对于DB2数据库,很多人并不能理解执行计划所表达的含义,在此推荐一篇社区专家的文章,通过实际案例详细探讨DB2数据库中执行计划的各个要点。文后附上IBM技术团队出品的DB2 实用技巧8招,相信对大家会很有帮助。
《DB2 执行计划浅析》 作者:洪烨,专注于并擅长数据库领域。主要负责哈尔滨银行的服务器、存储、数据库的管理与维护工作。
个人主页:http://www.aixchina.net/home/space.php?p=blog&uid=52344
在数据库调优过程中,SQL语句往往是导致性能问题的主要原因,而执行计划则是解释SQL语句执行过程的语言,只有充分读懂执行计划才能在数据库性能优化中做到游刃有余。
常见的关系型数据库中,虽然执行计划的表示方法各自不同,但执行原理却大同小异。在我看来,SQL语句的执行过程中总共包含两个关键环节:

只要掌握这两个关键环节,我们就可以迅速识别SQL语句在当前数据库中的执行逻辑,发现执行计划中存在的问题及隐患。由于不同数据库之间对于执行计划的表示方法各不相同。对于DB2数据库,很多人并不能理解执行计划所表达的含义,接下来我们就通过实际案例详细探讨DB2数据库中执行计划的各个要点。
1
读取数据的方式
谈到读取数据就离不开数据库中的物理对象:表及索引。因此谈到数据读取的方式,只需理解表扫描及索引扫描,就能基本把握数据的来源。
2
全表扫描
在DB2 LUW中可以通过四种方式获原由网取语句的执行计划(db2expln工具),虽然工具不同,但展示的内容基本相似,最大的区别就是详细程度。详细程度由大到小排序分别是:。为了方便展示,我们在这里只讨论通过db2expln所展示的执行计划信息。首先我们来看一个db2expln抓取的完整的执行计划。
db2expln展示的信息总共分为三部分,分别是当前SQL 语句,执行计划详细信息及执行计划图示(需添加-g参数才能展示),第一部分是当前采集执行计划的语句(见图1-1):
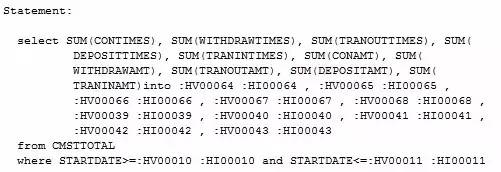
这部分内容基本一目了然,需要注意的就是里面:HV … :HI… 的信息是DB2将参数改写的信息(基本可以忽略)。
接下来我们来看最关键的部分,执行计划的详细信息(见图1-2):

这部分首先包括当前环境的字符集(codepage),下面是根据统计信息评估出的成本及返回行数。在这个例子中执行成本为124470,返回行数为1行。从第6行开始的位置内容比较重要,我们采取逐行解释:


第三部分为执行计划图,我们可以通过执行计划图快速直接地看出SQL语句的执行过程,执行计划图的阅读顺序是从下往上,从左往右,按照编号从大到小的顺序进行阅读。比如在这个例子中,首先看第三步,显示对表进行表扫描操作(TBSCAN),然后对扫描的结果进行group by操作并将最终结果返回,这条SQL语句就执行完毕了。

3
索引扫描
接下来来看个索引扫描的例子,为了快速理解这个执行计划,我们直接先看执行计划图,可以看到这个SQL语句首先读取索引,获取RID后到表里获取其他数据,进行group by后将结果返回。

其他部分和上一个例子差不多,就不一一详细介绍了,主要看索引扫描的相关细节。从下面的信息可以看出用到的索引中包含4个字段,但这条SQL只用到了一个字段。其他三个字段都没用使用。如果该表上有其他索引包含这条SQL所使用的更多的字段时,这个索引肯定不是最佳选择。

数据读取的方式还有更多的细节,这里暂时不一一讨论了,但不论对数据采用何种方式读取,最核心的内容还是数据从哪里读取,简单来说就是有没有更好的索引可以替代当前的扫描策略,所以,当我们对SQL语句进行优化时,第一步就是需要考虑当前的读取方式是否足够有效。
4
表连接的方式
接下来我们来谈表之间的连接,写过SQL的童鞋都知道,写SQL时Join方式可以有很多种情况:inner join,left join,right join,full join等,还包括一些子查询,比如exist 或者In等方式。对于星型查询,DB2 10以后还支持ZZJOIN。
5
Nest Loop(NLJOIN)
Nest Loop是最简单的一种连接方式,数据库会根据表中的记录数选择内表及外表,在定义内外表后,首先会对外表进行全表扫描,然后重复扫描内表并与外表中的每一条记录进行匹配,最终返回程序所需的结果集。

因此NLJOIN的总成本大约为外表扫描的成本+外表返回的行数内表扫描的成本。NLJOIN作为使用场景最多的连接方式,当外表匹配行数较少或内外表行数差距较大zNiAhyqGMR时效率较高,但也正因为NLJOIN的运行方式,也经常会发生性能隐患.
6
Merge Join(MSJOIN)
合并连接是为了解决Nest Loop中存在的一些问题所采用的一种连接方式,MSJOIN会将需要连接的两张表进行排序,并将排序后的结果集按照交叉方式匹配,最终返回连接后的结果。
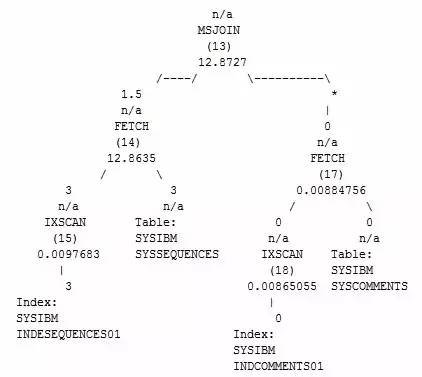
MSJOIN的总成本大约为单次外表扫描的成本+单次内表扫描的成本+排序成本。MSJOIN常见的场景通常是SQL需要返回排序结果,亦或者主外表都比较大的情况,此外MSJOIN原由网只能应用于SQL语句中包含唯一连接谓词的情况,当主外表数量级都比较大,且连接谓词上都存在索引时,MSJOIN的效率较高(避免了排序成本),通常MSJOIN比较稳定,即使统计信息估算错误,也不会导致执行效率出现较大的偏差。
7
Hash join(HSJOIN)
HSJOIN是一种比较高级的连接方式,进行连接前首先会将外表根据连接谓词进行哈希产生哈希表,然后将哈希表与内表进行连接并返回结果。与MSJOIN类似,HSJOIN也只对内外表分别进行一次扫描,同时HSJOIN也支持多连接谓词。在两张大表通过多连接谓词进行连接时效率很高。
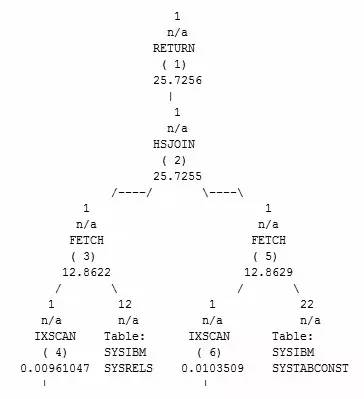
HSJOIN的扫描成本约为内表扫描成本+外表扫描成本。但需要注意的是,生成的哈希表会存放在排序堆中,一旦排序堆内存溢出,会额外产生大量的物理IO,这点需要特别注意。
8
半连接(semi-join)
半连接属于一种比较奇怪的连接方式,在很多资料里并没有将其划分到连接方式中,因为有的时候,从执行计划中根本看不到连接操作符,比如下面这个SQL:
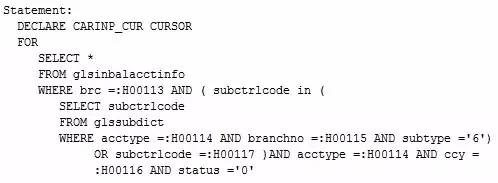
这是一个典型的子查询,我们可以从SQL语句中猜出大概逻辑,首先会读取子查询中的表,然后根据返回的内容与外部表进行匹配并返回结果。但从执行计划图中并不能看到任何关于连接的信息。

执行计划图中并没有显示任何join的信息,只是多个对象进行了fetch,但从文字描述中可以看到更详细的内容。
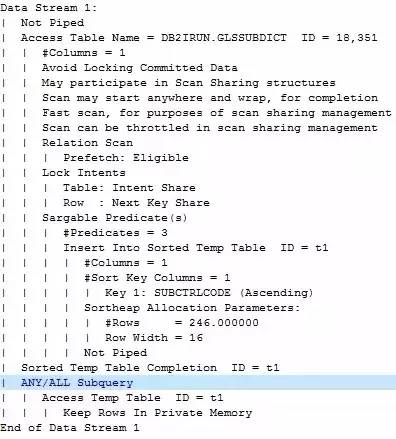
数据流1首先会对内部表进行全表扫描(ANY/ALLSubquery),读取后的结果与外部表进行匹配,匹配到结果后不继续扫描立刻返回结果(EXISTS Subquery)。
9
多表间的连接顺序选择
不论在同一条SQL语句中包含了多少张表连接,在同一时刻只有两张表进行连接,但多表间的连接顺序也是决定性能的主要原因。数据库对于表的顺序的选择,往往根据两个表之间连接后得出的行数进行排序,如果统计信息与实际情况偏差较大,有可能会导致由于连接顺序不当而导致的性能问题。
10
总结
通过对执行计划的解析,我们讲解了SQL执行过程中对于性能影响较大的各个要点,但如何在生产上保持SQL的高效稳定,还需对执行计划进行更深入的理解。 再解答一些常见的疑问:
Q & A
Q1:在查询时,有一个驱动表,通常是from后的第一个表,后面一堆左连接右连接,这个驱动表如何选择?对性能有影响么?自己人为该顺序不会影响执行计划?
A1:在数据库中,会根据当前表的情况进行内外表的选择,SQL语句中的写法只能从一定程度上决定连接次序,但不会做连接中内外表的决策。
举个例子,selectfrom a,(selectfrom b,c where b.id=c.id)where……,比如这个SQL,在写法中指明了需要先将b c表连接,再与a表连接,但在连接时候的方式以及连接时候内表外表的选择,都由数据库决定。
-----------
Q2:关于连接方式的选择,是由连接的两个表和连接的字段是否排序决定的?
A2:这个不绝对,但是会作为选择的因素之一。
-----------
Q4:访问某表的access plan改变了,统计信息没变,是什么情况?这是优化器自动调整了吗?可是优化器根据统计信息生成访问计划,按道理应该是不会变的啊?
A4:执行计划的选择会根据数据库参数,统计信息作为参考,但在编译过程中数据库还会收集一些物理信息。比如数据的物理分布可能会对扫描的方式产生影响。
-----------
Q5:这个物理信息是什么,是表空间信息吗?
A5:表在物理中存放的情况。
-----------
Q6:有什么手段跟踪一个SQL完整的执行过程,包括你说的动态收集物理信息?
A6:可以抓trace或者stack。db2trc,和db2pd –stack。
-----------
Q7:老师,db2的优化器是对越复杂的sql支持的越好吗?有这个说法吗?
A7:db2的优化器对复杂SQL的支持在关系型数据库里应该是最好的,但是对于联机交易系统来讲,我觉得SQL的稳定性比较重要。但复杂SQL牵扯到的变化因素太多,任何一个表的统计信息改变都有可能导致SQL性能下降,所以在联机交易系统不太推荐写复杂SQL。
-----------
Q8:那我们写sql时该怎么注意呢?NL join类似笛卡尔集,时间复杂度最高,其次是merge。我觉得从sql上避免不了,因为选择了那个列,就基本确定了连接类型。
A8:在编写SQL的时候很难决定用什么连接方式,但有些需要注意的地方,比如避免多张大表连接,这些在开发过程中还是可以办到的。
-----------
Q9:hash连接,如果探测表很大,内建表很小www.58yuanyou.com,hash的成本显示很高,因为探测表做了表扫描,没有用到索引,这种如何优化,只能减少探测表的返回集吗?
A9:可以在探测表上创建适当索引。
-----------
Q10:对表做完统计更新后需要做rbind吗?
A10:这个需要取决于你的应用是静态SQL还是动态SQL。静态SQL的话执行计划在bind的时候保持在数据库中,统计信息更新后建议rebind,但动态的就没必要了。
-----------
Q11:通常谓词出现在索引的第一个字段应该就是有效索引,可有时候这个索引存在,但是个复合索引,跑db2advis时却建议在这个谓词上创建新的单一的索引,为什么数据库不用现有的复合?
A11:复合索引并不一定高效,这个需要根据数据分布来判断,如果单一索引的Clusterration非常好(也就是和表存放的顺序匹配度非常高),这样可以用到大量预取操作,性能会比同步读好很多。
-----------
Q12:嵌入式C、C++、COBOL的包BND(包括静态SQL),要绑, 用户SP也建议绑定吧?
A12:UDI的成本其实很大程度上和表设计有关。比如在做DML语句的时候发生行溢出和页重组,带来的消耗远大于插入索引。相关信息可以看db2pd -tcb或者snapshot for table。
-----------
Q13:请问一下对于表压缩有什么建议?比如要做大表的压缩,有没有一些量化指标供参考,因为有一些表开了压缩批次插入较多记录时候影延长了批次1/3的时间。
A13:对于压缩,需要分析当前数据库的瓶颈在哪。压缩是以cpu为代价降低磁盘io,如果瓶颈在磁盘io上,肯定会有帮助,但如果瓶颈在cpu上只会雪上加霜。
-----------
Q14:调整APPENDON呢?有没有量化的一些指标?
A14:这个不是很好量化。对于磁盘io瓶颈,可以先从索引,语句甚至表设计入手。如果都已经调整到很好了但还是存在iO瓶颈,同时CPU使用率又比较低(30-40以下)。可以考虑压缩。
(本文由作者授权发布)
作者:CoreDB / 华南IBM大数据支持团队
1. 意外删除日志文件
所有的关系型数据库都依赖于日志文件保证数据库的一致性和完整性。DB2的日志文件分为活动日志文件和归档日志文件。当意外删除活动日志文件时,很可能会造成数据库宕机并且无法再激活。
如果你真的误删了活动日志文件并且数据库服务器还没有宕机,那就赶紧用export命令将重要的数据先导出来;
如果不幸数据库已经down机了,安全的做法自然是找到以前做的备份并进行恢复;
如果你还有IBM的售后服务,可以让IBM的售后帮你重置控制文件的位置以跳过数据库启动时所需的前滚和回滚;
最不济的做法就是你自己用db2dart /ddel将重要的数据dart出来。
但不管使用哪种方式进行恢复,丢失了日志文件基本不可能恢复到最近的时间点,所以还是会丢失部分的数据
2. 实例出现意外情况
DB2的实例和数据库是一个松耦合的关系,你强行把实例删除了,但是数据库里存储的内容是不受影响的。
如果你碰到以前一个正常运行的实例不能启动了,你又不想花原由网时间去研究是什么问题导致的(很可能是某人修改了DB2实例某个文件的属性),那你可以先试试使用db2iupdt –k 命令进行修复。
如果修复不成功,那就将db2set –all ,db2 get dbm cfg,db2 list db directory的内容保存下来后,用db2icrt命令重建实例。在重建实例后根据保存的db2set、dbm信息进行重新设置,然后使用catalog db dbname on dbdir就可以重新编目数据库供正常使用。那如果你重建实例前忘了保存实例下数据库的位置,那就你find / -name"sqldbdir",输出的NODEXXXX目录的上一层就是你实例的名称,再上一层就是数据库的创建位置。
举个例子来说,在你的输出中有/home/abc/forx/NODE0000/sqldbdir一行,那你首先需要确认一下forx是不是你原来实例的名称,而/home/abc则是数据库的路径,你用catalog db xxx on /home/abc就可以将数据库重新编目
3. 修改了系统时间
DB2在创建数据库的时会将创建数据库时的时间戳写入到系统表中,数据库内部函数同样也会标识这个时间戳。因此如果你将操作系统的时间调整到创建数据库的时间前,那就会发现在调用一些函数,例如substr时数据库会报SQL0440错误。
你能做的只能是将操作系统的时间调整到创建数据库那个时间点后。
再或者这个调整确实无法避免,IBM Level 2的工程师有个fixfuns的工具可以帮助来修正这个问题,但这个并不是我们建议的动作,或者我们还是应该想清楚为什么会有这种修改系统时间的操作,应该如何来避免这种操作
4. load文件格式的问题
我们在使用load命令将文本数据加载到DB2数据库时,通常会碰到以下几个问题:
一个问题是数据加载进数据库是乱码;
第二个问题是文本文件中的字符串数据存在着回车换行导致加载失败;
第三个问题是表的定义有identity字段导致加载失败。
对于这几个问题,其实load命令都提供了对应的解决方法:
对于第一个问题,首先我们要确认需加载的文本文件到底是用的哪种编码方式,然后使用modified by codepage=xxxx (xxxx为文本文件编码的代码页)进行加载;
而第二个问题,我们则可以通过使用 modified by delprioritychar来屏蔽换行符;
第三个问题,我们可以通过modified by identityoverride或是modified by identityignore来导入存在identity类型的数据
5. 数据库改名
一般情况来说我们并不需要真的对DB2的数据库改名,如果你需要能用另一个名称来访问数据库,那你大可以用catalog db oldname as newxx 来增加一个编目名称用于访问。如果你真有有必要修改数据库的名称,可以编辑类似的一个文件:
DB_NAME=oldname,newname
DB_PATH=C:
INSTANCE=DB2
然后使用db2relocatedb –f 文件名来修改数据库的名称。其实db2relocatedb除了可以修改数据库的名称,还可以用于修改实例的位置,数据文件的路径等
6. 数据库在线备份期间load的效率很低
实际上DB2的信息中心对这个问题有非常明确的解释。DB2的在线备份与一些实用命令(包括create index,load,reorg等)是不兼容的。备份程序会在正在进行备份的表空间上放置一个online backup (OLB) 类型的锁,而load命令必须等这个锁被释放后才能继续进行,而我们通常没有意识到这个锁的存在是由于load命令不会因为在一直等这个锁被释放而超时(也就是说即使你设置了DB2的locktimeout参数,load操作也不会超时失败)。因此我们看到的load效率很低,实际是load动作被在线备份挂起了,只有当load表所在的表空间备份完成后,load动作才能继续
7. 修改数据库的backup pending模式
我们都很清楚,当需要将数据库的日志模式由循环日志改为归档日志模式时,除了修改logarchmeth1参数外,还要对数据库进行一个脱机的备份后才能再次连接数据库。如果数据库很大,即使做一个空的备份至/dev/null,对数据库所有的页面进行一个扫描也要耗费不少时间,如果不想做这个备份动作,可以使用db2dart命令来取消数据库的这个backup pending的状态:
db2dart <database> /chst /what DBBP OFF
8. AIX平台数据库进程绑定CPU
一些NUMA架构的大型服务器有很多的CPU,这些CPU可能会分布在多个的CEC柜子中。为了避免进程在跨CEC柜子所产生的性能损耗,在一些的应用环境中,我们可以将DB2的进程绑定到指定的CPU中(通常都是在一个CEC柜子中),DB2提供了一个注册变量DB2_RESOURCE_POLICY来辅助我们来完成这个工作
A、通过lssrad –av 确定每个CEC的CPU分布情况
B、执行chuser capabilities= CAP_BYPASS_RAC_VMM,CAP_PROPAGATE,CAP_NUMA_ATTACH db2inst1 赋予DB2实例用户相应的操作系统权限
C、创建db2资源集:mkrset –c 0-63 test/db2
D、通过使用db2set 命令指定DB2_RESOURCE_POLICY使用资源的配置文件(将下面的文本存成一个文件,DB2_RESOURCE_POLICY指向的是该文件所在位置),重启数据库使之生效
<RESOURCE_POLICY>
<GLOBAL_RESOURCE_POLICY>
<METHOD>RSET</METHOD>
<RESOURCE_BINDING>
<RESOURCE>test/db2</RESOURCE>
</RESOURCE_BINDING>
</GLOBAL_RESOURCE_POLICY>
</RESOURCE_POLICY>
E、 通过db2pd –edus 可以看到,采用绑定方式后的输出在最后一列有一个绑定的标志表明CPU资源的绑定成功