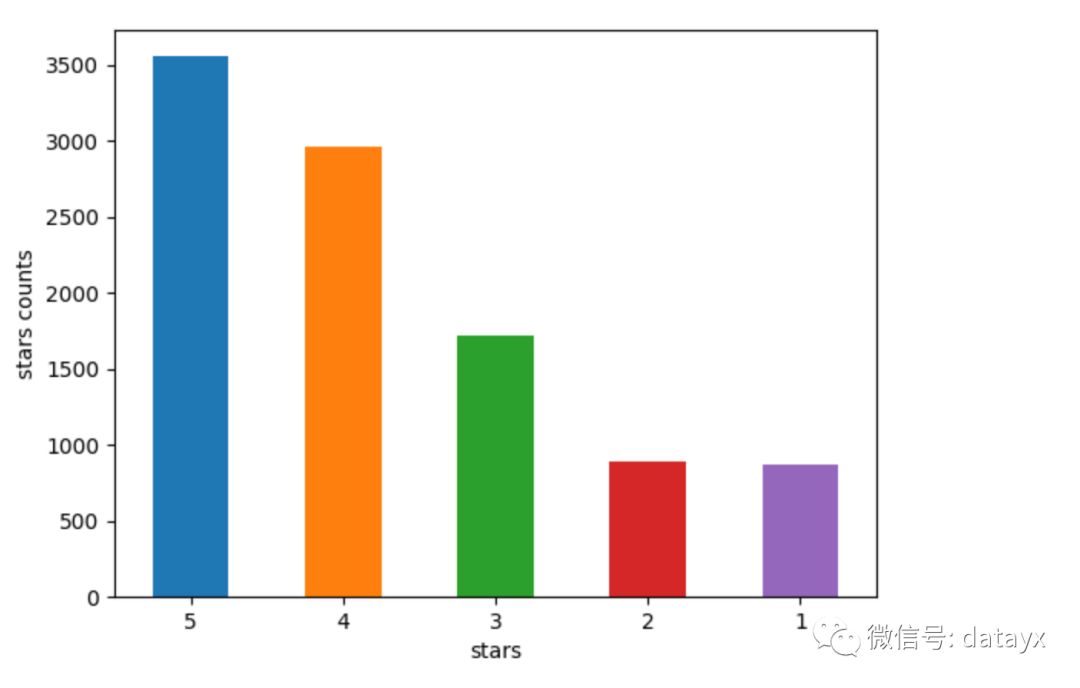
然后使用pandas的内置函数进行绘图,横轴是stars评分,纵轴是对应的计数。
print "各个star的总数:"print count_classescount_classes.plot(kind='bar',rot=0)plt.xlabel('stars')plt.ylabel('stars counts')plt.savefig("yelp_stars.png")
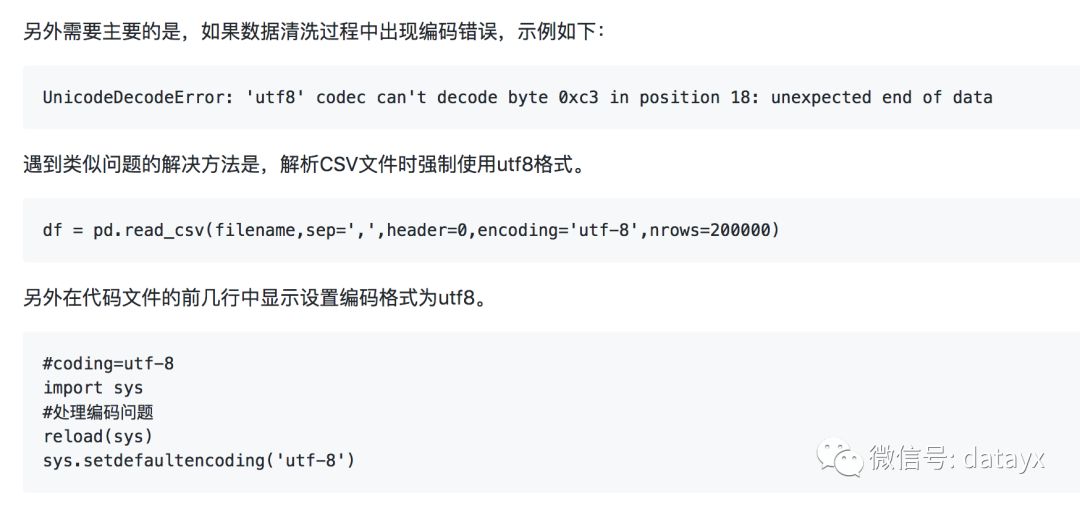
在Mac系统下运行可能会有如下报错。
RuntimeError: Python is not installed as a framework. The Mac OS X backend will not be able to function correctly if Python is not installed as a framework. See the Python documentation for more information on installing Python as a framework on Mac OS X. Please either reinstall Python as a framework, or try one of the other backends. If you are using (Ana)Conda please install python.app and replace the use of ‘python‘ with ‘pythonw‘. See ‘Working with Matplotlib on OSX‘ in the Matplotlib FAQ for more information.
处理方式为:
- 打开终端,输入cd ~/.matplotlib
- 新建文件vi matplotlibrc
- 文件中添加内容 backend: TkAgg
再次运行程序,得到可视化的图表,可以发现大多数人倾向打4-5分。

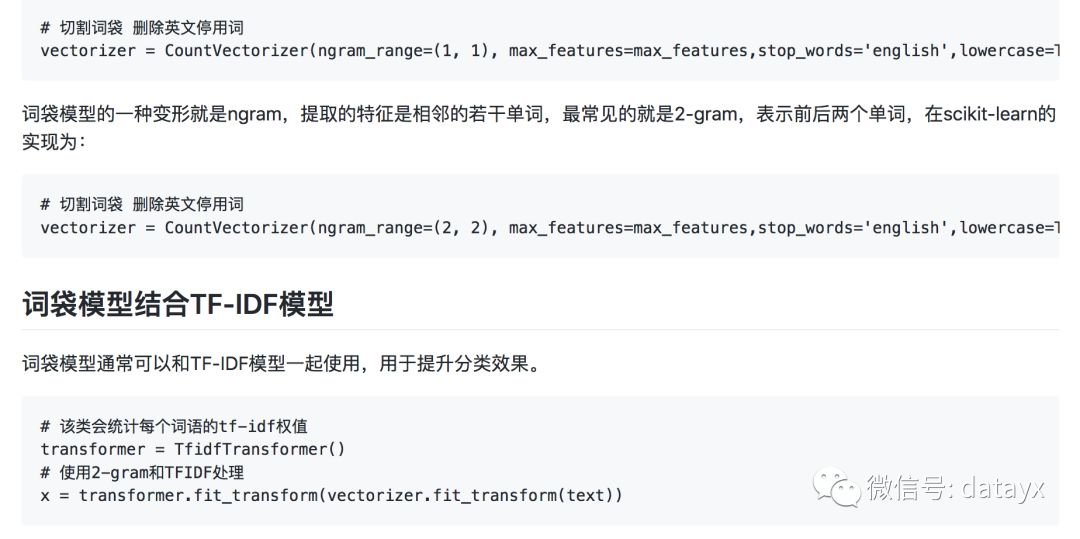
特征提取词袋模型
最简单的一种特征提取方式就是词袋模型,scikit-learn下有完整的封装。
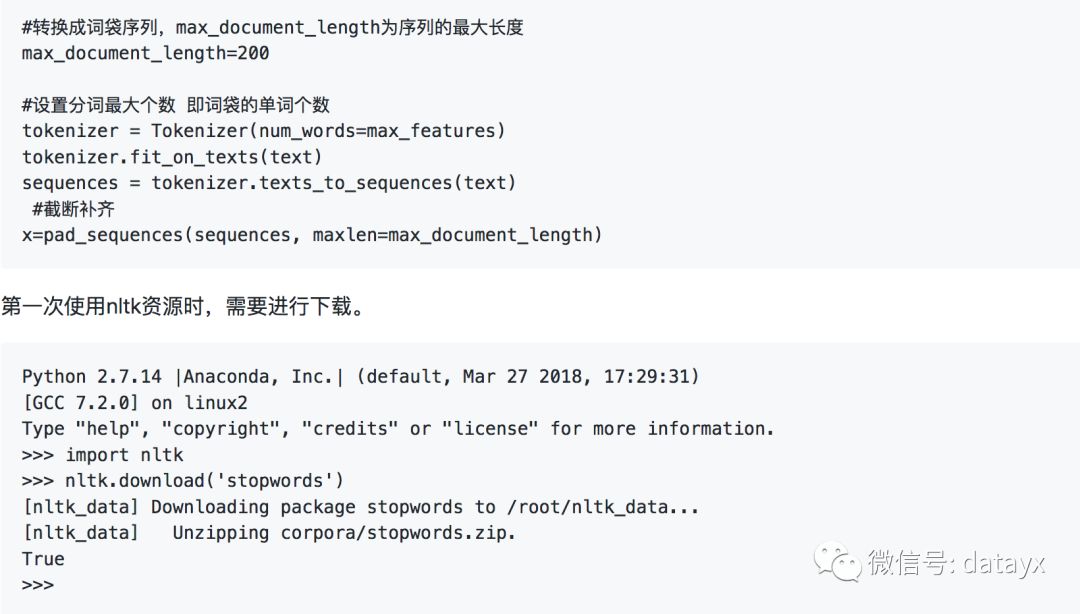
词袋序列模型
词袋序列模型是在词袋模型的基础上发展而来的,相对于词袋模型,词袋序列模型可以反映出单词在句子中的前后关系。keras中通过Tokenizer类实现了词袋序列模型,这个类用来对文本中的词进行统计计数,生成文档词典,以支持基于词典位序生成文本的向量表示,创建该类时,需要设置词典的最大值。

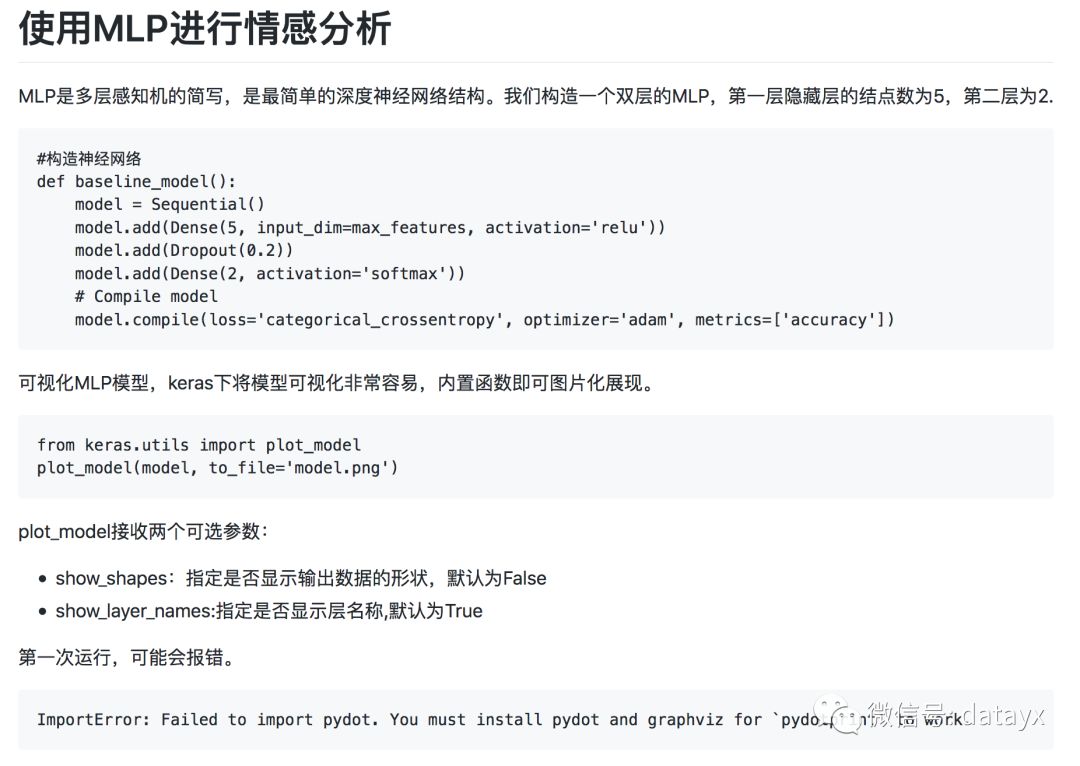
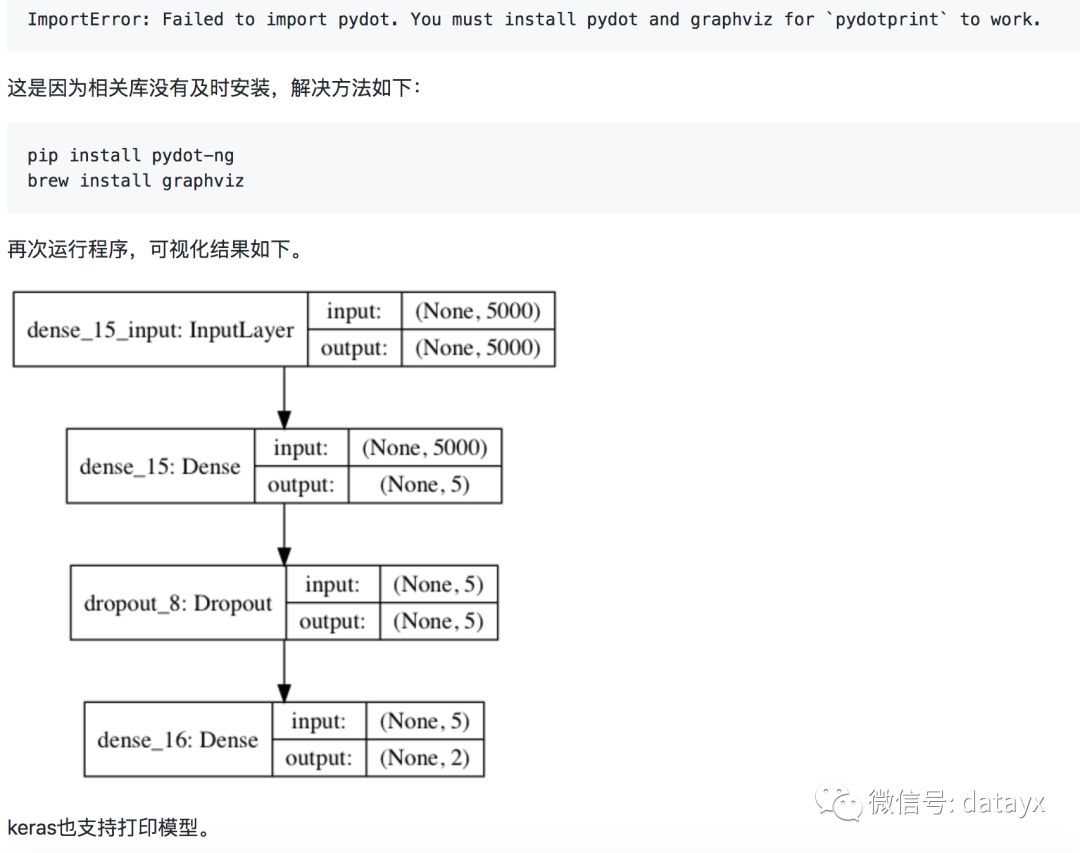


使用LSTM进行情感分析
LSTM特别适合处理具有序列化数据,并且可以很好的自动化提炼序列前后的特征关系。当我们把Yelp数据集转换成词袋序列后,就可以尝试使用LSTM来进行处理。我们构造一个简单的LSTM结构,首先通过一个Embedding层进行降维成为128位的向量,然后使用一个核数为128的LSTM进行处理。为了防止过拟合,LSTM层和全连接层之间随机丢失20%的数据进行训练。

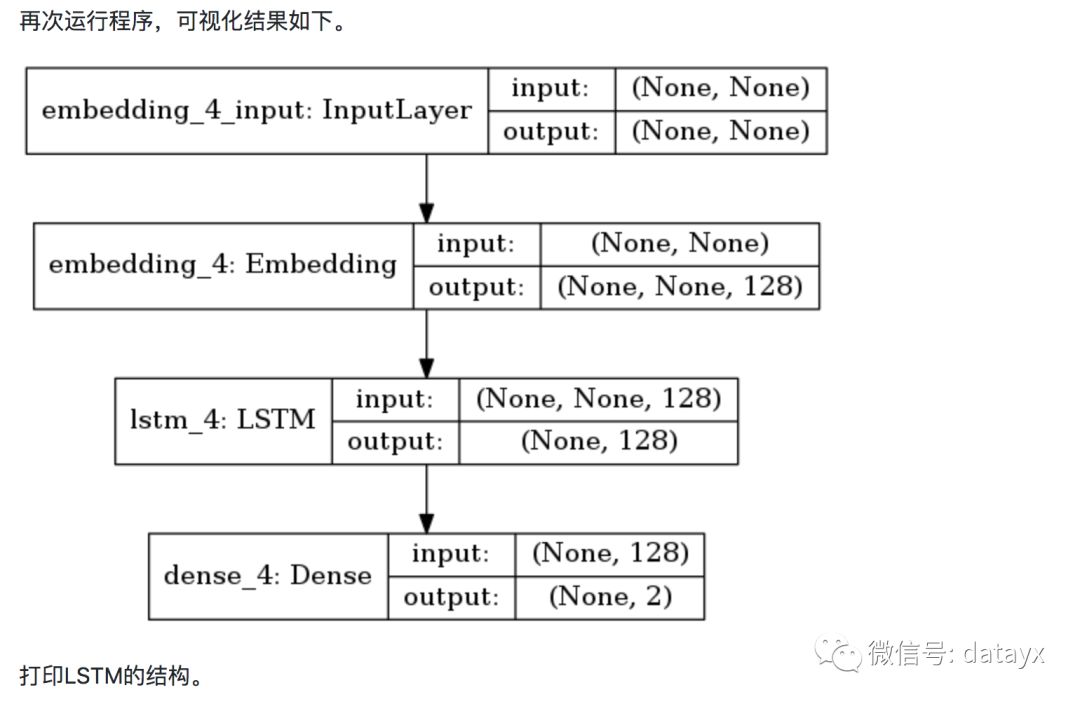

使用CNN进行情感分析
近几年使用CNN处理文本分类问题也逐渐成为主流。我们尝试使用简单的CNN结构来处理Yelp的分类问题。首先通过一个Embedding层进行降维成为50位的向量,然后使用一个核数为250,步长为1的一维CNN层进行处理,接着连接一个池化层。为了防止过拟合,CNN层和全连接层之间随机丢失20%的数据进行训练。
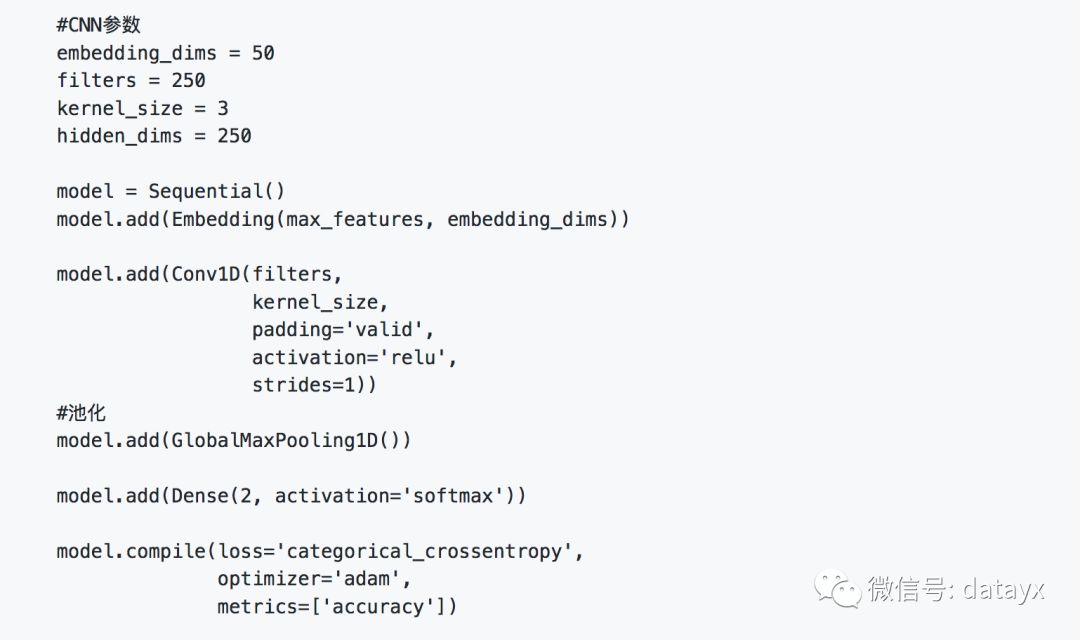
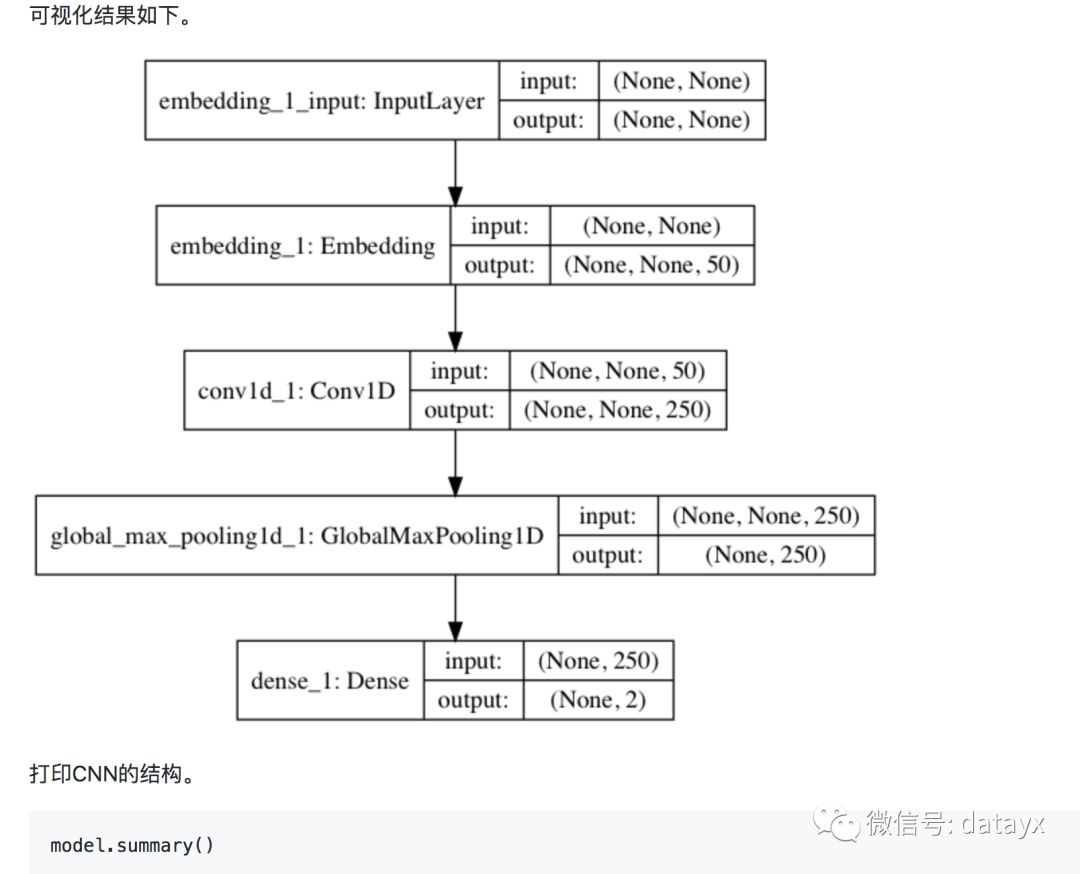
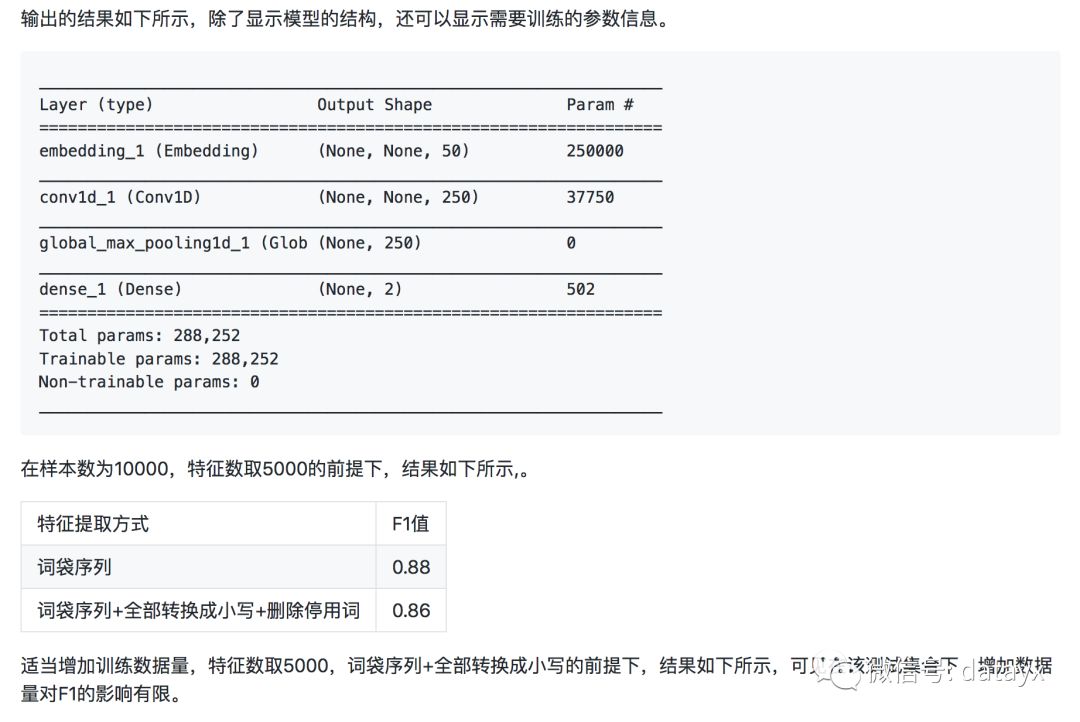
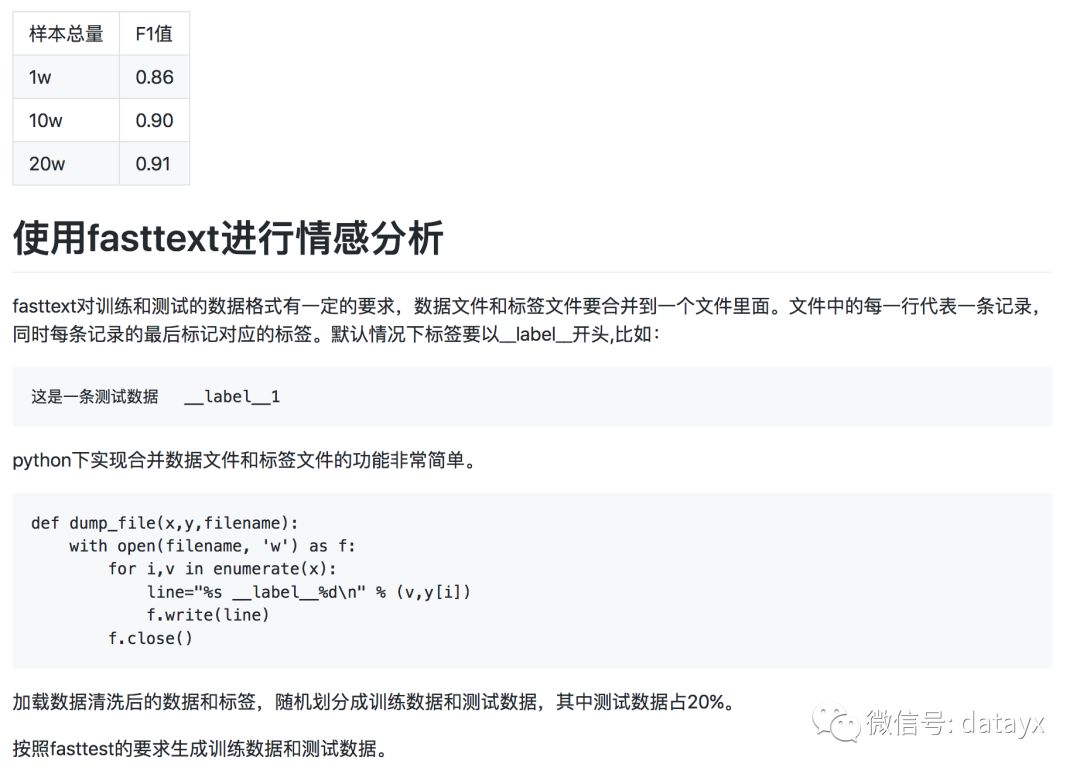
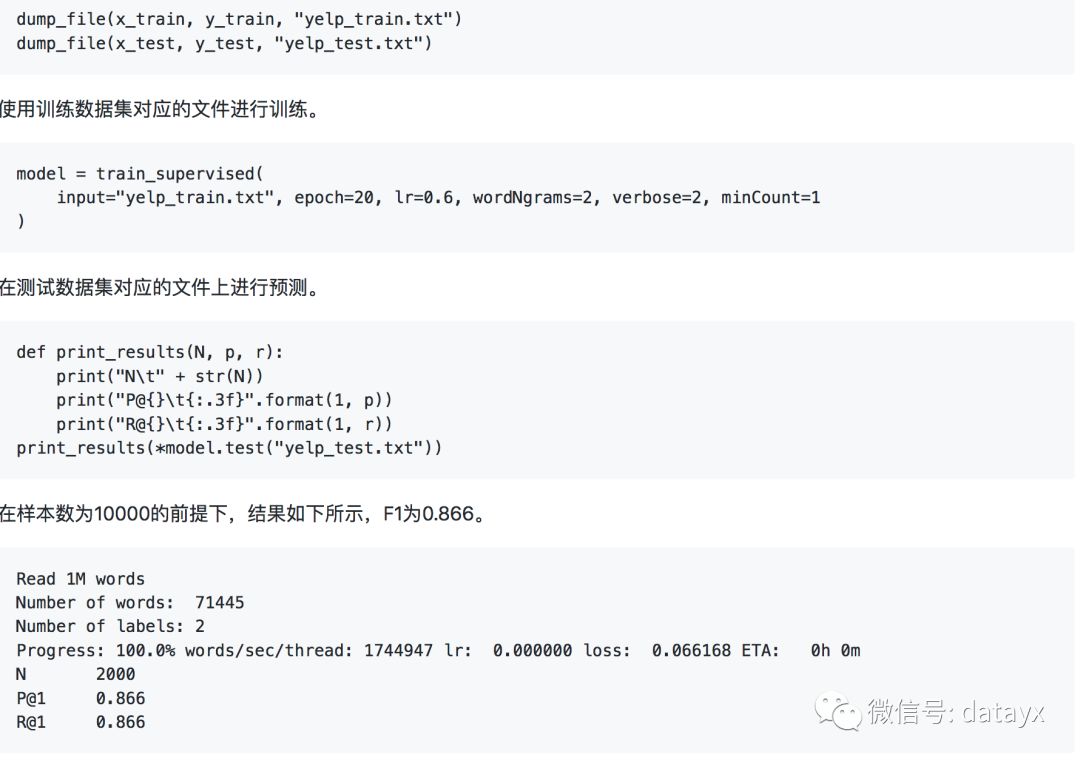

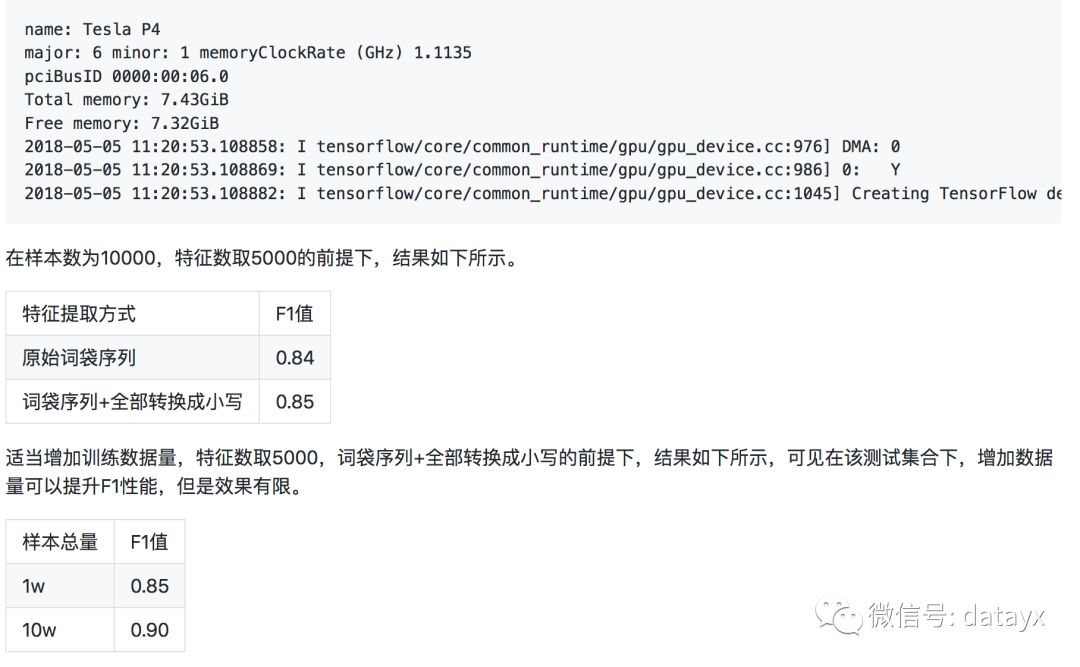
在深度学习出现之前,SVM和朴素贝叶斯经常用于文本分类领域,我们以SVM为例。实例化SVM分类器,并使用5折验证法,考核F1值。

https//www.58yuanyou.com://github.com/duoergun0729/nlp/blob/master/%E9%A2%84%E6%B5%8BYelp%E7%BE%8E%E9%A3%9F%E8%AF%84%E5%88%86.md